Hue Web应用的架构
Hue 是一个Web应用,用来简化用户和Hadoop集群的交互。Hue技术架构,如下图所示,从总体上来讲,Hue应用采用的是B/S架构,该web应用的后台采用python编程语言别写的。大体上可以分为三层,分别是前端view层、Web服务层和Backend服务层。Web服务层和Backend服务层之间使用RPC的方式调用。

Hue整合大数据技术栈架构
由于大数据框架很多,为了解决某个问题,一般来说会用到多个框架,但是每个框架又都有自己的web UI监控界面,对应着不同的端口号。比如HDFS(50070)、YARN(8088)、MapReduce(19888)等。这个时候有一个统一的web UI界面去管理各个大数据常用框架是非常方便的。这就使得对大数据的开发、监控和运维更加的方便。
Hue几乎可以支持所有大数据框架,包含有HDFS文件系统对的页面(调用HDFS API,进行增删改查的操作),有HIVE UI界面(使用HiveServer2,JDBC方式连接,可以在页面上编写HQL语句,进行数据分析查询),YARN监控及Oozie工作流任务调度页面等等。Hue通过把这些大数据技术栈整合在一起,通过统一的Web UI来访问和管理,极大地提高了大数据用户和管理员的工作效率。这里总结一下Hue支持哪些功能:
默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
基于文件浏览器(File Browser)访问HDFS
基于Hive编辑器来开发和运行Hive查询
支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
支持基于Impala的应用进行交互式查询
支持Spark编辑器和仪表板(Dashboard)
支持Pig编辑器,并能够提交脚本任务
支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
支持Job设计器,能够创建MapReduce/Streaming/Java Job
支持Sqoop 2编辑器和仪表板(Dashboard)
支持ZooKeeper浏览器和编辑器
支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
使用sentry基于角色的授权以及多租户的管理.(Hue 2.x or 3.x)
Hue操作数据
使用Hue可以以图形界面的形式创建solr集合,导入数据到Solr中,并建立数据查找索引。
提供了人性化的UI页面把数据从文件系统(比如Linux文件系统、HDFS)导入Hive中,导入的时候可以把数据转换成相应的Hive表,导入完成之后就可以直接使用Hive SQL查询刚刚导入的数据了。[^import-hive]
使用Hue以图形界面的形式操作HDFS,包括导入、移动、重命名、删除、复制、修改、下载、排序、查看其中的数据等等操作。
Hue集成了Sqoop组件,这样就可以通过Hue把数据从其他文件系统批量导入到Hadoop中,或者从Hadoop中导出。[^http://blog.cloudera.com/blog/2013/11/sqooping-data-with-hue/]
可以通过图形界面的方式操作HBase,可以导入数据到HBase中,可以通过UI界面进行相关的增加、删除和查询操作。[^http://blog.cloudera.com/blog/2013/09/how-to-manage-hbase-data-via-hue/]
Hue数据查询分析
通过Hue使用Hive进行数据分析
Hue提供了非常人性化的Hive SQL编辑界面,编辑好SQL语句之后就可以直接查询数据仓库中的数据,还可以保存SQL语句、查看和删除历史SQL语句。对于所查询出来的数据,可以下载以及以多种图表的形式展示它们。通过Hue,用户还可以通过自定义函数然后在Hue中通过SQL引用执行。

通过Hue使用Impala进行数据分析
和Hive一样,Hue提供了类似的图形界面用来使用Impala进行数据查询分析。形式和Hive的类似。如下图所示:
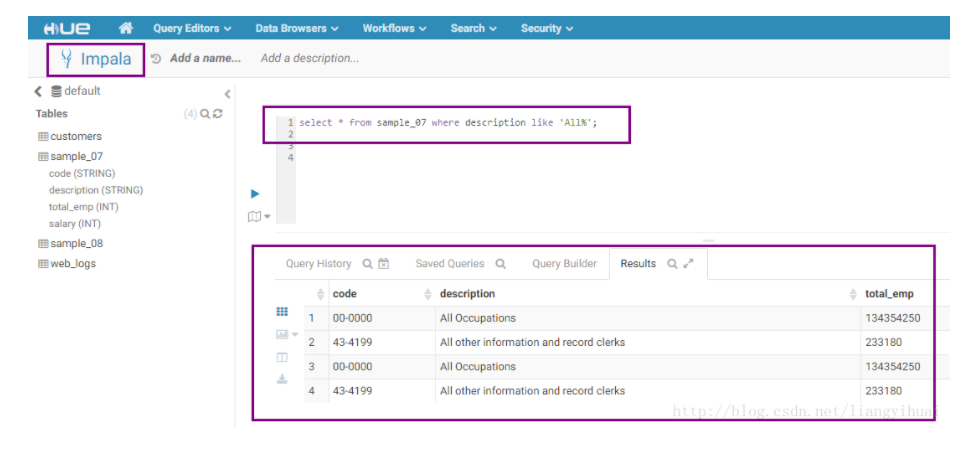
类似于Hive和Impala在Hue中编辑器,Pig的功能和表达式可以直接在Hue中进行编辑和执行等操作。用户可以自定义函数和参数,编辑器能够自动补全Pig关键字、别名和HDFS路径,还支持语法高亮,编写好脚本之后点击一下就可以提交执行。用户可以查看到执行的进度、执行的结果和日志。
Hue数据可视化
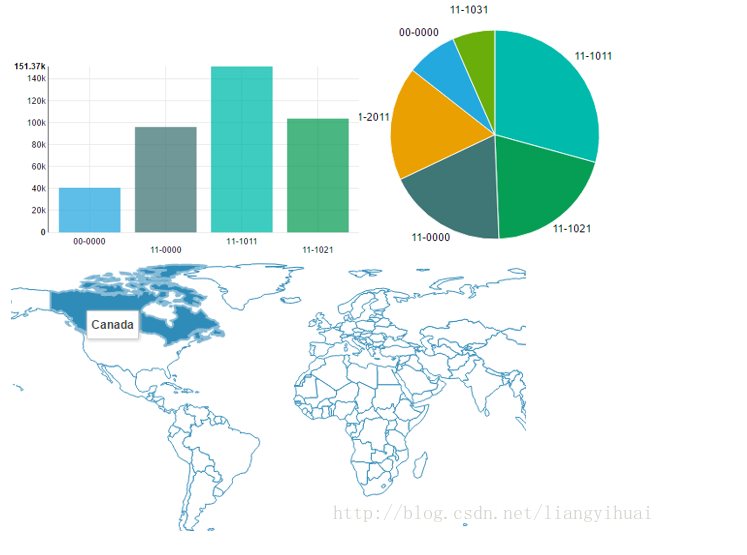
Hue使用Web图形界面的可视化的形式展示所查询出来的数据,展示的形式有表格、柱状图、折线图、饼状图、地图等等。这些可视化功能的使用非常简单。比如,使用Hive SQL查询出相关的数据出来之后,我想以柱状图的形式展示它们,我只需要勾选横坐标和纵坐标的字段就可以显示出我想要的柱状图。
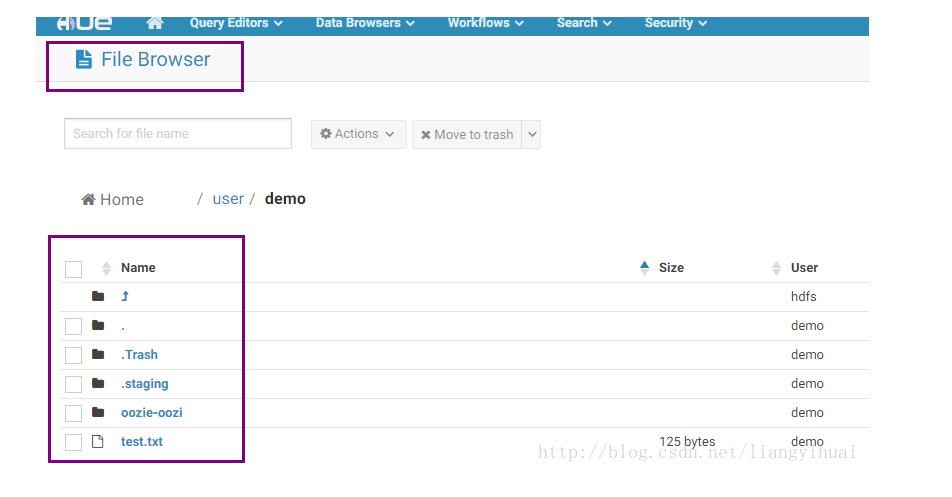
Hue提供了可视化的HDFS文件系统,使得对HDFS中的数据的操作完全能够通过UI界面完成,包括查看文件中的内容。
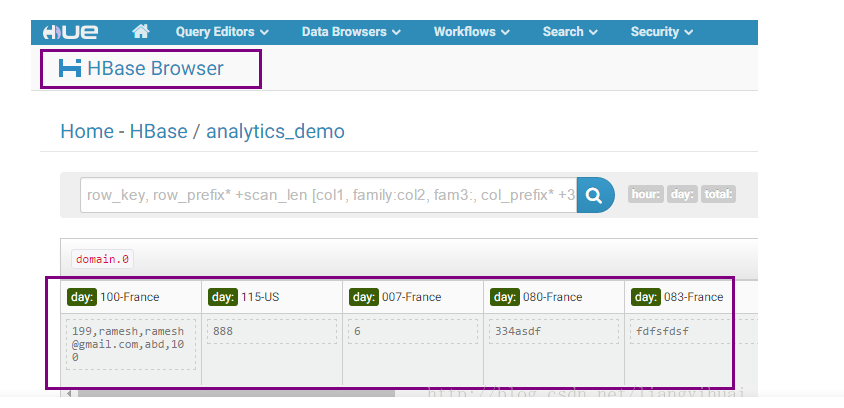
类似地,Hue提供了可视化的UI界面操作HBase中的数据。包含了数据展示,各个版本的数据的查看和其他编辑操作的UI界面,提供了展示数据的排序方式等等。
下图表示,编辑HBase数据的可视化界面
Hue提供了用户自定义仪表盘(Dashboard)展示数据的功能。数据的来源是Solr这个搜索引擎。通过拖拽的方式设置仪表盘(也就是数据展示的方式),有文本框、时间表、饼状图、线、地图、HTML等组件。图表支持实时动态更新。设置仪表盘的全部操作都是通过图形界面完成的,对于不同的展示方式,用户可以选择相应的字段,整个过程非常简单方便。保存好刚刚配置好的仪表盘之后,我们可以选择分享给相应权限的用户,拥有不同的权限的用户将看到不同的内容。[^http://gethue.com/hadoop-search-dynamic-search-dashboards-with-solr/]
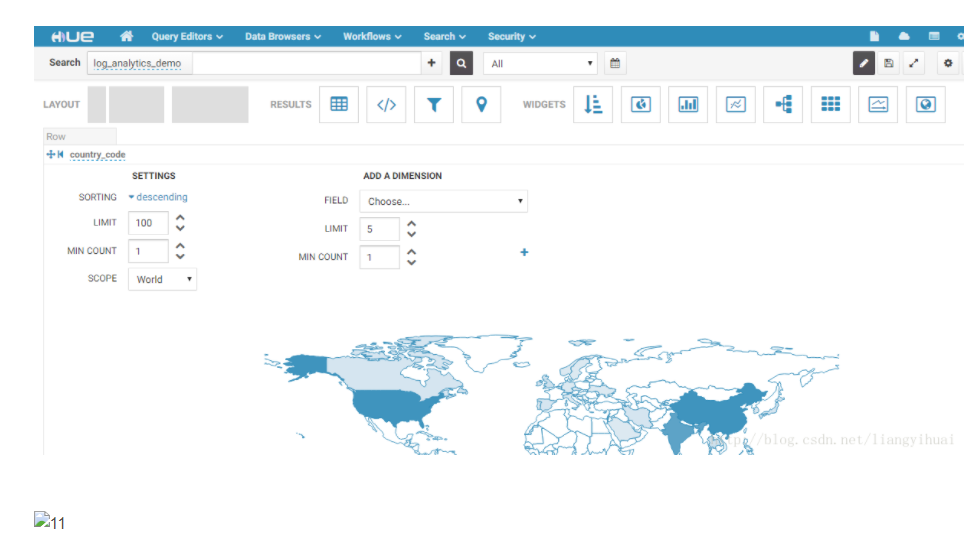
上图表示表盘设置中的以地图的方式展示国家码。
Hue对任务调度的可视化
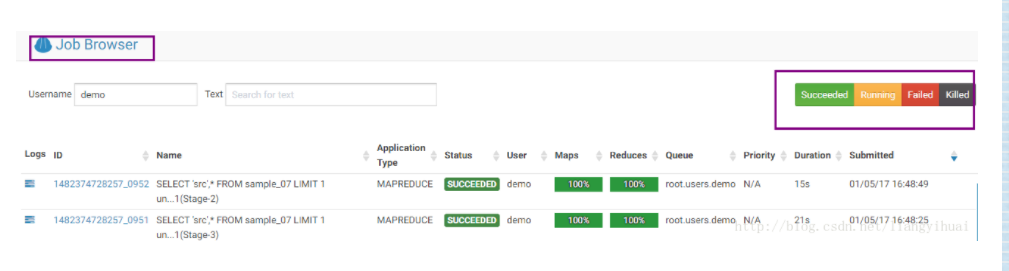
Hue以可视化的方式向用户展示任务的执行情况,具体包括任务的执行进度、任务的执行状态(正在运行、执行成功、执行失败、被killed),任务的执行时间,还能够显示该任务的标准输出信息、错误日志、系统日志等等信息。还可以查看该任务的元数据、向用户展示了正在运行或者已经结束的任务的详细的执行情况。除此之外,Hue还提供了关键字查找和按照任务执行状态分类查找的功能。
Hue权限控制
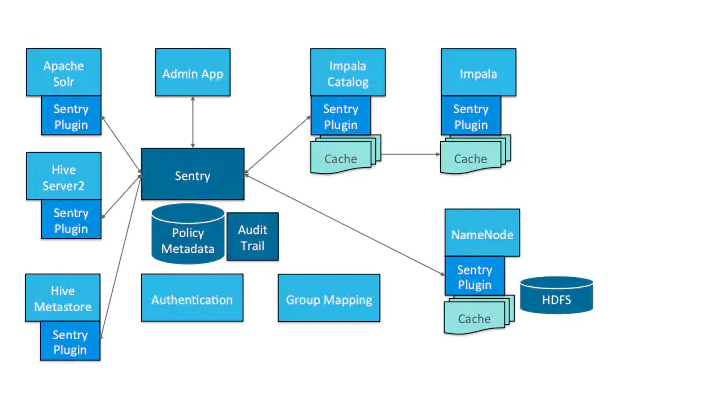
Hue在HueServer2中使用了Sentry进行细粒度的、基于角色的权限控制。这里的细粒度是指,Sentry不仅仅可以给某一个用户组或者某一个角色授予权限,还可以为某一个数据库或者一个数据库表授予权限,甚至还可以为某一个角色授予只能执行某一类型的SQL查询的权限。Sentry不仅仅有用户组的概念,还引入了角色(role)的概念,使得企业能够轻松灵活的管理大量用户和数据对象的权限,即使这些用户和数据对象在频繁变化。除此之外,Sentry还是“统一授权”的。具体来讲,就是访问控制规则一旦定义好之后,这些规则就统一作用于多个框架(比如Hive、Impala、Pig)。举一个例子:我们为某一个角色或者用户组授权只能进行Hive查询,我们可以让这个权限不仅仅作用于Hive,还可以是Impala、MapReduce、Pig和HCatalog。
Sentry的优势还体现在它本身对Hadoop生态组件的集成。如下图所示,我们可以使用Sentry为Hadoop中的多个框架进行权限控制。
原文链接:https://blog.csdn.net/liangyihuai/article/details/54137163