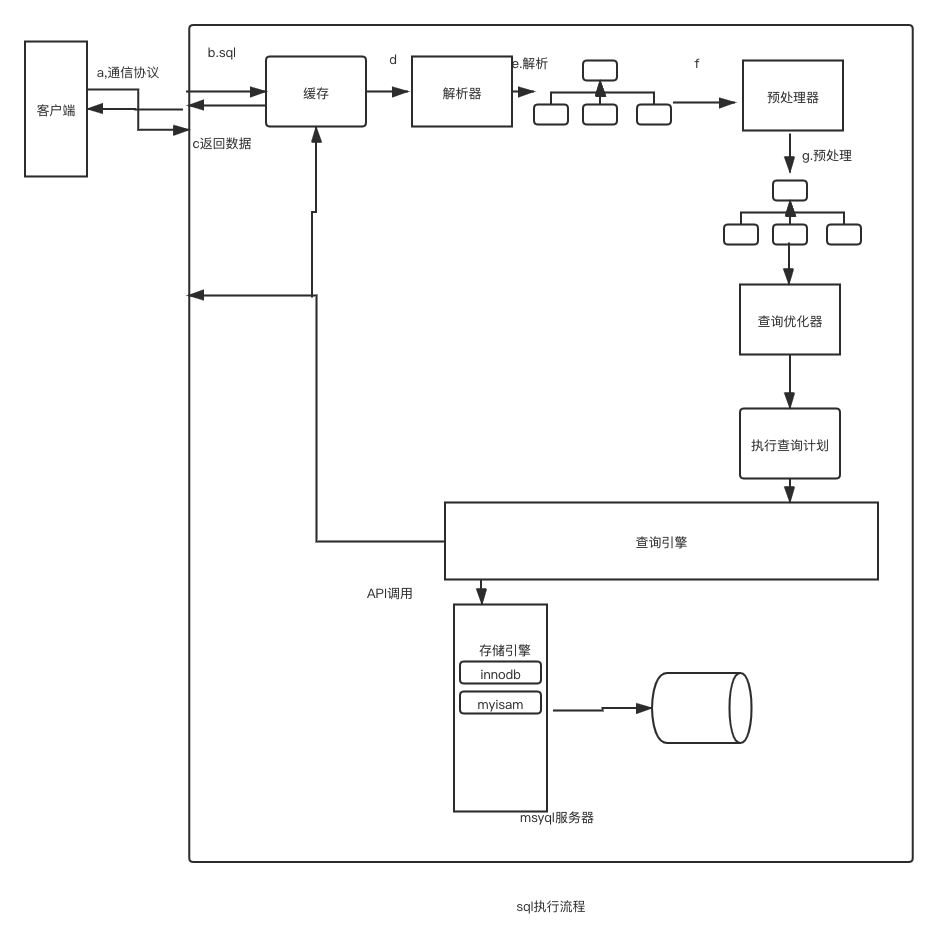
如上图所示一个sql执行的流程大致如下
- 客户端通过
半双工协议将查询发送到服务器端 - 首先经过
缓存如果缓存中有相关查询的结果,直接放回,否则进入3 - 将sql交给
解析器,构建语法树,这一步主要检测是否出现语法错误。 - 语法树交给
预处理器进一步解析,做预编译操作。主要是将要查询的表的列提取出来看看是否会有字段不存在这样的错误 - 通过
查询优化器将预处理器的结果计算出若干个计划,然后选择最优的计划 - 排队之后
查询引擎执行计划通过API调用存储引擎,最终调用到数据库拿到数据。 - 返回数据时生成新的缓存,将数据发送给客户端
MYSQL客户端/服务端通信协议
半双工 :任何一个时刻都只能是一方发送一方接受。
优点:不需要切分数据。因为只要服务器端在发客户端就得接着
缺点:不方便做流量控制。
mysql有对max_allow_packet的设置,如果一个包的大小超过了这个设置,那么就会出现异常。
https://dev.mysql.com/doc/refman/8.0/en/packet-too-large.html
这里我有一个疑问,如果有一个极大的文件需要存储到数据库呢?,
由于是半双工的协议,那么就要接收全部服务器端发送的包。如果像之前说的打开结果集读取若干行之后断开链接这个是不可取的。
方向: 实际上是服务器向客户端推送数据,所以客户端无法中断这个推送,也就是说上述打开结果集但是只选择几行,实际上还是耗费了内存的。
所以我门在设计查询的时候一定一定要做到简单高效。
线程状态
- sleep: 等待客户端发送请求
- query: 执行查询计划,或者将内容发送给客户端
- analyzing and statistics 线程正在收集统计信息
- copying to tmp table: 向临时表复制(group by, 排序,union吗,如果后面有on disk 那么说明mysql正在将一个内存临时表放在磁盘上。)
- sorting result:排序
- sending data: 发送数据,在数据量多的时候会特别耗时间。
查询缓存
根据查询SQL的hash来找的缓存,如果命中了缓存,在返回之前会检查一下数据库的权限,如果权限正确就直接返回,将不会解析sql生成执行计划等。
查询优化处理
语法解析器
将sql语句解析,生成一个解析树,会校验语法验证和解析查询。会抛出语法错误
预处理器
进一步验证解析树的合法性,比方说表上的字段不存在等等。
查询优化器
主要针对之前执行的语句,找出多种执行计划,在众多执行计划里面找出一个最优的执行计划
优化器有自己的评估逻辑,主要就是计算大致的IO次数,需要注意的是即便是使用了缓存他依旧会计算其中的IO耗时。
这就导致了:
- 如果统计信息不准确会影响他的预估。(innodb的mvcc会影响行数的统计)
- 像上面说的,执行计划的成本不一定是实际上的查询成本,即便是使用了缓存,也会计算IO时间。
- mysql的最优可能和你的不一样,简而言之,他选出来的不一定是最短的。
- mysql不考虑并发
- 不考虑成本
- 无法估算到所有的执行计划。
优化方式:
静态优化:和查询上下文无关,比方说简单的代数替换。
动态优化:和查询上下文有关,比方说利用索引来确定最值。
如下几种:
- 重新定义关联表的顺序,关联并不是总是按照关联的顺序来执行的,比方说之前的order by的字段只有在是主表字段的时候才会使用索引,而主表是优化器决定的,可能你写一个sql,有可能第一个并不是主表。
- 外链接转化成内联接:在有些条件下,外联接经过过滤查询之后就等价是内联接。
- 等价变换:对查询条件做一些简单的几何变换。
- 优化count(),max(),min(): count(): myisam。max()/min() 利用索引的有序性
- 预估并转化成常数表达式:min()对索引列执行的时候,可以转化成一个常数。,再就是类似于等值传播的优化。
mysql> explain select film.film_id, film_actor.actor_id from film inner join film_actor using(film_id) where film_id = 1;
+----+-------------+------------+------------+-------+----------------+----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+----------------+----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | const | PRIMARY | PRIMARY | 2 | const | 1 | 100.00 | Using index |
| 1 | SIMPLE | film_actor | NULL | ref | idx_fk_film_id | idx_fk_film_id | 2 | const | 10 | 100.00 | Using index |
+----+-------------+------------+------------+-------+----------------+----------------+---------+-------+------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
- 覆盖索引扫描
- 子查询优化:将自查询优化成效率更高的方式
- 提前终止。(比方说,自增id的查询你在条件里面写个负数),比方说找没有演员的表.
mysql> explain select film.film_id from film inner join film_actor using(film_id) where film_actor.film_id is null;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
1 row in set, 1 warning (0.00 sec)
- 等值传播:将一个列的过滤条件传播到另一个列
mysql> explain select film.film_id from film inner join film_actor using(film_id) where film.film_id > 500;
+----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+
| 1 | SIMPLE | film | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 500 | 100.00 | Using where; Using index |
| 1 | SIMPLE | film_actor | NULL | ref | idx_fk_film_id | idx_fk_film_id | 2 | sakila.film.film_id | 5 | 100.00 | Using index |
+----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+
2 rows in set, 1 warning (0.00 sec)
- in的优化,in不是直接使用等值查询,而是使用二分查找来优化查询效率。
统计信息
存储引擎在查询时起到的第一个作用,提供统计信息给查询引擎,查询引擎能通过这些统计信息来去做决定使用什么查询计划。
关联查询
执行逻辑:找出最外部的关联表的数据,然后使用这个数据便利去和内部查询的关联对比,如果成功就返回一条,如果内层处理完之后就找外层拿下一条接着处理。

查看执行计划:
mysql> explain extended select film.film_id from film inner join film_actor using(film_id) where film.film_id > 500;
+----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+
| 1 | SIMPLE | film | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 500 | 100.00 | Using where; Using index |
| 1 | SIMPLE | film_actor | NULL | ref | idx_fk_film_id | idx_fk_film_id | 2 | sakila.film.film_id | 5 | 100.00 | Using index |
+----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+
2 rows in set, 2 warnings (0.00 sec)
mysql> show warnings;
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 1681 | 'EXTENDED' is deprecated and will be removed in a future release. |
| Note | 1003 | /* select#1 */ select `sakila`.`film`.`film_id` AS `film_id` from `sakila`.`film` join `sakila`.`film_actor` where ((`sakila`.`film_actor`.`film_id` = `sakila`.`film`.`film_id`) and (`sakila`.`film`.`film_id` > 500)) |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
关联查询优化器
决定关联表的顺序。通常多表关联的时候可以有不同的执行顺序来获取相同的结果,关联查询优化器通过评估不同的顺序时的成本来获取一个最快的。
以下两个例子可以展示关联优化器的作用:
mysql> explain select film.film_id, film.title, film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using (film_id) inner join actor using(actor_id)G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: Using index
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.film_id
rows: 1
filtered: 100.00
Extra: NULL
3 rows in set, 1 warning (0.00 sec)
ERROR:
No query specified
mysql> explain select straight film.film_id, film.title, film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using (film_id) inner join actor using(actor_id)G;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '.film_id, film.title, film.release_year,actor.actor_id,actor.first_name,actor.la' at line 1
ERROR:
No query specified
mysql> explain select straight_join film.film_id, film.title, film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using (film_id) inner join actor using(actor_id)G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 1000
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 5
filtered: 100.00
Extra: Using index
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.actor_id
rows: 1
filtered: 100.00
Extra: NULL
3 rows in set, 1 warning (0.00 sec)
ERROR:
No query specified
使用优化器的时候只需扫描部分行就能完成工作。
不过关联多的时
候会出现关联的组合种类太多了,mysql会使用贪心算法来解决这一问题。
排序优化:
尽量使用索引来排序,file_sortings 性能差。
算法:
- 先排序要排序的字段,再根据字段去查数据(两次IO)
- 查所有列,针对排序列排序,返回结果。
一些细节:
如果orderby的字段来自关联的第一个表,那么在第一个表查出来的时候就会排序,其他的都会搞到一个临时表里面再排序。
如果排序加上limit,那么会先排序之后再计算limit,会先扫描大量的列再返回较少的列。
查询引擎
查询引擎拿到执行计划,完成整个查询。整个过程就是调用存储引擎的API完成的。
一些共有的特性都是在服务端做
返回结果到客户端
查询完毕之后会将查询发送到客户端,如果整个查询是可以被缓存的,那么就会缓存下来。
这里返回数据是逐步返回的,生成第一条结果的时候就能返回了。
优点: 服务器端无需存储太多的结果。也就不会因为要返回太多结果而消耗太多内存。
最后还是走TCP发送结果到客户端。