ES是啥?
ES就是一个开源的搜索引擎 也是一个分布式文档数据库
可以在极短的时间内存储、搜索和分析大量的数据。
ES基本属性:
字段
ES中,每个文档,其实是以json形式存储的。而一个文档可以被视为多个字段的集合。
映射
每个类型中字段的定义称为映射。例如,name字段映射为String。
索引
索引是映射类型的容器。 一个ES的索引非常像关系型世界中的数据库,是独立的大量文档集合
ES各属性对应关系数据库
关系数据库 -> 表名 -> 表结构 -> 一条记录 -> 一个字段
ES -> 索引index - 类型type(1-n) -> 映射apping -> 文档document -> 字段field
ES索引简单原理: 采用倒排索引
Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term
Term Dictionary(单词字典):顾名思义,它里面维护的是Term,可以理解为Term的集合
Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
Posting List(倒排列表):以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。
如果类比现代汉语词典的话,那么Term就相当于词语,Term Dictionary相当于汉语词典本身,Term Index相当于词典的目录索引)
通过 单词索引 找到单词在单词字典中的位置,通过单词字典进而找到Posting List倒排列表,有了倒排列表就可以根据ID找到文档.
(本质:通过单词找到对应的倒排列表,根据倒排列表中的倒排项进而可以找到文档记录)
查询结果分析:
took:本次操作花费的时间,单位为毫秒。
timed_out:请求是否超时
_shards:说明本次操作共搜索了哪些分片
hits:搜索命中的记录
hits.total : 符合条件的文档总数 hits.hits :匹配度较高的前N个文档
hits.max_score:文档匹配得分,这里为最高分
_score:每个文档都有一个匹配度得分,按照降序排列。
_source:显示了文档的原始内容。
ES聚合
桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法
ES分布式架构原理
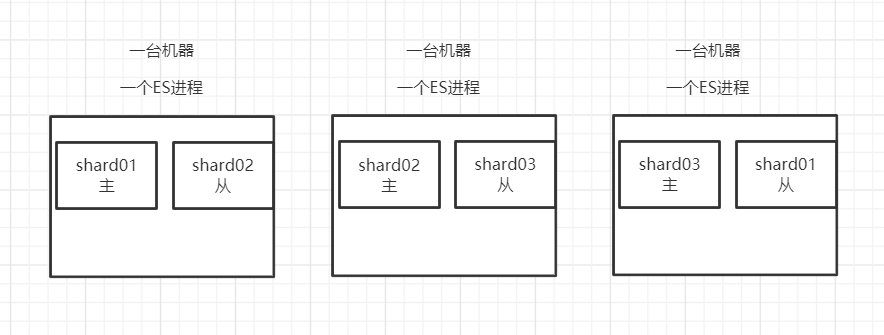
shard就是ES索引存储具体数据的地方,一个索引对应多个shard
多个shard存储在不同的机器上
每个shard只放索引的一部分数据
每个shard的副本replic放在其他机器上(shard的主体primary和副本replic分开存) 保证了一定程度的高可用
ES写入数据原理:
从客户端写入到shard的全过程:

- 客户端随机找一个ES集群节点当作协调节点,写数据
- 协调节点将数据 根据doc id的哈希路由,写入分配的主shard并同步到从shard
- shard将数据写入内存buffer
- 内存buffer每一秒钟refresh一次将数据刷进OScache缓存,一份sagementfile,一份translog日志 (translog日志的作用 有点类似于redis的RDB文件,用于ES宕机恢复数据)
- OScache缓存每5秒中刷入磁盘的translog日志文件
- 每30分钟执行一次flush操作,执行一次commit,强制将内存buffer和OScache数据刷入新创建一个sagmentfile文件(磁盘) 落地到磁盘,多个sagementfile会有merge操作。
数据搜索主要是从OScache中拿的,所以刚写入shard的数据要一秒后才能读到。
写入一条document数据时会产生一个doc id,查的时候根据doc id进行哈希,路由到对应的shard (doc id默认随机分配,也可以手动指定,例如订单id)
ES删除数据原理:
1.把被删除数据写入.del文件(磁盘),被.del文件标识的被认为已删除
2.当sagmentfile文件过多时ES会产生merge操作,将多个segmentfile合成一个,如果.del标识了删除的数据 merge后不会产生在新的segmentfile.
ES根据doc id读取数据过程:
选ES集群的任一台机器当作协调节点
协调节点根据要查找的doc id 哈希路由到对应的节点的shard,
查到结果返还给协调节点,协调节点返还给客户端。
ES检索数据过程:
客户端发送读取请求到任一台机器当作协调节点,协调节点发送给所有机器所有shard,
每个shard都会返回结果,协调节点拿到所有shard返回的匹配的结果,再次筛选最匹配的那些document,返还给客户端.
每次查询完都会暂时将数据存入cache中,再次
ES在数据量很大的情况下如何优化查询(保证搜索性能):
主要思想:最大限度利用cache的高效率进行查询(磁盘查询效率太低)
(1) 合理利用ES+Hbase/MySQL结合来查询(Hbase对海量数据在线存储)
把重要的检索字段存成ES索引 (例如gid,订单id,订单金额,订单时间,订单说明...)
其余不作为检索条件的字段存在Hbase/Mysql
用ES根据条件快速查出gid
再用gid去Hbase/MySQL查出全部字段
(2) 数据预热
每隔一段时间将热门关键数据写个程序去查一下,主动从磁盘写入到cache中
(3) 冷热分离
水平拆分,将很热的数据单独写进一个索引,将冷数据热数据拆成两个单独索引,放在不同机器上。
(5) 单索引查,不要join多个索引查,效率非常低 (想办法导入ES的时候直接将要Join的表直接导成一个索引)
(4) 分页性能 (深度分页,性能越差)
查第100页的10条数据/第1001-1010,由于ES分布式的存储,必须去每台机器每个shard都查1000条,全部返回到协调节点,合并排序后再取出1001-1010。
解决:合理利用Scroll游标
scroll会一次性获取所有数据的快照,每次翻页通过游标移动获取下一页,分页性能大很多。、
scroll不能乱跳,只能顺序向下翻
ES生产集群部署架构
模板:每个索引的数据大概有多少,每个索引大概分多少shard
ES集群部署5台机器,每台6核64G,总内存320G,分8个shard
ES集群每天增量2000万条,大约500M,每月大约6亿条 15G数据