1.XML概述
1.1 什么是XML
XML是指可扩展标记语言(eXtensible Markup Language),它是一种标记语言,很类似HTML。
它被设计的宗旨是传输数据,而非显示数据。
XML标签没有被预定义,需要用户自行定义标签。XML被设计为具有自我描述性。
XML技术是W3C组织(World Wide Web Consortium万维网联盟)发布的,目前遵循的是W3C组织于2000年发布的XML1.0规范。
XML被广泛认为是继Java之后在Internet上最激动人心的新技术。
1.2 XML和HTML的区别
XML 不是 HTML 的替代。
XML 和 HTML 为不同的目的而设计:
XML 被设计为传输和存储数据,其焦点是数据的内容。XML 不会做任何事情。XML 被设计用来结构化、存储以及传输信息。XML 没什么特别的。它仅仅是纯文本而已。有能力处理纯文本的软件都可以处理 XML。不过,能够读懂 XML 的应用程序可以有针对性地处理 XML 的标签。标签的功能性意义依赖于应用程序的特性。XML 允许创作者定义自己的标签和自己的文档结构。
HTML 被设计用来显示数据,其焦点是数据的外观。在 HTML 中使用的标签(以及 HTML 的结构)是预定义的。HTML 文档只使用在 HTML 标准中定义过的标签(比如 <p> 、<h1> 等等)。
HTML 旨在显示信息,而 XML 旨在传输信息。
1.3 XML的用途
在现实生活中存在大量有关系的数据,如下图所示。 问题:这样的数据该如何表示并交给计算机处理呢?

<?xml version="1.0" encoding="UTF-8"?> <中国> <北京> <海淀></海淀> <丰台></丰台> </北京> <山东> <济南></济南> <青岛></青岛> </山东> <湖北> <武汉></武汉> <荆州></荆州> </湖北> </中国>
XML语言出现的根本目的在于描述向上图那种有关系的数据。 XML是一种通用的数据交换格式。 在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可分为开始标签和结束标签,在起始标签之间,又可以使用其它标签描述其它数据,以此来实现数据关系的描述。 XML中的数据必须通过软件程序来解析执行或显示,如IE;这样的解析程序称之为Parser(解析器)。
在Java开发中,传统的配置文件是*.properties属性文件(key=value),而XML表示的数据更为丰富。 XML技术除用于描述有关系的数据外,还经常用作软件配置文件,以描述程序模块之间的关系。(如Struts、Spring和Hibernate都是基于XML作为配置文件的) 在一个软件系统中,通过XML配置文件可以提高系统的灵活性。即程序的行为是通过XML文件来配置的,而不是硬编码。
XML细分可以分为下面几种应用:
1.3.1 存储数据
存储数据是XML最根本的用途,由于它可以保存为数据文件,对于一些需要持久化保存的数据可以使用XML格式的方式存储;如各种配置文件web.xml,hbm.xml,beans.xml等;
1.3.2 分离数据
XML可以将数据和XML的展现相分离,使数据的组织人员更能够集中精力组织数据,使数据的展示人员更能够集中精力的设计数据的展现形式,真正实现人员的不同分工,大大加快开发效率;
1.3.3 交换数据
通过XML可以在不兼容的 系统之间交换数据.在现实生活中,计算机系统和数据库所存储的数据有很多种形式,对于开发者来说,最耗时间的就是在遍布网络的系统之间交换数据.把数据转换为XML格式存储将大大减少交换数据时的复杂性,并且还可以使得这些数据被不同的程序读取;例如说,目前流行的Ajax、webservice、SOA等,其实就是利用了XML的这种通用的数据格式,在不同的系统之间交换数据。
1.3.4 共享数据
通过XML、纯文本文件可以用来共享数据。既然XML数据是以纯文本格式存储的,那么XML提供了一种与软件和硬件无关的共享数据方法。这样创建一个能够被不同应用程序读取的数据文件就变得简单多了。同样,升级操作系统、升级服务区、升级应用程序、更新浏览器就容易多了;
1.4 XML的技术架构


2.XML的基本语法
一个XML文件一般由以下几部分组成: 文档声明、元素 、元素的属性 、注释 、CDATA区 、特殊字符 、处理指令(PI:Processing Instruction)

2.1 文档声明
在编写XML文档时,需要先使用文档声明来声明XML文档。且必须出现在文档的第一行。
最简单的语法:<?xml version=“1.0”?> version属性定义了该文档所遵循的XML标准的版本,用encoding属性说明文档所使用的字符编码,默认为UTF-8。保存在磁盘上的文件编码要与声明的编码一致。
如:<?xml version=“1.0” encoding=“GB2312”?>
用standalone属性说明文档是否独立,即是否依赖其他文档。
如:<?xml version=“1.0” standalone=“yes”?>
2.2 元素
XML元素指XML文件中出现的标签。一个标签分为起始和结束标签(不能省略)。一个标签有如下几种书写形式:
包含标签主体:<mytag>some content</mytag>
不含标签主体:<mytag/>
一个标签中可以嵌套若干子标签,但所有标签必须合理的嵌套,不允许有交叉嵌套。
<mytag1><mytag2></mytag1></mytag2> WRONG
一个XML文档必须有且仅有一个根标签,其他标签都是这个根标签的子标签或孙标签。
XML中不会忽略主体内容中出现的空格和换行。
第一段: <中国><北京><海淀/></北京></中国>
 给人看,直观
给人看,直观
注:由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,使用换行和缩进等方式来让原文件中的内容清晰可读的“良好”书写习惯可能要被迫改变。
元素(标签)的名称可以包含字母、数字、减号、下划线和英文句点,但必须遵守下面的一些规范:
严格区分大小写;<P> <p>
只能以字母或下划线开头;abc _abc
不能以xml(或XML、Xml等)开头----W3C保留日后使用;
名称字符之间不能有空格或制表符;
ab 名称字符之间不能使用冒号; (有特殊用途)
通过上面我们简单归纳为一下几点:
标签必须合理闭合;没有文本节点时,采用自封闭语法对该元素节点进行闭合
标签和合理嵌套;
一个XML只会存在一个根标签,其它都为其子孙标签;
XML中不会忽略主体内容中出现的空格和换行。
标签的命名规则:
严格区分大小写;
只能以字母或下划线开头,不能以XML(或XML、xml、Xml等)开头,不能以数字或标点符号开头;
标签名字不能包含空格。也不能包含一些特殊字符(如& = :等)
2.3 元素的属性
一个元素可以有多个属性,每个属性都有它自己的名称和取值,例如:
<mytag name=“value” …/>
属性值一定要用引号(单引号或双引号)引起来。 属性名称的命名规范与元素的命名规范相同,元素中的属性是不允许重复的,
在XML技术中,标签属性所代表的信息也可以被改成用子元素的形式来描述,例如:
<mytag> <name> <firstName/> <lastName/> </name> </mytag>
2.4 注释
XML中的注释语法为:<!--这是注释--> 注意: XML声明之前不能有注释 注释不能嵌套,例如

2.5 CDATA的使用
CDATA是Character Data的缩写 作用:把标签当做普通文本内容; 语法:<![CDATA[内容]]>

CDATA部件之间不能再包含CDATA部件,即不能嵌套,如果CDTAT部件包含了字符]]>或<![CDTAT[,将有可能出错.同时要注意]]>之间不能有空格或者换行符;
2.6 转义字符的使用
对于一些特殊字符,若要在元素主体内容中显示,必须进行转义。

2.7 处理指令
处理指令,简称PI(Processing Instruction)。
作用:用来指挥软件如何解析XML文档。
语法:必须以“<?”作为开头,以“?>”作为结尾。
常用处理指令: XML声明:<?xml version=“1.0” encoding=“GB2312”?>
xml-stylesheet指令: 作用:指示XML文档所使用的CSS样式XSL。如下:
<?xml-stylesheet type=“text/css” href=“some.css”?> 注:对中文命名的标签元素不起作用
3.约束--数据定义
XML都是用户自定义的标签,若出现小小的错误,软件程序将不能正确地获取文件中的内容而报错。(如:Tomcat) XML技术中,可以编写一个文档来约束一个XML的书写规范,这个文档称之为约束。 两个概念: 格式良好的XML:遵循XML语法的XML 有效的XML:遵循约束文档的XML 总之:约束文档定义了在XML中允许出现的元素名称、属性及元素出现的顺序等等。
虽然XML的数据可以随时定义,但要遵循一定的规则才可以实现各个系统之间的数据交换,那么定义XML数据的语言常用的有两种DTD和Schema;DTD是早期的XML定义语言,但随着技术的不断发展,Schema的出现使得定义语言更加规范化,所以目前Schema较为流行,下面我们来详细认知一下;
3.1 DTD约束
DTD(Document Type Definition):文档类型定义。 作用:约束XML的书写规范,定义 XML 文档的合法构建模块。它使用一系列的合法元素来定义文档结构. DTD 可被成行地声明于 XML 文档中,也可作为一个外部引用。拥有正确语法的 XML 被称为“格式良好”的 XML。通过某个 DTD 进行了验证的 XML 是“合法”的 XML。
为什么使用 DTD?
通过 DTD,您的每一个 XML 文件均可携带一个有关其自身格式的描述。通过 DTD,独立的团体可一致地使用某个标准的 DTD 来交换数据。而您的应用程序也可使用某个标准的 DTD 来验证从外部接收到的数据。您还可以使用 DTD 来验证您自身的数据。
3.1.1 DTD的快速入门
3.1.1.1 一个例子
?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE books SYSTEM "books.dtd"> <books> <book lang="en"> <num></num> <author>tom</author> <price>99</price> </book> <book lang="zh"> <name>thinking in c++</name> <author>james</author> <price>88</price> </book> <book lang="ch"> <name>thinking in c++</name> <author>james</author> <price>88</price> </book> </books>
<?xml version="1.0" encoding="UTF-8"?> <!ELEMENT books (book+) > <!ELEMENT book ( (name|num),author,price)> <!ELEMENT name (#PCDATA)> <!ELEMENT author (#PCDATA) > <!ELEMENT price (#PCDATA) > <!ELEMENT num EMPTY > <!ATTLIST book lang ID #REQUIRED >

3.1.1.2 校验
何根据DTD中定义的内容来验证XML书写是否正确呢? 答:需要软件程序,即解析器 ,根据能否对XML文档进行约束模式校验,可以将解析器分为两类: 非校验解析器,如IE 校验解析器
IE5以上浏览器内置了XML解析工具:Microsoft.XMLDOM,开发人员可以编写javascript代码,利用这个解析工具装载xml文件,并对xml文件进行dtd验证。
创建xml文档解析器对象 var xmldoc = new ActiveXObject("Microsoft.XMLDOM");
开启xml校验 xmldoc.validateOnParse = "true";
装载xml文档 xmldoc.load("book.xml");
获取错误信息 xmldoc.parseError.reason;
xmldoc.parseError.line
除了使用浏览器外,我们还可以使用Eclipse进行校验
3.1.2 DTD与XML的关联方式
DTD约束文档可以在XML文档中直接定义,也可以作为单独的文档进行编写(单独的文档必须以UTF-8编码进行保存) 。
l 使用内部DTD
l 使用外部DTD SYSTEM
l 使用公共DTD PUBLIC
3.1.2.1 在XML文档中编写--使用内部DTD
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE 书架[ <!ELEMENT 书架 (书+)> <!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)> ]> <书架> <书> <书名>Java从入门到精通</书名> <作者>明日科技</作者> <售价>78</售价> </书> <书> <书名>JavaWeb整合开发王者归来</书名> <作者>刘景华</作者> <售价>98</售价> </书> <书> <书名>JavaWeb整合开发王者归来</书名> <!-- <售价>98</售价> --> <作者>刘景华</作者> <售价>98</售价> </书> </书架>
3.1.2.2 引入外部DTD
XML使用DOCTYPE声明语句来指明它所遵循的DTD文档,有两种形式:
当引用的DTD文档在本地时,采用如下方式: <!DOCTYPE 根元素 SYSTEM “DTD文档路径”> 如:<!DOCTYPE 书架 SYSTEM “book.dtd”>
当引用的DTD文档在公共网络上时,采用如下方式: <!DOCTYPE 根元素 PUBLIC “DTD名称” “DTD文档的URL”> 如:<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
<?xml version="1.0" ?> <!DOCTYPE 书架 SYSTEM "book.dtd"> <书架> <书> <书名>Java从入门到精通</书名> <作者>明日科技</作者> <售价>78</售价> </书> <书> <书名>JavaWeb整合开发王者归来</书名> <作者>刘景华</作者> <售价>98</售价> </书> <书> <书名>JavaWeb整合开发王者归来</书名> <!-- <售价>98</售价> --> <作者>刘景华</作者> <售价>98</售价> </书> </书架>
3.1.3 DTD的语法
DTD文档的语法主要涉及以下内容的定义: 定义元素 定义属性 定义实体
3.1.3.1 定义元素
在DTD文档中使用ELEMENT关键字来声明一个XML元素。
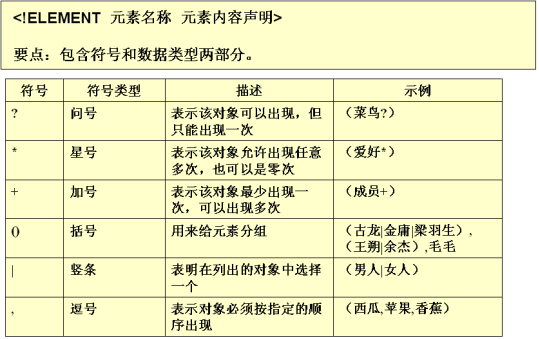
语法:<!ELEMENT 元素名称 使用规则>
使用规则: (#PCDATA):指示元素的主体内容只能是普通的文本.(Parsed Character Data)
EMPTY:用于指示元素的主体为空。比如<br/>
ANY:用于指示元素的主体内容为任意类型。
(子元素):指示元素中包含的子元素 定义子元素及描述它们的关系: 如果子元素用逗号分开,说明必须按照声明顺序去编写XML文档。 如: <!ELEMENT FILE (TITLE,AUTHOR,EMAIL) 如果子元素用“|”分开,说明任选其一。 如:<!ELEMENT FILE (TITLE|AUTHOR|EMAIL) 用+、*、?来表示元素出现的次数 如果元素后面没有+*?:表示必须且只能出现一次 +:表示至少出现一次,一次或多次 *:表示可有可无,零次、一次或多次 ?:表示可以有也可以无,有的话只能有一次。零次或一次 如: <!ELEMENT MYFILE ((TITLE*, AUTHOR?, EMAIL)* | COMMENT)>
DTD元素
元素内容类型

3.1.3.2 定义属性
在DTD文档中使用ATTLIST关键字来为一个元素声明属性。 语法:

例如:

属性值类型: CDATA:表示属性的取值为普通的文本字符串 ENUMERATED (DTD没有此关键字):表示枚举,只能从枚举列表中任选其一,如(鸡肉|牛肉|猪肉|鱼肉) ID:表示属性的取值不能重复 设置说明 #REQUIRED:表示该属性必须出现 #IMPLIED:表示该属性可有可无 #FIXED:表示属性的取值为一个固定值。语法:#FIXED "固定值" 直接值:表示属性的取值为该默认值

<?xml version = "1.0" encoding="GB2312"standalone="yes"?> <!DOCTYPE 购物篮 [ <!ELEMENT 肉 EMPTY> <!ATTLIST 肉 品种 ( 鸡肉 | 牛肉 | 猪肉 | 鱼肉 ) "鸡肉"> ]> <购物篮> <肉 品种="鱼肉"/> <肉 品种="牛肉"/> <肉/> </购物篮>
实例:

3.1.3.3 定义实体
定义实体就是为一段内容指定一个名称,使用时通过这个名称就可以引用其所代表的内容。 在DTD文档中使用ENTITY关键字来声明一个实体。 实体可分为:引用实体和参数实体,两者的语法不同
概念:在DTD中定义,在XML中使用 语法:<!ENTITY 实体名称 “实体内容”> 引用方式(注意是在XML中使用):&实体名称;

概念:在DTD中定义,在DTD中使用 语法:<!ENTITY % 实体名称 “实体内容”> 引用方式(注意是在DTD中使用):%实体名称;

3.2 Schema约束
XML Schema 也是一种用于定义和描述 XML 文档结构与内容的模式语言,其出现是为了克服 DTD 的局限性
XML Schema VS DTD:
XML Schema符合XML语法结构。
DOM、SAX等XML API很容易解析出XML Schema文档中的内容。
XML Schema对名称空间支持得非常好。
XML Schema比XML DTD支持更多的数据类型,并支持用户自定义新的数据类型。
XML Schema定义约束的能力非常强大,可以对XML实例文档作出细致的语义限制。
XML Schema不能像DTD一样定义实体,比DTD更复杂,但Xml Schema现在已是w3c组织的标准,它正逐步取代DTD。
XML Schema 文件自身就是一个XML文件,但它的扩展名通常为.xsd。 一个XML Schema文档通常称之为模式文档(约束文档),遵循这个文档书写的xml文件称之为实例文档。 和XML文件一样,一个XML Schema文档也必须有一个根结点,但这个根结点的名称为schema。 编写了一个XML Schema约束文档后,通常需要把这个文件中声明的元素绑定到一个URI地址上,在XML Schema技术中有一个专业术语来描述这个过程,即把XML Schema文档声明的元素绑定到一个名称空间上,以后XML文件就可以通过这个URI(即名称空间)来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。


名称空间
在XML Schema中,每个约束模式文档都可以被赋以一个唯一的名称空间,名称空间用一个唯一的URI(Uniform Resource Identifier,统一资源标识符)表示。 在Xml文件中书写标签时,可以通过名称空间声明(xmlns),来声明当前编写的标签来自哪个Schema约束文档。如:
<itcast:书架 xmlns:itcast=“http://www.itcast.cn”>
<itcast:书>……
</itcast:书>
</itcast:书架>
此处使用itcast来指向声明的名称,以便于后面对名称空间的引用。 注意:名称空间的名字语法容易让人混淆,尽管以 http:// 开始,那个 URL 并不指向一个包含模式定义的文件。事实上,这个 URL:http://www.itcast.cn根本没有指向任何文件,只是一个分配的名字。
为了在一个XML文档中声明它所遵循的Schema文件的具体位置,通常需要在Xml文档中的根结点中使用schemaLocation属性来指定,例如:
<itcast:书架 xmlns:itcast="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">
schemaLocation此属性有两个值。第一个值是需要使用的命名空间。第二个值是供命名空间使用的 XML schema 的位置,两者之间用空格分隔。 注意,在使用schemaLocation属性时,也需要指定该属性来自哪里。
使用默认的名称空间
基本格式: xmlns="URI" 举例:
<书架 xmlns="http://www.it315.org/xmlbook/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.it315.org/xmlbook/schema book.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
<书架>
使用多个名称空间引入多个XML Schema文件
文件清单:xmlbook.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架 xmlns="http://www.it315.org/xmlbook/schema"
xmlns:demo="http://www.it315.org/demo/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.it315.org/xmlbook/schema
http://www.it315.org/xmlbook.xsd
http://www.it315.org/demo/schema
http://www.it315.org/demo.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价 demo:币种=”人民币”>28.00元</售价>
</书>
</书架>
不使用名称空间引入Schema文件
文件清单:xmlbook.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="xmlbook.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>
在XML Schema文档中声明名称空间
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www. itcast.cn" elementFormDefault="qualified"> <xs:schema>
targetNamespace元素用于指定schema文档中声明的元素属于哪个名称空间。
elementFormDefault元素用于指定,该schema文档中声明的根元素及其所有子元素都属于targetNamespace所指定的名称空间。
3.2.3 详解xml中导入Schema约束的步骤:
* 掌握引用schema文件:
xml中引入schema约束的步骤:
1、查看schema文档,找到根元素,在xml中写出来
<?xml version="1.0" encoding="UTF-8"?>
<书架>
</书架>
2、根元素来自哪个名称空间。使用xmlns指令来声明
名称空间是在schema中定义的,就是targetNamespace的值
<?xml version="1.0" encoding="UTF-8"?>
<itcast:书架 xmlns:itcast="http://www.itcast.com/book">
</itcast:书架>
3、引入的名称空间根哪个xsd文件对应?
使用schemaLocation来指定:两个取值:第一个为名称空间 第二个为xsd文件的路径
<?xml version="1.0" encoding="UTF-8"?>
<itcast:书架 xmlns:itcast="http://www.itcast.com/book"
schemaLocation="http://www.itcast.com/book book.xsd">
</itcast:书架>
4、schemaLocation哪里来的?它来自一个标准的名称空间,直接复制黏贴即可.
<?xml version="1.0" encoding="UTF-8"?>
<itcast:书架 xmlns:itcast="http://www.itcast.com/book"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.com/book book.xsd">
</itcast:书架>
5、只要以上4部搞好了,对于子标签myeclipse就有提示了
4. XML的解析
XML解析方式分为两种:DOM方式和SAX方式
DOM:Document Object Model,文档对象模型。这种方式是W3C推荐的处理XML的一种方式。
SAX:Simple API for XML。这种方式不是官方标准,属于开源社区XML-DEV,几乎所有的XML解析器都支持它。
XML解析开发包
JAXP:是SUN公司推出的解析标准实现。
Dom4J:是开源组织推出的解析开发包。(牛,大家都在用,包括SUN公司的一些技术的实现都在用)
JDom:是开源组织推出的解析开发包。
4.1 Sax解析与dom解析的区别
l DOM 支持回写
- 会将整个XML载入内存,以树形结构方式存储
- 一个300KB的XML文档可以导致RAM内存或者虚拟内存中的3,000,000KB的DOM树型结构
- XML比较复杂的时候,或者当你需要随机处理文档中数据的时候不建议使用
l SAX
- 相比DOM是一种更为轻量级的方案
- 采用串行方法读取 --- 逐行读取
- 编程较为复杂
- 无法修改XML数据
- 选择 DOM 还是 SAX,这取决于几个因素
l 应用程序的目的:如果必须对数据进行更改,并且作为 XML 将它输出,则在大多数情况下,使用 DOM
l 数据的数量:对于大文件,SAX 是更好的选择
l 将如何使用数据:如果实际上只使用一小部分数据,则使用 SAX 将数据抽取到应用程序中,这种方法更好些
l 需要速度:通常,SAX 实现比 DOM 实现快
* DOM 解析(Java解析) : 利用DOM树来解析
* SAX 解析 : 边加载边解析.
4.2 DOM解析
JAXP:(Java API for XML Processing)开发包是JavaSE的一部分,它由以下几个包及其子包组成:
org.w3c.dom:提供DOM方式解析XML的标准接口
org.xml.sax:提供SAX方式解析XML的标准接口
javax.xml:提供了解析XML文档的类 j
avax.xml.parsers包中,定义了几个工厂类。我们可以通过调用这些工厂类,得到对XML文档进行解析的DOM和SAX解析器对象。 DocumentBuilderFactory SAXParserFactory
l 解析器工厂类DocumentBuilderFactory
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
l 解析器类DocumentBuilder
- DocumentBuilder db = dbf.newDocumentBuilder();
l 解析生成Document对象
- Document doc = db.parse("message.xml");
l 通过Document对象查询节点
- document.getElementById 返回Node对象 --- 必须文档元素有ID属性
- document.getElementsByTagName 返回NodeList对象
- 查询节点API
通过Document对象查询节点
n document.getElementById 返回Node对象 --- 必须文档元素有ID属性
n document.getElementsByTagName 返回NodeList对象
- 什么是节点:元素、属性、文本、实体、注释
Node 子接口: Element、Attr、Text、Document
- NodeList API
节点列表类NodeList就是代表了一个包含一个或者多个Node的列表,可以简单的把它看成一个Node的数组
n 常用方法
u getLength():返回列表的长度。
l ArrayList size
u item(int):返回指定位置的Node对象
l ArrayList get(index)
- Node API
Node对象提供了一系列常量来代表结点的类型
当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象
n getAttribute(String):返回标签中给定属性的值(元素)
n getAttributeNode(name):返回指定名称的属性节点(元素)
n getNodeName():返回节点的名称(元素-- > 标签名)
n getNodeType():返回节点的类型
n getNodeValue():返回节点的值
n getChildNodes():返回这个节点的所有子节点列表
n getFirstChild():返回这个节点的第一个子节点
n getParentNode():返回这个节点的父节点对象
n appendChild(org.w3c.dom.Node):为这个节点添加一个子节点,并放在所有子节点的最后,如果这个子节点已经存在,则先把它删掉再添加进去
n removeChild(org.w3c.dom.Node):删除给定的子节点对象
n replaceChild(org.w3c.dom.Node new,org.w3c.dom.Node old):用一个新的Node对象代替给定的子节点对象
n getNextSibling():返回在DOM树中这个节点的下一个兄弟节点
n getPreviousSibling()返回在DOM树中这个节点的前一个兄弟节点
- dom回写
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
n javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
n 用javax.xml.transform.stream.StreamResult 对象来表示数据的目的地。
Transformer对象通过TransformerFactory获得。
package dom.parser; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.SourceLocator; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.TransformerFactoryConfigurationError; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; //演示采用Jaxp的DOM解析XML文档 public class XML_DOMParser { public static void main(String[] args) throws SAXException, IOException, ParserConfigurationException, TransformerException { //首先创建解析器工厂类 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); //创建解释器 DocumentBuilder db = dbf.newDocumentBuilder(); //加载XML文档 Document document = db.parse("src/book.xml"); //获取某个节点,返回节点中的文本内容 getNode(document); //首先拿到根节点 NodeList nl = document.getElementsByTagName("书架"); Node node = nl.item(0); getAllNodes(node); //修改节点内容 changeElement(document); //添加节点 addElement(document); //添加节点 addBrotherElement(document); //删除节点 deleteElement(document); //添加属性 addAttribute(document); //删除属性 deleteAttribute(document); } //得到某个具体的节点 public static void getNode(Document document){ NodeList n1 = document.getElementsByTagName("作者"); //拿到第一个作者 Node node = n1.item(0); String name = node.getTextContent(); System.out.println("获取到的第一个作者是:"+name); } //遍历所有的元素节点 public static void getAllNodes(Node node){ //拿到所有的子节点 NodeList nlc = node.getChildNodes(); //循环判断每个节点是否是标签节点,如果是,继续递归 for (int i = 0; i <nlc.getLength(); i++) { if(nlc.item(i).getNodeType() == Node.ELEMENT_NODE){ //说明此节点是标签节点 System.out.println("节点名称:"+nlc.item(i).getNodeName()); //递归遍历里边的标签 getAllNodes(nlc.item(i)); } } } //3、修改某个元素节点的主体内容 : 把JavaWeb整合开发王者归来的售价改为50 public static void changeElement(Document document) throws TransformerException{ NodeList nl = document.getElementsByTagName("售价"); Node node = nl.item(1); node.setTextContent("50"); System.out.println("修改后的售价:"+node.getTextContent()); //通过上面打印我们发现,修改成功了,但是打开xml我们发现并内有修改,此时我们应当把改动的结果写回到硬盘上,即回写 //创建一个转换器 TransformerFactory tfc = TransformerFactory.newInstance(); Transformer tf = tfc.newTransformer(); //把结果写回硬盘 tf.transform(new DOMSource(document), new StreamResult("src/book.xml")); } //4、向指定元素节点中增加子元素节点: 给javaWeb整合开发王者归来的售价加一个子节点: "内部价" :50 public static void addElement(Document document) throws TransformerFactoryConfigurationError, TransformerException{ NodeList nl = document.getElementsByTagName("售价"); Node node = nl.item(1); //创建新节点 Node no = document.createElement("内部价"); int price = Integer.parseInt(node.getTextContent())*8/10; //给内部价设置内容 no.setTextContent(Integer.toString(price)); //把创建的新节点添加到指定节点中 node.appendChild(no); //创建转换器,把数据写入硬盘 Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.transform(new DOMSource(document), new StreamResult("src/book.xml")); } //5、向指定元素节点上增加同级元素节点 :给javaWeb整合开发王者归来的售价添加兄弟节点 : "批发价"值: 60 public static void addBrotherElement(Document document) throws TransformerFactoryConfigurationError, TransformerException{ NodeList nl = document.getElementsByTagName("书"); Node node = nl.item(2); Node no = document.createElement("批发价"); no.setTextContent("45"); node.appendChild(no); Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.transform(new DOMSource(document), new StreamResult("src/book.xml")); } //删除指定元素节点 : 删除内部价节点 public static void deleteElement(Document document) throws TransformerFactoryConfigurationError, TransformerException{ //拿到所有节点 NodeList nl = document.getElementsByTagName("内部价"); Node node = nl.item(0); //删除该节点 node.getParentNode().removeChild(node); Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.transform(new DOMSource(document), new StreamResult("src/book.xml")); } //操作XML文件属性: 给javaWeb书节点添加ISBN属性 : "20170612" public static void addAttribute(Document document) throws TransformerException{ NodeList nl = document.getElementsByTagName("书"); Node node = nl.item(1); ((Element)node).setAttribute("ISBN", "20170612"); //写入到硬盘 Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.transform(new DOMSource(document), new StreamResult("src/book.xml")); } //删除属性 public static void deleteAttribute(Document document) throws TransformerException{ NodeList nl = document.getElementsByTagName("书"); Node node = nl.item(1); ((Element)node).removeAttribute("ISBN"); Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.transform(new DOMSource(document), new StreamResult("src/book.xml")); } }
4.3 SAX解析
根据element可以获得元素名称与属性内容
根据character可以获取文本内容.
l SAX 是事件驱动的 XML 处理方法
l 它是基于事件驱动的
l startElement() 回调在每次 SAX 解析器遇到元素的起始标记时被调用
l characters() 回调为字符数据所调用
l endElement() 为元素的结束标记所调用
l DefaultHandler类(在 org.xml.sax.helpers 软件包中)来实现所有这些回调,并提供所有回调方法默认的空实现
- Sax解析步骤
l 使用SAXParserFactory创建SAX解析工厂
- SAXParserFactory spf = SAXParserFactory.newInstance();
l 通过SAX解析工厂得到解析器对象
- SAXParser sp = spf.newSAXParser();
l 通过解析器对象得到一个XML的读取器
- XMLReader xmlReader = sp.getXMLReader();
l 设置读取器的事件处理器
- xmlReader.setContentHandler(new XMLContentHandler());
l 解析xml文件
- xmlReader.parse("book.xml");
sax解析示例
package sax_parser; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.DefaultHandler; //演示SAX解析文档的几个方法 public class XML_SAXParser { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { //首先获得一个解析器--获取工厂解释器 SAXParserFactory spf = SAXParserFactory.newInstance(); //获取解析器 SAXParser sp = spf.newSAXParser(); //获取一个读写器 XMLReader reader = sp.getXMLReader(); //注册一个处理器(注册的是内容处理器) reader.setContentHandler(new DefaultHandler(){ //在开始解析文档时调用 public void startDocument() throws SAXException { System.out.println("文档开始解析了"); } //是文档解析结束时调用 public void endDocument() throws SAXException { System.out.println("文档解析结束了"); } //解析到标签节点时调用 public <Attributes> void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { System.out.println(qName + " 解析开始了"); } //解析到结束标签时调用 public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println(qName + " 解析结束了"); } //解析到文本节点时调用 public void characters(char[] ch, int start, int length) throws SAXException { System.out.println("文本内容: " + new String(ch,start ,length)); } }) ; //加载xml文档 reader.parse("src/book.xml"); } }
package sax_parser; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.DefaultHandler; //演示打印Java开发从入门到精通的作者 public class XML_SAXPParserDemo { public static void main(String[] args) throws SAXException, ParserConfigurationException, IOException { //获取一个解析器 SAXParser sp = SAXParserFactory.newInstance().newSAXParser(); //获取一个读取器 XMLReader reader = sp.getXMLReader(); //获取一个处理器((注册的是内容处理器)) reader.setContentHandler(new DefaultHandler(){ //声明两个变量作为标签名称和作者个数 String curName = null; int index = 0; //文档解析开始时输出打印 public void startDocument (){ System.out.println("文档解析开始了!"); } //文档解析结束时,输出打印 public void endDocument(){ System.out.println("文档解析结束了!"); } //解析到标签节点时调用 public void startElement (String uri, String localName, String qName, Attributes attributes) throws SAXException{ // System.out.println(qName+"解析开始了!"); //假如标签节点名称是作者,那么把这个节点赋值给curName,并且记录作者个数加1,说明此事出现index个作者标签 if("作者".equals(qName)){ curName = qName; index++; } } //解析到标签尾部时调用 public void endElement (String uri, String localName, String qName) throws SAXException{ // System.out.println(qName+"解析结束了!"); //标签解析结束,把标签名称,重新赋值为null curName = null; } //解析到文本节点时调用 public void characters(char[] ch, int start, int length) throws SAXException { if("作者".equals(curName) && index == 1){ System.out.println(new String(ch,start,length)); } } //注意调用顺序为startDocument-->startElement-->characters-->endElement-->endDocument }); //加载XML文档 reader.parse("src/book.xml"); } }
package sax_parser; /** * 成为一个javabean满足的条件: * 1. 所有的属性必须是私有的 * 2. 提供getter和setter方法 * 3. 提供无参的构造器 * 4. 必须要实现serializable接口 * */ public class Book { private String bookName; private String author; private float price; public String getBookName() { return bookName; } public void setBookName(String bookName) { this.bookName = bookName; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } public float getPrice() { return price; } public void setPrice(float price) { this.price = price; } @Override public String toString() { // TODO Auto-generated method stub return "Book [bookName=" + bookName + ", author=" + author + ", price=" + price + "]"; } }
package sax_parser; import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.ContentHandler; import org.xml.sax.Locator; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.DefaultHandler; //演示将所有的书都封装到javabean中 public class XML_SAXParser_JavaBean_Test { //创建集合存储book对象 final static ArrayList<Book> list = new ArrayList<>(); public static void main(String[] args) throws SAXException, ParserConfigurationException, IOException { test(); iteratorArrayList(list); } public static void test() throws ParserConfigurationException, SAXException, IOException{ //首先创建一个JavaBean类book //获取解析器 SAXParser sp = SAXParserFactory.newInstance().newSAXParser(); XMLReader reader = sp.getXMLReader(); reader.setContentHandler(new DefaultHandler(){ //创建book对象,存储XML解析出的书籍 Book book = null; String curName = "" ; //用来记录当前的标签名字 @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { System.out.println(qName+"开始解析了!"); //解析到书节点的时候,创建book对象 if("书".equals(qName)){ book = new Book(); } curName = qName; } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println(qName+"结束解析了!"); //解析到书节点的结束标签时应该将book对象放入集合 if("书".equals(qName)){ list.add(book); } curName = null; } @Override public void startDocument() throws SAXException { System.out.println("开始解析XML文档了!"); } @Override public void endDocument() throws SAXException { System.out.println("结束解析文档了!"); } @Override public void characters(char[] ch, int start, int length) throws SAXException { if("书名".equals(curName)){ book.setBookName(new String(ch, start, length)); } if("作者".equals(curName)){ book.setAuthor(new String(ch, start, length)); } if("售价".equals(curName)){ book.setPrice(Float.parseFloat(new String(ch, start, length))); } System.out.println(new String(ch, start, length)); } }); reader.parse("src/book.xml"); } //遍历集合 public static void iteratorArrayList(ArrayList<Book> list){ for (Iterator iterator = list.iterator(); iterator.hasNext();) { Book book = (Book) iterator.next(); System.out.println(book); } } }
综合练习:

<?xml version="1.0" encoding="UTF-8" standalone="no"?><exam>
<student examid="222" idcard="111">
<name>张三</name>
<location>沈阳</location>
<grade>89</grade>
</student>
<student examid="444" idcard="333">
<name>李四</name>
<location>大连</location>
<grade>97</grade>
</student>
</exam>
package util; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.TransformerFactoryConfigurationError; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.xml.sax.SAXException; //工具类 public class JaxpUtils { //加载XML public static Document loadXML(File file){ //创建文档类型,作为最后的返回值 Document document = null; try { DocumentBuilder db = DocumentBuilderFactory.newInstance().newDocumentBuilder(); //加载XML文档 document = db.parse(file); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return document; } //写入到硬盘 public static void writeToXML(Document document){ try { //创建一个转换器 Transformer tf = TransformerFactory.newInstance().newTransformer(); //数据写入到硬盘 tf.transform(new DOMSource(document), new StreamResult("src/exam.xml")); } catch (TransformerConfigurationException | TransformerFactoryConfigurationError e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (TransformerException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
package domain; public class Student { private String name ; private String examid ; //准考证号 private String idcard ; //身份证号 private String location ; //地址 private float grade ; //考试分数 public String getName() { return name; } public void setName(String name) { this.name = name; } public String getExamid() { return examid; } public void setExamid(String examid) { this.examid = examid; } public String getIdcard() { return idcard; } public void setIdcard(String idcard) { this.idcard = idcard; } public String getLocation() { return location; } public void setLocation(String location) { this.location = location; } public float getGrade() { return grade; } public void setGrade(float grade) { this.grade = grade; } @Override public String toString() { // TODO Auto-generated method stub return "Student [name=" + name + ", examid=" + examid + ", idcard=" + idcard + ", location=" + location + ", grade=" + grade + "]"; } }
package dao; import java.io.File; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import util.JaxpUtils; import domain.Student; public class StudentDao { /** * 功能是添加学生到XML文档中 * @param student 要添加的对象 * @return true表示添加成功,FALSE添加失败 */ public boolean add(Student student){ //创建XML文件对象 File file = new File("src/exam.xml"); //首先加载XML文档 Document document = JaxpUtils.loadXML(file); //拿到XML的根节点 Node exam = document.getDocumentElement(); //创建student节点 Element studentNode = document.createElement("student"); //设置属性 studentNode.setAttribute("examid", student.getExamid()); studentNode.setAttribute("idcard", student.getIdcard()); //创建name节点 Element nameNode = document.createElement("name"); //写入文本内容 nameNode.setTextContent(student.getName()); //创建location节点 Element locationNode = document.createElement("location"); //写入文本内容 locationNode.setTextContent(student.getLocation()); //创建grade节点 Element gradeNode = document.createElement("grade"); gradeNode.setTextContent(Float.toString(student.getGrade())); //组合节点 studentNode.appendChild(nameNode); studentNode.appendChild(locationNode); studentNode.appendChild(gradeNode); exam.appendChild(studentNode); //将结果写入到硬盘 JaxpUtils.writeToXML(document); //返回操作结果 return true; } /** * 通过准考证号查询学生 * @param examId 准考证号 * @return 查到了返回此对象,否则返回null */ public Student findStudentByExamId(String examId){ //加载XML文档 File file = new File("src/exam.xml"); Document document = JaxpUtils.loadXML(file); //获取所有的student节点 NodeList nl = document.getElementsByTagName("student"); //创建学生对象,用来存取,要查找的学生信息 Student s = null; //遍历所有的节点 for (int i = 0; i < nl.getLength(); i++) { //获取每个student节点 Element student = (Element) nl.item(i); //判断根据输入的准考证号是否能查找到学生 if(student.getAttribute("examid").equals(examId)){ s = new Student(); //获取学生姓名 String name = student.getElementsByTagName("name").item(0).getTextContent(); //获取学生地址 String location = student.getElementsByTagName("location").item(0).getTextContent(); //获取学生分数 Float grade = Float.parseFloat(student.getElementsByTagName("grade").item(0).getTextContent()); //获取学生身份证号 String idcard = student.getAttribute("idcard"); s.setName(name); s.setExamid(examId); s.setGrade(grade); s.setIdcard(idcard); s.setLocation(location); //此时说明已经找到这个学生,因为examId是唯一的,所以此时我们已经不需要循环了,所以可以结束循环,使用break break; }else { System.out.println("对不起没有您要查找的学生,请检查信息是否输入正确!"); } } return s; } /** * 根据姓名删除学生 * @param name 姓名 * @return 删除成功返回true, 否则返回false */ public boolean deleteStudent(String name){ //加载XML文件 File file = new File("src/exam.xml"); Document document = JaxpUtils.loadXML(file); //获取所有的name节点 NodeList nl = document.getElementsByTagName("name"); //遍历节点,判断是否有要删除的节点 for (int i = 0; i < nl.getLength(); i++) { Element nameNode = (Element) nl.item(i); //获取节点文本 String nameText = nameNode.getTextContent(); //判断 if(nameText.equals(name)){ //如果存在这个节点,那么删除student节点,即获取到祖父节点,通过祖父节点删除子节点 Node exam = nameNode.getParentNode().getParentNode(); Node student = nameNode.getParentNode(); exam.removeChild(student); //将结果写回硬盘 JaxpUtils.writeToXML(document); //操作成功,返回true return true; } } //没有要查找的student,返回失败 return false; } }
package view; import java.util.Scanner; import util.JaxpUtils; import dao.StudentDao; import domain.Student; //人和程序交互的界面(view) public class StudentTest { public static void main(String[] args) { System.out.println("添加学生(a),查找学生(b),删除学生(c)"); Scanner sc = new Scanner(System.in); System.out.println("请输入操作类型:"); //定义一个变量作为操作类型 String type = sc.next(); //创建一个学生操作类的对象 StudentDao dao = new StudentDao(); //判断操作类型 //假如是添加操作 if("a".equalsIgnoreCase(type)){ //添加学生 Student student = new Student(); System.out.println("请输入学生姓名:"); //将传入的学生姓名设置为对象属性值 student.setName(sc.next()); System.out.println("请输入学生准考证号:"); student.setExamid(sc.next()); System.out.println("请输入身份证号:"); student.setIdcard(sc.next()); System.out.println("请输入地址: "); student.setLocation(sc.next()); System.out.println("请输入分数: "); student.setGrade(sc.nextFloat()); //添加到XML中 boolean flag = dao.add(student); if (flag) { System.out.println("添加成功!"); } else { System.out.println("系统吗,请待会再试!"); } }else if ("b".equalsIgnoreCase(type)) { System.out.println("请输入要查询的学生的学号:"); String examId = sc.next(); Student student = dao.findStudentByExamId(examId); System.out.println(student); }else if ("c".equalsIgnoreCase(type)) { System.out.println("输入您要删除的学生姓名:"); String name = sc.next(); boolean flag = dao.deleteStudent(name); if (flag) { System.out.println("恭喜您已成功删除!"); } else { System.out.println("对不起,未查询到要删除的学生,请检查您的输入!"); } } } }
5.Dom4j解析
l Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性,l Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j,使用Dom4j开发,需下载dom4j相应的jar文件
Dom4j导包

XPath: 主要作用是获取某个节点的路径 。
package dom4j.parser; import java.io.FileOutputStream; import java.util.List; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; //演示Dom4j解析XML文档 public class Dom4j_ParserXML{ public static void main(String[] args) throws Exception{ //首先获得解析器 SAXReader reader = new SAXReader() ; //加载文档 Document document = reader.read("src/book.xml") ; // test1(document) ; // test2(document) ; // test3(document) ; // test4(document) ; // test5(document) ; // test6(document) ; test7(document) ; } // 1、得到某个具体的节点内容 : 得到葵花宝典的作者:段文豪 public static void test1(Document document){ //获得根节点 Element root = document.getRootElement() ; //element拿到子节点,必须一级一级拿 List<Node> list = root.elements("书") ; //拿到第二本书 Node secondBook = (Node)list.get(1) ; //拿到第二本书的作者节点 Element author = ((Element)secondBook).element("作者") ; //拿到作者节点的内容文本 System.out.println(author.getText()); } // 2、遍历所有元素节点 public static void test2(Document document){ treeWalk( document.getRootElement() ); } public static void treeWalk(Element element) { for ( int i = 0, size = element.nodeCount(); i < size; i++ ) { Node node = element.node(i); if ( node instanceof Element ) { System.out.println(node.getName()); treeWalk( (Element) node ); } } } // 3、修改某个元素节点的主体内容 : 将葵花宝典的售价改为100 public static void test3(Document document) throws Exception{ //获得根节点 Element root = document.getRootElement() ; //element拿到子节点,必须一级一级拿 List<Node> list = root.elements("书") ; //拿到第二本书 Node secondBook = (Node)list.get(1) ; //拿到第二本书的作者节点 Element priceNode = ((Element)secondBook).element("售价") ; //改变价格 priceNode.setText("100") ; //保存到硬盘上 XMLWriter xml = new XMLWriter(new FileOutputStream("src/book.xml")) ; xml.write(document) ; xml.close() ; } // 4、向指定元素节点中增加子元素节点: 给***的售价加子节点: 内部价: 50 public static void test4(Document document) throws Exception{ //获得根节点 Element root = document.getRootElement() ; //element拿到子节点,必须一级一级拿 List<Node> list = root.elements("书") ; //拿到第一本书 Node firstBook = (Node)list.get(0) ; //拿到第一本书的售价节点 Element priceNode = ((Element)firstBook).element("售价") ; priceNode.addElement("内部价").setText("50") ; //保存到硬盘上 XMLWriter xml = new XMLWriter(new FileOutputStream("src/book.xml"),OutputFormat.createPrettyPrint()) ; xml.write(document) ; xml.close() ; } // 5、向指定元素节点上增加同级元素节点: 给***的售价加同级节点:"批发价:60" public static void test5(Document document) throws Exception{ //获得根节点 Element root = document.getRootElement() ; //element拿到子节点,必须一级一级拿 List<Node> list = root.elements("书") ; //拿到第一本书 Node firstBook = (Node)list.get(0) ; //加子节点 ((Element)firstBook).addElement("批发价").setText("60") ; //保存到硬盘上 XMLWriter xml = new XMLWriter(new FileOutputStream("src/book.xml"),OutputFormat.createPrettyPrint()) ; xml.write(document) ; xml.close() ; } // 6、删除指定元素节点 : 把内部价删除 public static void test6(Document document) throws Exception{ //获得根节点 Element root = document.getRootElement() ; //element拿到子节点,必须一级一级拿 List<Node> list = root.elements("书") ; //拿到第一本书 Node firstBook = (Node)list.get(0) ; //拿到第一本书的售价节点 Element priceNode = ((Element)firstBook).element("售价") ; //拿到内部价节点 Element el = priceNode.element("内部价") ; //删除内部价 priceNode.remove(el) ; //保存到硬盘上 XMLWriter xml = new XMLWriter(new FileOutputStream("src/book.xml"),OutputFormat.createPrettyPrint()) ; xml.write(document) ; xml.close() ; } // 7、操作XML文件属性 给***加ISBN: 传智播客 public static void test7(Document document) throws Exception{ //获得根节点 Element root = document.getRootElement() ; //element拿到子节点,必须一级一级拿 List<Node> list = root.elements("书") ; //拿到第一本书 Node firstBook = (Node)list.get(0) ; ((Element)firstBook).addAttribute("ISBN", "传智播客") ; //保存到硬盘上 XMLWriter xml = new XMLWriter(new FileOutputStream("src/book.xml"),OutputFormat.createPrettyPrint()) ; xml.write(document) ; xml.close() ; } }
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 书架 SYSTEM "book.dtd">
<书架>
<书>
<书名>Java从入门到精通</书名>
<作者>明日科技</作者>
<售价>78</售价>
</书>
<书>
<书名>JavaWeb整合开发王者归来</书名>
<作者>刘景华</作者>
<售价>98</售价>
</书>
<书 ISBN="20170613">
<书名>JavaWeb整合开发王者归来</书名>
<!-- <售价>98</售价> -->
<作者>刘景华</作者>
<售价>200</售价>
<批发价>70</批发价>
<批发价>70</批发价>
</书>
</书架>
package dom4j.parser; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.UnsupportedEncodingException; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; public class Dom4j_ParserXMLByXPath { public static void main(String[] args) throws DocumentException, IOException { //获取解析器 SAXReader sr = new SAXReader(); //加载文档 Document document = sr.read("src/book.xml"); // getElement(document); // changeElementText(document); // addElement(document); // addBrotherElement(document); deleteElement(document); addAttribute(document); } //1、得到某个具体的节点内容 : 得到Java从入门到精通的作者:明日科技 public static void getElement(Document document){ //查找指定节点--作者 明日科技 注意脚标从1开始 Node node = document.selectSingleNode("书架/书[1]/作者"); //输出打印作者 System.out.println(node.getText()); } //2、修改某个元素节点的主体内容 : 将javaWeb2的售价改为200 public static void changeElementText(Document document) throws IOException{ Node node = document.selectSingleNode("书架/书[3]/售价"); //设置标签文本 node.setText("200"); //保存到硬盘上 XMLWriter xw = new XMLWriter(new FileOutputStream("src/book.xml")); xw.write(document); xw.close(); } //3、向指定元素节点中增加子元素节点: 给javaWeb2的售价加子节点: 内部价: 30 public static void addElement(Document document) throws IOException{ //获取指定节点 Element node = (Element) document.selectSingleNode("书架/书[3]/售价"); node.addElement("内部价").setText("30"); //写入到硬盘 XMLWriter xw = new XMLWriter(new FileOutputStream("src/book.xml")); xw.write(document); xw.close(); } //4、向指定元素节点上增加同级元素节点: 给javaWeb2的售价加同级节点:"批发价:70" public static void addBrotherElement(Document document) throws IOException{ //获取指定节点 Element node = (Element) document.selectSingleNode("书架/书[3]"); //添加子节点 node.addElement("批发价").setText("70"); //写入到硬盘 XMLWriter xw = new XMLWriter(new FileOutputStream("src/book.xml")); xw.write(document); xw.close(); } // 5、删除指定元素节点 : 把内部价删除 public static void deleteElement(Document document) throws IOException{ //获取节点 Node node = document.selectSingleNode("书架/书[3]/售价/内部价"); //通过相对路径删除节点 node.getParent().remove(node); //写入硬盘 XMLWriter xw = new XMLWriter(new FileOutputStream("src/book.xml")); xw.write(document); xw.close(); } //7、操作XML文件属性 给javaweb2加ISBN: 20170613 public static void addAttribute(Document document) throws IOException{ Element node = (Element) document.selectSingleNode("书架/书[3]"); node.addAttribute("ISBN", "20170613"); //写入到硬盘 XMLWriter xw = new XMLWriter(new FileOutputStream("src/book.xml")); xw.write(document); xw.close(); } }
综合练习:

<?xml version="1.0" encoding="UTF-8"?>
<exam>
<student examid="222" idcard="111">
<name>张三</name>
<location>沈阳</location>
<grade>89</grade>
</student>
<student examid="444" idcard="333">
<name>李四</name>
<location>大连</location>
<grade>97</grade>
</student>
</exam>
package domain; public class Student { private String name ; private String examid ; //准考证号 private String idcard ; //身份证号 private String location ; //地址 private float grade ; //考试分数 public String getName() { return name; } public void setName(String name) { this.name = name; } public String getExamid() { return examid; } public void setExamid(String examid) { this.examid = examid; } public String getIdcard() { return idcard; } public void setIdcard(String idcard) { this.idcard = idcard; } public String getLocation() { return location; } public void setLocation(String location) { this.location = location; } public float getGrade() { return grade; } public void setGrade(float grade) { this.grade = grade; } @Override public String toString() { // TODO Auto-generated method stub return "Student [name=" + name + ", examid=" + examid + ", idcard=" + idcard + ", location=" + location + ", grade=" + grade + "]"; } }
package util; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.UnsupportedEncodingException; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; public class Dom4jUtils { //加载XML public static Document loadXML(File file){ SAXReader sr = new SAXReader(); Document document = null; try { document = sr.read(file); } catch (DocumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } return document; } //写入到硬盘 public static boolean writeXML(Document document){ XMLWriter xw; try { xw = new XMLWriter(new FileOutputStream("src/exam.xml")); xw.write(document); xw.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } return true; } }
package dao.impl; import domain.Student; public interface StudentDao { /** * 功能是添加学生到XML文档中 * @param student 要添加的对象 * @return true表示添加成功,FALSE添加失败 */ public boolean add(Student student) ; /** * 通过准考证号查询学生 * @param examId 准考证号 * @return 查到了返回此对象,否则返回null */ public Student findStudentByExamId(String examId) ; /** * 根据姓名删除学生 * @param name 姓名 * @return 删除成功返回true, 否则返回false */ public boolean deleteByName(String name) ; }
package dao; import java.io.File; import java.util.List; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.Node; import util.Dom4jUtils; import dao.impl.StudentDao; import domain.Student; public class StudentDaoImpl implements StudentDao { @Override public boolean add(Student student) { //加载XML文件 File file = new File("src/exam.xml"); Document document = Dom4jUtils.loadXML(file); //拿到根节点 Element root = document.getRootElement(); //添加学生节点 Element studentNode = root.addElement("student").addAttribute("examid",student.getExamid()).addAttribute("idcard", student.getIdcard()); //添加节点 studentNode.addElement("name").setText(student.getName()); studentNode.addElement("location").setText(student.getLocation()); studentNode.addElement("grade").setText(Float.toString(student.getGrade())); //保存到硬盘 Dom4jUtils.writeXML(document); return true; } @Override public Student findStudentByExamId(String examId) { //加载XML文件 File file = new File("src/exam.xml"); Document document = Dom4jUtils.loadXML(file); //获取指定的student节点,通过XPath寻找 Node node = document.selectSingleNode("/exam/student[@examid='" + examId + "']"); //判断假如节点对象不为null,说明存在,此时将此节点及子节点,存入对象 if(node != null){ Element el = (Element) node; Student student = new Student(); student.setName(el.elementText("name"));//elementText方法是拿到子节点的文本内容 student.setLocation(el.elementText("location")); student.setGrade(Float.parseFloat(el.elementText("grade"))); student.setExamid(examId); student.setIdcard(el.valueOf("@idcard")); return student; } return null; } @Override public boolean deleteByName(String name) { //加载XML文件 File file = new File("src/exam.xml"); Document document = Dom4jUtils.loadXML(file); //拿到所有的name节点 List<Node> list = document.selectNodes("//name"); //遍历节点,进行比较 for (int i = 0; i < list.size(); i++) { if(list.get(i).getText().equals(name)){ //说明存在这个student Node node = list.get(i); //爷爷节点删除儿子节点 node.getParent().getParent().remove(node.getParent()); //写入到硬盘 Dom4jUtils.writeXML(document); return true; } } return false; } }
package view; import java.util.Scanner; import dao.StudentDaoImpl; import dao.impl.StudentDao; import domain.Student; //人和程序交互的界面(view) public class StudentTest { public static void main(String[] args) { System.out.println("添加学生(a),查找学生(b),删除学生(c)"); Scanner sc = new Scanner(System.in); System.out.println("请输入操作类型:"); //定义一个变量作为操作类型 String type = sc.next(); //创建一个学生操作类的对象 StudentDao dao = new StudentDaoImpl(); //判断操作类型 //假如是添加操作 if("a".equalsIgnoreCase(type)){ //添加学生 Student student = new Student(); System.out.println("请输入学生姓名:"); //将传入的学生姓名设置为对象属性值 student.setName(sc.next()); System.out.println("请输入学生准考证号:"); student.setExamid(sc.next()); System.out.println("请输入身份证号:"); student.setIdcard(sc.next()); System.out.println("请输入地址: "); student.setLocation(sc.next()); System.out.println("请输入分数: "); student.setGrade(sc.nextFloat()); //添加到XML中 boolean flag = dao.add(student); if (flag) { System.out.println("添加成功!"); } else { System.out.println("系统吗,请待会再试!"); } }else if ("b".equalsIgnoreCase(type)) { System.out.println("请输入要查询的学生的学号:"); String examId = sc.next(); Student student = dao.findStudentByExamId(examId); System.out.println(student); }else if ("c".equalsIgnoreCase(type)) { System.out.println("输入您要删除的学生姓名:"); String name = sc.next(); boolean flag = dao.deleteByName(name); if (flag) { System.out.println("恭喜您已成功删除!"); } else { System.out.println("对不起,未查询到要删除的学生,请检查您的输入!"); } } } }