今天主要完成了北京市政百姓信件分析实战。
Spark方面只是安装了Flume,以及尝试使用套接字流作为DSteam的数据源。
启动NetCat作为套接字的监听模式,这样在端口9999就能和spark互联。
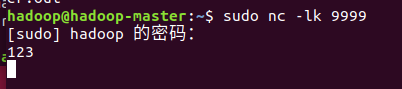
值得一提,nc -l 9999 虽然也是适用的,-k是为了可以保持多个连接,所以应该还是必要的。
编写DSteam代码并作为接受数据的一方。
import findspark findspark.init() import sys from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: network_wordcount.py <hostname> <port>", file=sys.stderr) exit(-1) conf = SparkConf().set("spark.task.cpus", "2") sc = SparkContext(appName="PythonStreamingNetworkWordCount", master="spark://hadoop-master:7077", conf=conf) ssc = StreamingContext(sc, 1) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) counts.pprint() ssc.start() ssc.awaitTermination()
其中 lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) 为使用了启动变量,所以在设置Parameters:
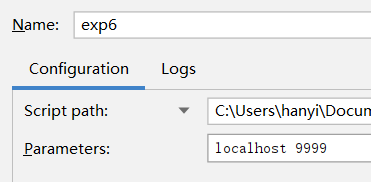
值得一提,我在代码里面加了 conf = SparkConf().set("spark.task.cpus", "2") 这么一句话,是因为在我第一次运行的时候发现程序卡在了中途的阶段,因为任务需求多个核心来处理但我默认只设置了1颗核心,所以加上这句话保险。但这样做的同时需要设置worker端的核心数量(因为我只有一个worker),只需要在spark-env.sh中加入export SPARK_WORKER_CORES=4 就可以了,核心数量视情况可以提升或减少,但为了任务正常运行需要至少2。
运行结果:

可以看到程序每秒都会监听消息。
另外明天尝试Flume作为数据源并且把结果保存到文件系统中。