Weilin Huang——【TIP2015】Text-Attentional Convolutional Neural Network for Scene Text Detection)
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 问题讨论
- 总结与收获点
- 作者补充信息
- 参考文献

-
方法概括
- 使用改进版的MSER(CE-MSERs,contrast-enhancement)提取候选字符区域;
- 使用新的CNN(text-CNN,结合了像素级信息,字符多类标签,字符二类标签的监督信息来训练text-attentional的CNN)来过滤非文字区域;
- 将字符串成字符串再切成单词(参考文献1,文献2的方法,不是文章重点)
-
创新点和贡献
- idea的出发点:
- 人类判断一个patch块中是否是文字一般分为三步:第一,将文字区域和背景区分开(像素级分割,如果文字和背景几乎全粘连在一起,根本无法判断是否是字),第二,判断抠下来的该区域是什么字(字符识别,如果一个字我们认得是'a',那么我们就很有信心这是一个字,而不是随便什么符号。试想如果一个完全不认识字的人他判断是否是字的准确率肯定不会比认字的人高,正是因为他缺乏了这个字符类别信息),第三,才是做出决策,判断是否是字或者噪声。
- MSER的两个缺点是:第一,容易受背景干扰,造成字符断裂,和背景粘连等问题;第二,字符和背景的对比度很低,不能因为“stable”而被MSER检测出来,导致漏检。因此,为解决这两个问题,可以增强文字区域的局部对比度,在增强对比度的map上去提取MSER就可以提高召回率。

如果不认识这些字,那么很难判断这到底是否真是'字'还是瞎写的笔画
-
- 创新点:
- 提出了对比度增强版的MSER,提高召回率
- 提出了基于多任务学习的text-CNN模型,并介绍了一种新的训练机制,将低级的像素级信息(分割问题),到高级的字符多类信息(62类字符识别问题),字符与非字符信息(2类字符分类问题)融合到一个text-CNN模型中,实现了具有更强的分辨性和鲁棒性的text detector.
- 创新点:
-
方法细节
-
text-CNN
- 网络结构图
-

-
-
- 3个任务
-
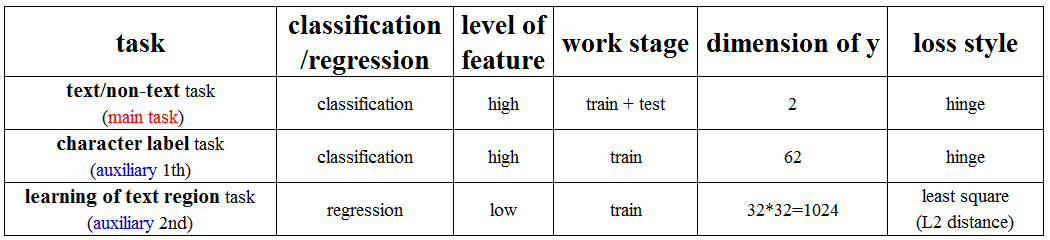
-
-
- 3个任务的损失函数(从上到下分别是binary,label,region)
-

-
-
-
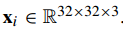 ,
,
 ,
,
 ,
,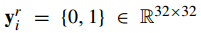
-

-
-
-
-
- 总的损失函数:
-

-
-
- 3个任务网络结构:
- pixel-level segementation task: Conv1 → Conv2 → Deconv1 → Deconv2 → loss (5) 【两个卷积,两个去卷积】
- character label task: Conv1 → Conv2 → Pool2 → Conv3 → Fc1 → Fc2 → loss (4) 【三个卷积,一个池化,两个全连接】
- text/non-text task: Conv1 → Conv2 → Pool2 → Conv3 → Fc1 → Fc2 → loss (3) 【三个卷积,一个池化,两个全连接】
- 池化层设计的原因
- 池化层本身是不可逆转的,即在去卷积是无法找回原来的信息的,所以在去卷积前不能使用池化层,因此只能在第二层之后才接池化层
- 第三层卷积后图像已经很小,故没必要再用池化层
- 实验证明了使用池化层:性能没有降低,速度得到提高
- 训练过程
- pre-train:label task和region task分别按10:3(损失函数比,λ1 =1,λ2 =0.3)进行训练,采用的库为合成数据库charSynthetic,迭代次数为30k次
- train:label task和main task分别按3:10(λ1 =0.3)进行训练,采用的库为真实库charTrain,迭代次数为70k
- 之所以这样训练的原因:三种任务使用的特征不同(region task使用的特征是pixel-level,属于低级特征),收敛的速度也不同。如果region task训练次数和main task一样多,会导致过拟合。第一阶段训练两个任务之后,模型参数已经将像素级的信息记录下来了。下图为训练阶段三种任务的损失函数随迭代次数的变化情况。
- 3个任务网络结构:
-

-
-
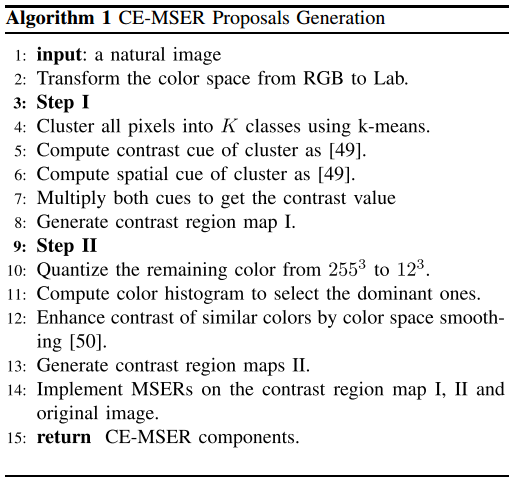
CE-MSERs
- 算法步骤(主要:
- Step1 : 利用对比度线索和空间线索聚类(文献3),生成对比度区域图map1
- Step2 : 利用颜色空间平滑(文献4),生成对比度区域图map2
- 在原图,map1,map2上分别使用MSER
- 算法步骤(主要:
-

-
实验结果
- 实验效果证明多任务效果(c)比传统的CNN(a),只使用一个额外任务,字符识别任务(b)更好

-
- 实验证明采用本文的Text-CNN学到了能区分字符和非字符的关键特征

-
- ICDAR2015

-
- ICDAR2011 (CE-MSERs比MSERs好,用三种task训练的text-CNN比单任务,双任务的饿更好)

-
- ICDAR2013
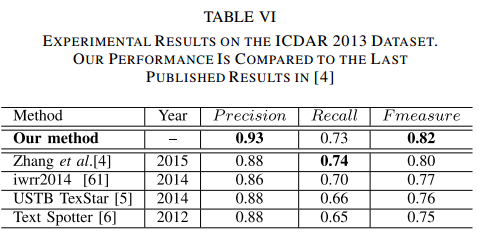
-
- MSRA-TD500

-
问题讨论
- 使用池化层的优劣?
- 优点:减少参数和模型的复杂性
- 缺点:丢失了空间信息,且池化层是不可逆转的
- 为什么region task是回归问题?
- 为什么region task和label task在训练的时候用,测试的时候不用?
- CE-MSER的实现?
- 为什么label task是62类,而不是63类(包含噪声类)?
- 对于负样本,region task的groundTruth中的mask怎么做?label task中的负样本类别是多少?
- 使用池化层的优劣?
-
作者和相关链接



-
总结与收获点
- CE-MSER提供了一个思路,可以增强对比度来提高召回率,但实现方法不是很好。本身MSER就相对耗时,还需要在增强对比度的map上再做两次MSER,显然时间开销太大了。更好的方法应该是去改MSER的内部算法,修改“stable”的含义或者对每个component做一定对比度增强的处理再提取等等。
- 多任务学习的训练方法可以参考这篇文章的思路:不同任务共享某些层
- 把像素级信息,字符类别级信息融合到检测中做的想法很可取
-
参考文献
- W. Huang, Y. Qiao, and X. Tang, “Robust scene text detection with convolution neural network induced MSER trees,” in Proc. 13th Eur. Conf. Comput. Vis. (ECCV), 2014, pp. 497–511.
- C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, “Detecting texts of arbitrary orientations in natural images,” in Proc. IEEE Comput. Vis. Pattern Recognit. (CVPR), Jun. 2012, pp. 1083–1090.
- H. Fu, X. Cao, and Z. Tu, “Cluster-based co-saliency detection,” IEEE Trans. Image Process., vol. 22, no. 10, pp. 3766–3778, Oct. 2013.
- M. M. Cheng, G. X. Zhang, N. J. Mitra, X. Huang, and S. M. Hu, “Global contrast based salient region detection,”2011 in Proc. IEEE Comput. Vis. Pattern Recognit. (CVPR), Jun. 2011, pp. 409–416.