今天完成了老师布置的spark实验报告5的第二部分:
2.编程实现将 RDD 转换为 DataFrame
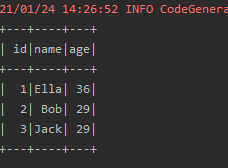
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
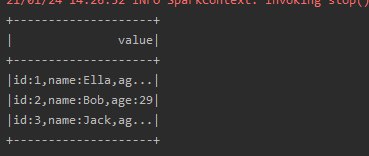
请将数据复制保存到Linux 系统中,命名为employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
代码:
package 假期实验
import org.apache.spark
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object test5_2 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("test5_2").getOrCreate()
import spark.implicits._
// val conf = new SparkConf().setMaster("local").setAppName("test5_2")
val sc = spark.sparkContext
val data = sc.textFile("G:\大数据\data\employee.txt")
val newdata = data.map(_.split(",")).map(parts => Row(parts(0), parts(1), parts(2)))
val schemaString = "id,name,age"
val fields = schemaString.split(",").map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
val stuDf = spark.createDataFrame(newdata, schema)
stuDf.printSchema()
stuDf.createOrReplaceTempView("view")
val results = spark.sql("SELECT id,name,age FROM view")
results.show()
results.map(data => "id:" + data(0) + ",name:" + data(1) + ",age:" + data(2)).show()
}
}
截图: