装饰器、
装饰器实际就是一个函数
定义:在不改变内部代码和调用方式的基础上增加新的功能
了解装饰器需要了解3个内容:
1、函数即变量
2、高阶函数
1)、把一个函数名当作实参传给另一个函数
2)、返回值中包含函数名
例1:
def test(): #定义函数test print('this is test func') #打印(下方没有调用,所以不打印) def deco(func): #定义函数deco,赋个形参(=test) print('this is deco') #打印 func() #调用test函数 return func #返回值 res = deco(test) #调用test的内存地址
print(res) #打印test内存地址
运行结果: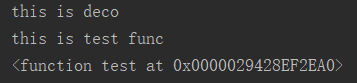
例2:
import time def test(): time.sleep(3) #睡3秒,期间不占内存 print('this is test func') def deco(func): #func = test start_time = time.time() #开始执行的时间戳 func() #test() end_time = time.time() #结束执行的时间戳 print('this is run %s' % (end_time-start_time)) #执行所用的时间 return func #把test的内存地址返回给函数 res = deco(test) print(res)
运行结果:
3、嵌套函数
嵌套函数,调用时需要,一层一层的调用
def test(): def deco(): print('this is test') deco() test()
运行结果:
装饰器练习
例1:普通装饰器
给下面的函数添加新功能
def test(): print('this is test') test()
需要定义一个新函数进行添加
def deco(func): #形参 def wrapper(): func() print('新功能') #用打印代替新功能 return wrapper
原函数调用新函数
def test(): print('this is test') result = deco(test) #定义变量接收repper的内存地址 result()
为了不使原函数的调用方式更改,将变量result 换成 test接收
def test(): print('this is test') test = deco(test) test()
为了不更改原函数代码,用@放在原函数前,来代替函数中的“rest = drco(test)”
def deco(func): def wrapper(): func() print('新功能') return wrapper @deco def test(): print('this is test') test()
运行结果: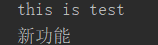
例2:带参数的装饰器
如果原函数带传参数的情况
def test(name): print('my name is %s '% name) test('aaa')
那么添加新功能时,需要添加参数
def deco(func): def wrapper(name): #传参数 func(name) #传参数 print('新功能') return wrapper
如果原函数参数很多
def test(name, age, job): print('my name is %s, my age is %s, my job is %s'% (name, age, job)) test('aaa', 18, 'IT')
那么我们添加功能的函数时也要添加所有的参数
def deco(func): def wrapper(name, age, job): #传参数 func(name, age, job) #传参数 print('新功能') return wrapper
因为比较麻烦所以传参数的快捷方式,不用考虑参数个数
def deco(func): def wrapper(*args, **kwargs): func(*args, **kwargs) print('新功能') return wrapper @deco def test(name, age, job): print('my name is %s, my age is %s, my job is %s'% (name, age, job)) test('aaa', 18, 'IT')
运行结果:
迭代器、迭代的工具
什么是迭代:指的是一个重复的过程,每一次重复称为一次迭代,并且每一次重复的结果是下一次重复的初始值
while True: print('hello world')
上面这种方式只有重复,结果并不是下一次的初始,所以不是迭代
例:不用for循环,用while循环将下边几种数据类型逐个取出
字符串:s = 'helloworld'
列表:l = ['a','b','c','d','e']
元组:t = ('a','b','c','d','e')
字典:dict1 = {'name' : 'aaa', 'age' : 18, 'job' : 'IT'}
集合:set1 = {'a','b','c','d','e'}
文件:f = open('a.txt', 'w', encoding='utf-8')
整数:12345 (不能迭代)
1 = 0 while 1 < len(set1): print(set1[i]) i += 1
如果经过上边的循环进行测试会发现:
对于序列类型的字符串,列表,元组可以依赖于索引来迭代取值,
但是字典,集合,文件却不行,所以,python必须为我们提供一种不依赖于索引取值的方法,就是迭代器
可迭代对象
判断是否是可迭代对象
可以在pycharm软件中试验,如果有"xx.__iter__"这种用法那么就是能变成可迭代对象
加"xx.__iter__"就是把一个对象变成可迭代对象"xx.__iter__" 可以简写成 "iter(xx)"
迭代器对象
有"xx.__iter__"和"xx__next__"这两种方法的就是迭代器对象
print(f is f.__iter__()) #f是上边的文件类型
运行结果: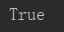 由此看出,文件类型本身就是可迭代对象
由此看出,文件类型本身就是可迭代对象
next方式取值
dict1 = {'name' : 'aaa', 'age' : 18, 'job' : 'IT'}
d_items = dict1.__iter__()
res = d_items.__next__()
res1 = d_items.__next__()
res2 = d_items.__next__()
print(res)
可以调取 res,res1,res2,分别是三个key然后就可以根据key的来调取值了,"xx.__next__()" 可以简写成 "next()"
但是它每取一个值要多一条代码,只能一个一个取,迭代器优点:同一时间在内存里只有一个值,节省内存空间
若想一起取,所以我们要采用while方式
dict1 = {'name' : 'aaa', 'age' : 18, 'job' : 'IT'}
d_items = dict1.__iter__()
while True:
res = d_items.__next__()
print(res)
因为系统会停止迭代报错
运行结果: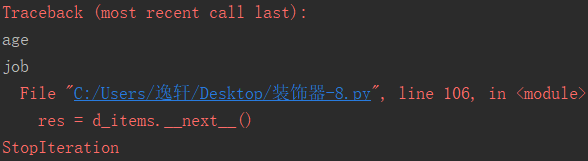
异常处理:try....except +错误
dict1 = {'name' : 'aaa', 'age' : 18, 'job' : 'IT'}
d_items = dict1.__iter__()
while True:
try:
res = d_items.__next__()
print(res)
except StopIteration:
break
运行结果: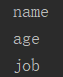 ,这样就可以取值了,
,这样就可以取值了,
通过以上的步骤,我们知道了取值的原理及过程,这个原理同样也是for循环的原理
dict1 = {'name' : 'aaa', 'age' : 18, 'job' : 'IT'}
for i in dict1: #相当于dict1.__iter__(),即变成可迭代对象
print(i)
运行结果: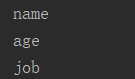
总结
可迭代对象不一定是迭代器对象
迭代器对象一定是可迭代对象