---参考http://www.cnblogs.com/wishyouhappy/p/3700683.html
--案例1 学生选课
--创建表
create table STU(
id number not null,
name varchar2(255)
);
create table course(
id number not null,
coursename varchar2(255)
);
create table s_c(
sid number,
cid number,
score number
);
--插入数据
insert into STU(ID,NAME) values(1,'wish');
Insert into STU(ID,NAME) values (2,'rain');
Insert into STU(ID,NAME) values (3,'july');
Insert into STU(ID,NAME) values (4,'joey');
Insert into COURSE(ID,COURSENAME) values(1,'MATH');
Insert into COURSE(ID,COURSENAME) values(2,'English');
Insert into COURSE(ID,COURSENAME) values(3,'Japanese');
Insert into COURSE(ID,COURSENAME) values(1,'Chinese');
Insert into S_C(SID,CID,SCORE) values(1,1,80);
Insert into S_C (SID,CID,SCORE) values (1,2,90);
Insert into S_C (SID,CID,SCORE) values (2,4,100);
Insert into S_C (SID,CID,SCORE) values (4,4,90);
Insert into S_C (SID,CID,SCORE) values (4,1,100);
Insert into S_C (SID,CID,SCORE) values (4,3,80);
Insert into S_C (SID,CID,SCORE) values (4,2,80);
Insert into S_C (SID,CID,SCORE) values (2,1,90);
Insert into S_C (SID,CID,SCORE) values (2,4,100);
Insert into S_C (SID,CID,SCORE) values (3,1,60);
--查询,将学生的所有成绩查出来
with vt as
(select s.id,s.name,c.coursename,sc.score from stu s, course c, s_c sc where s.id=sc.sid and c.id=sc.cid)
select * from vt order by id;
--案例2图书查阅
--创建表 book
create table book(
bookId varchar2(30), --图书总编号
sortid varchar2(30), --分类号
bookname varchar2(100), --书名
author varchar2(30), --作者
publisher varchar2(100),--出版单位
price number(6,2) --价格,总共允许6个字符长,称为宽度。后面2是保留小数点后面两位,称为精度。
);
--创建表 reader
create table reader (
cardId varchar2(30), --借书证号
org varchar2(100), --单位
name varchar2(100), --姓名
gender varchar2(2), --性别
title varchar2(30), --职称
address varchar2(100) --地址
);
--创建表 borrow
create table borrow(
cardId varchar2(30), --借书证号
bookId varchar2(30), --图书总编号
borrowDate varchar2(30) --借阅时间
);
--插入数据-reader
insert into reader(cardid, org, name,gender, title, address)
values ('xxx','A','wish','1','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('uuu','A','luna','1','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('vvv','B','harry','1','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('www','C','chander','2','professor','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('yyy','A','joey','2','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('zzz','B','richard','2','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('OOO','A','micheal','2','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('ppp','A','richal','2','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('abp','A','michal','2','student','bupt');
insert into reader(cardid, org, name,gender, title, address)
values ('ccp','A','mike','2','student','bupt');
--插入数据-book
insert into book (bookId,sortid,bookname,author,publisher,price)
values ('aaa','a1','gone with the wind','CA','renmin','103');
insert into book (bookId,sortid,bookname,author,publisher,price)
values ('bbb','a2','the little prince','CB','jixie','30');
insert into book (bookId,sortid,bookname,author,publisher,price)
values ('ccc','a3','the ordinary world','CC','renmin','130');
insert into book (bookId,sortid,bookname,author,publisher,price)
values ('ddd','a4','the little women','CA','dianzi','110');
--插入数据-borrow
insert into borrow(cardid,bookid,borrowdate) values('xxx','aaa','2014-4-29');
insert into borrow(cardid,bookid,borrowdate) values('xxx','bbb','2014-4-29');
insert into borrow(cardid,bookid,borrowdate) values('xxx','ccc','2014-4-28');
insert into borrow(cardid,bookid,borrowdate) values('yyy','ccc','2014-4-28');
insert into borrow(cardid,bookid,borrowdate) values('yyy','ddd','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('yyy','aaa','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('zzz','bbb','2014-4-28');
insert into borrow(cardid,bookid,borrowdate) values('zzz','ddd','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('zzz','aaa','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('uuu','bbb','2014-4-28');
insert into borrow(cardid,bookid,borrowdate) values('uuu','ddd','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('uuu','aaa','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('uuu','ccc','2014-4-26');
insert into borrow(cardid,bookid,borrowdate) values('vvv','bbb','2014-4-28');
insert into borrow(cardid,bookid,borrowdate) values('vvv','ddd','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('www','aaa','2014-4-27');
insert into borrow(cardid,bookid,borrowdate) values('www','ccc','2014-4-26');
select * from book;
select * from reader;
select * from borrow;
--查询A单位借阅图书的读者人数和人员详细信息
--人数
--公用表达式GET
/*
with <name of you cte>(<column names>)
as(
<actual query>
)
select * from <name of your cte>
*/
--count(1) 指定返回第一列的值的数目
--EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
--exists : 强调的是是否返回结果集,不要求知道返回什么
--exists将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
with vt1 as
(select cardid from reader where reader.org='A')
select count(1) from vt1 where exists (select cardid from borrow where borrow.cardid=vt1.cardid);
--详细信息
with vt1 as
(select cardid,name,org from reader where reader.org='A')
select cardid,name,org from vt1 where exists (select cardid from borrow where borrow.cardid=vt1.cardid);
with vt1 as
(select cardid,name,org from reader where reader.org='A')
select cardid,name,org from vt1 where exists(select cardid from borrow where borrow.cardid=vt1.cardid);
--查询借书证号尾字符为'p'的读者
--模糊查询: %表示任意0个或多个字符,_: 表示任意单个字符。
select cardid,name,org from reader where cardid like '%p';
--查询名字以m开头的读者,‘1’显示为女,‘2’显示为男
/*
SELECT <myColumnSpec> =
CASE
WHEN <A> THEN <somethingA>
WHEN <B> THEN <somethingB>
ELSE <somethingE>
END
*/
select cardid, name, org,
case when gender='1' then '女' when gender='2' then '男' else '其他' end gender
from reader where name like 'm%';
select cardid,name,org,
case when gender='1' then '女' when gender='2' then '男' else '其他' end gender
from reader where name like 'm%';
--2014年2-4月借过书的读者
--查询满足条件的读者(仅包含cardid)--未去重
select * from borrow;
select cardid from borrow where borrowdate between '2014-2-1'and '2014-5-1';
--to_date(date,'格式'),把字符串转换为数据库中的日期类型转换函数;
--to_char(date,'格式'),是把日期或数字转换为字符串
--日期
--年 yyyy yyy yy year
--月 month mm mon month
--日+星期 dd ddd(一年中第几天) dy day
--小时 hh hh24
--分 mi
--秒 ss
--方法1-3(未去重)
--方法1
select cardid,borrowdate from borrow where to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy')='2014'
and to_char(to_date(borrowdate,'yyyy-mm-dd'),'mm')>='02'
and to_char(to_date(borrowdate,'yyyy-mm-dd'),'mm')<='04';
--方法2
select cardid, borrowdate from borrow where to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy')='2014' --查询
and to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy-mm')>='2014-02'
and to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy-mm')<='2014-04';
--方法3
select cardid, borrowdate from borrow where to_date(borrowdate,'yyyy-mm-dd hh24:mi:ss') between
to_date('2014-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and
to_date('2014-05-01 00:00:00','yyyy-mm-dd hh24:mi:ss');
select cardid,borrowdate from borrow where to_date(borrowdate,'yyyy-mm-dd hh24:mi:ss') between
to_date('2014-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and to_date('2014-05-01 00:00:00','yyyy-mm-dd hh24:mi:ss');
--查询+去重
--关键词 DISTINCT 用于返回唯一不同的值。
select distinct cardid from borrow where to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy')='2014'
and to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy-mm')>='2014-02'
and to_char(to_date(borrowdate,'yyyy-mm-dd'),'yyyy-mm')<='2014-04';
select distinct cardid from borrow where to_date(borrowdate,'yyyy-mm-dd hh24:mi:ss') between
to_date('2014-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and
to_date('2014-05-01 00:00:00','yyyy-mm-dd hh24:mi:ss');
--3)查询+去重+读者姓名等信息
select * from borrow;
with vi as
(select distinct cardid from borrow where to_date(borrowdate,'yyyy-mm-dd hh24:mi:ss') between
to_date('2014-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and
to_date('2014-05-01 00:00:00','yyyy-mm-dd hh24:mi:ss'))
select cardid ,name from reader where vi.cardid=reader.cardid;
SQL Alias(别名)
通过使用 SQL,可以为列名称和表名称指定别名(Alias)。
使用表名称别名
SELECT po.OrderID, p.LastName, p.FirstName
FROM Persons AS p, Product_Orders AS po
WHERE p.LastName='Adams' AND p.FirstName='John'
别名使查询程序更易阅读和书写。
Alias 实例: 使用一个列名别名
SELECT LastName AS Family, FirstName AS Name
FROM Persons
查询出的列名为别名
##列的别名 alias 可以考虑使用一对""
SELECT employee_id emp_id,last_name "my name",salary AS "sal"
FROM employees;#列举了别名的三种写法
where详解
group详解
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer
对相同的Customer进合并分组
having详解
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
HAVING SUM(OrderPrice)<2000;
order by;limit使用-
---ASC:升序(默认),DESC:降序。ORDER BY 语句默认按照升序对记录进行排序;limit在语句的最后,起到限定作用。
select * from t_book order by id desc limit 1,10;
select * from t_book order by id desc limit 3;
新创建的三个表结构
多表查询
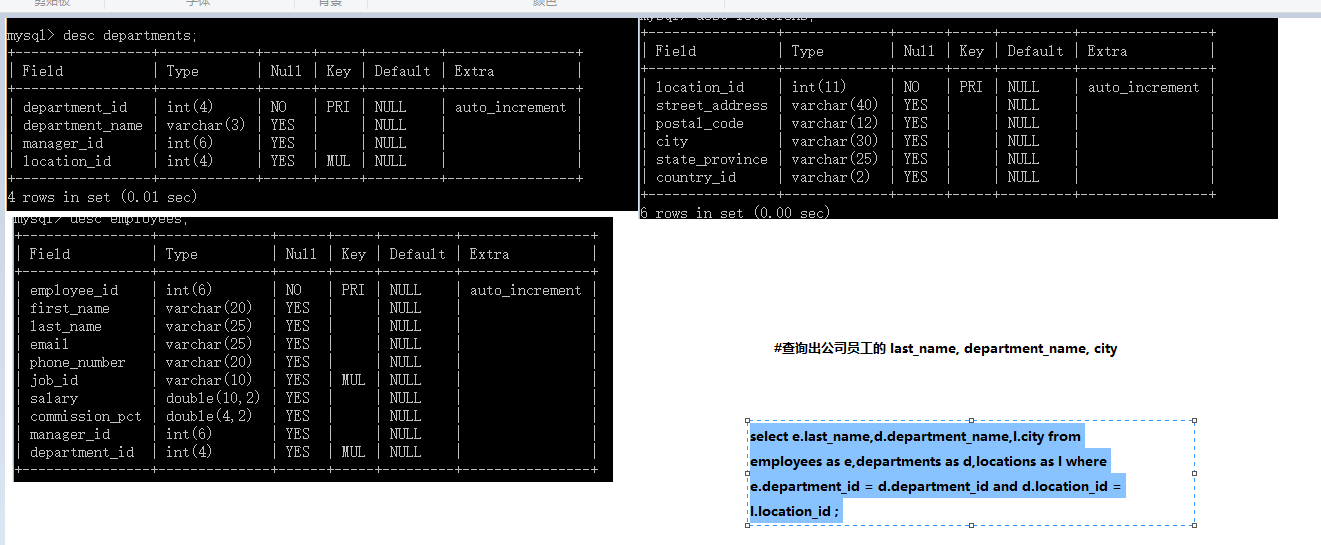
#为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件。
select d.department_name,e.email from departments as d ,employees as e where d.department_id = e.department_id;

#结论:连接 n个表,至少需要 n-1个连接条件。
#非等值连接
SELECT e.last_name,e.salary,j.grade
FROM employees e,job_grades j
WHERE e.`salary` BETWEEN j.`LOWEST_SAL` AND j.`HIGHEST_SAL`;
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
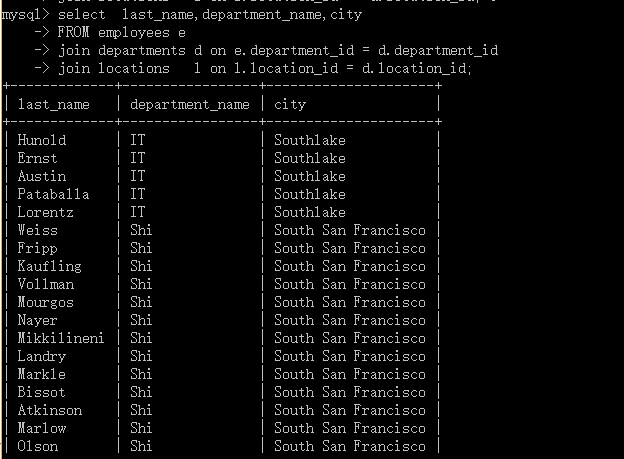
SELECT last_name,department_name,city FROM employees e,departments d,locations l WHERE e.`department_id` = d.`department_id` AND d.`location_id` = l.`location_id`;
select last_name,department_name,city FROM employees e join departments d on e.department_id = d.department_id join locations l on l.location_id = d.location_id;
上面两者效果一样
自连接
在employees中的每一个员工都有自己的mgnager(经理),并且每一个经理自身也是公司的员工,自身也有自己的经理。下面last_name 为 ‘Chen’ 的员工的 manager 的名字
这里涉及到一个表中的两层查询,用自连接方便快捷。
#查询出 last_name 为 ‘Chen’ 的员工的 manager 的名字 #方法一: #非自连接 SELECT employee_id,last_name,manager_id FROM employees WHERE last_name = 'Chen'; SELECT last_name,employee_id FROM employees WHERE employee_id = 108; #方法二 SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name FROM employees emp,employees mgr WHERE emp.`manager_id` = mgr.`employee_id` AND emp.`last_name` = 'Chen';
下面插入一篇写得很好的文章,引用来理解外连接(左右)。
http://blog.csdn.net/jiuqiyuliang/article/details/10474221
知道了连接查询的概念之后,什么时候用连接查询呢?
一般是用作关联两张或两张以上的数据表时用的。看起来有点抽象,我们举个例子,做两张表:学生表(T_student)和班级表(T_class)。
T_student T_class


连接标准语法格式:
SQL-92标准所定义的FROM子句的连接语法格式为:
FROM join_table join_type join_table[ON (join_condition)]
其中join_table指出参与连接操作的表名,连接可以对同一个表操作,也可以对多表操作,对同一个表操作的连接又称做自连接。join_type 指出连接类型。join_condition指连接条件。
连接类型:
连接分为三种:内连接、外连接、交叉连接。
内连接(INNER JOIN)
使用比较运算符(包括=、>、<、<>、>=、<=、!>和!<)进行表间的比较操作,查询与连接条件相匹配的数据。根据比较运算符不同,内连接分为等值连接和不等连接两种。
1、等值连接
概念:在连接条件中使用等于号(=)运算符,其查询结果中列出被连接表中的所有列,包括其中的重复列。
- <span style="font-size:18px;"><span style="font-family:System;">
- select * from T_student s,T_class c where s.classId = c.classId
- 等于
- select * from T_student s inner join T_class c on s.classId = c.classId</span></span>

2、不等连接
概念:在连接条件中使用除等于号之外运算符(>、<、<>、>=、<=、!>和!<)
- <span style="font-size:18px;"><span style="font-family:System;">
- select * from T_student s inner join T_class c on s.classId <> c.classId</span></span>

外连接
外连接分为左连接(LEFT JOIN)或左外连接(LEFT OUTER JOIN)、右连接(RIGHT JOIN)或右外连接(RIGHT OUTER JOIN)、全连接(FULL JOIN)或全外连接(FULL OUTER JOIN)。我们就简单的叫:左连接、右连接和全连接。
1、左连接:
概念:返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值。
- <span style="font-size:18px;"><span style="font-family:System;">
- select * from T_student s left join T_class c on s.classId = c.classId</span></span>

总结:左连接显示左表全部行,和右表与左表相同行。
2、右连接:
概念:恰与左连接相反,返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值。
- <span style="font-size:18px;"><span style="font-family:System;">
- select * from T_student s right join T_class c on s.classId = c.classId</span></span>

总结:右连接恰与左连接相反,显示右表全部行,和左表与右表相同行。
3、全连接:
概念:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值
- <span style="font-size:18px;"><span style="font-family:System;">
- select * from T_student s full join T_class c on s.classId = c.classId</span></span>

总结:返回左表和右表中的所有行。
交叉连接(CROSS JOIN):也称迪卡尔积
概念:不带WHERE条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积(例如:T_student和T_class,返回4*4=16条记录),如果带where,返回或显示的是匹配的行数。
1、不带where:
- <span style="font-size:18px;"><span style="font-family:System;">
- select *from T_student cross join T_class
- ‘等于
- select *from T_student, T_class</span></span>
结果是:

总结:相当与笛卡尔积,左表和右表组合。
2、有where子句,往往会先生成两个表行数乘积的数据表,然后才根据where条件从中选择。
- select * from T_student s cross join T_class c where s.classId = c.classId
- (注:cross join后加条件只能用where,不能用on)
---------------------------------------------------------------------------------------------------------------
# Sql : DML(insert / delete / update / select) DDL DCL # SELECT 列名1,列名2,组函数 # FROM 表1,表2 # WHERE 表的连接条件 AND 过滤条件 # GROUP BY 列名1,列名2 # HAVING 包含分组函数的过滤条件 # ORDER BY ... ASC/DESC, ... ASC/DESC; # SELECT 列名1,列名2,组函数 # FROM 表1 JOIN 表2 # ON 表的连接条件 # WHERE 过滤条件 # GROUP BY 列名1,列名2 # HAVING 包含分组函数的过滤条件 # ORDER BY ... ASC/DESC, ... ASC/DESC;
#子查询 #谁的工资比 Abel 高? #方式一: SELECT salary FROM employees WHERE last_name = 'Abel'; SELECT last_name,salary FROM employees WHERE salary > 11000; #方式二: SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
#返回job_id与141号员工相同,salary比143号员工多的员工 #姓名,job_id 和工资 # 写子查询的技巧:①从外往里写 ---老司机 ②从里往外写 ---新手 SELECT last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 );
#多行子查询 #查询出与名字中包含字符'a'和'n'相同部门员工的last_name,department_id SELECT last_name,department_id FROM employees WHERE department_id IN ( SELECT DISTINCT department_id FROM employees WHERE (last_name LIKE '%a%n%' OR last_name LIKE '%n%a%' ) AND department_id IS NOT NULL );
having的出现是为了替代where后面不能使用函数。
#2.创建表 #方式一:"白手起家" CREATE TABLE emp1( emp_id INT, emp_name VARCHAR(15), salary DOUBLE(10,2) ); SELECT * FROM emp1; DESC emp1; #主键:要去主键作用的列非空且唯一 #标准: CREATE TABLE emp2( emp_id INT AUTO_INCREMENT, emp_name VARCHAR(15), salary DOUBLE(10,2), PRIMARY KEY(emp_id)#emp_id是主键 ); #方式二:基于现有的表,创建新的表 #新表的字段的数据类型,存储范围与原表是一致的 CREATE TABLE emp3 AS SELECT employee_id,last_name,department_id FROM employees; CREATE TABLE emp4 AS SELECT employee_id emp_id,last_name,department_id FROM employees; DESC emp2; DESC emp3; DESC employees; SELECT * FROM emp3; SELECT * FROM emp4; #复制一个employees. CREATE TABLE employees_copy AS SELECT * FROM employees; SELECT * FROM employees_copy; DESC employees_copy; DESC employees; #复制一个employees,但是表中没有数据 CREATE TABLE employees_copy_blank AS SELECT * FROM employees #where department_id = 5000000; WHERE 1=2;#加一个不可能的条件 SELECT * FROM employees_copy_blank;
COMMIT;#提交数据 #设置数据是不可自动提交的。 SET autocommit = FALSE; #delete from employees_copy; TRUNCATE TABLE employees_copy; SELECT * FROM employees_copy; ROLLBACK;#回滚数据,默认回滚到最后一次commit之后。注意:rollback 增对的是数据的增(insert into)删(delete)改(update) DDL:CREATE / ALTER / TRUNCATE / DROP / DCL:COMMIT / ROLLBACK
# 注意点:1.增删改是支持数据的回滚。 COMMIT; SET autocommit = FALSE; #一系列的增删改操作:..,..,... COMMIT;/ ROLLBACK; #2.修改和删除操作,在某些情况下,可能执行不成功! #原因:约束的存在 UPDATE employees SET department_id = 55 #因为不存在55号部门 WHERE department_id = 80; SELECT * FROM departments; DELETE FROM departments WHERE department_id = 70;#因为在员工表中存在70号部门的员工
#msyql分页 #查询工资最高的前10名员工的信息:top 10 SELECT last_name,salary FROM employees ORDER BY salary DESC #分页 (写在order by的后面) #limit 0,10; LIMIT 20,10;#21-30段数据:第3页 #公式:limit (pageNo - 1) * pageSize , pageSize;