堆排序算法及应用
堆的性质: 1. 完全二叉树 2.堆中每个节点值都必须大于等于(或小于等于)子树中每个节点的值。
完全二叉树非常适合用数组来存储,节省空间,不需要存左右子节点的指针,通过下标就可定位左右节点和父节点。
方便理解,以一个从1开始存储的数组为例,左节点2i,右节点2i+1,父节点i/2。(如果数组下标0开始计算,则左子节点为2i+1,右子节点为2i+2,父节点为(i-1)/2)
堆存在的操作:
1. 往堆中插入一个元素
2. 删除堆顶元素
对于插入元素,需要满足堆的特性,此时需要堆化操作,即顺着节点所在路径,向上或向下,对比然后交换。
有从上到下和从下到上两种方法。
堆化操作:从下往上(插入节点)
从下往上堆化:新插入节点和父节点对比大小,不满足就交换节点。重复过程直到满足。(本文默认构造大根堆)
public class Heap {
private int[] a;
private int n; // 堆可以存储的最大数据个数
private int count; // 堆中已经存储的数据个数
public Heap(int capacity) {
a = new int[capacity + 1];
n = capacity;
count = 0;
}
public void insert(int data) {
if (count >= n) return; // 堆满了
++count;
a[count] = data;
int i = count;
while (i/2 > 0 && a[i] > a[i/2]) { // 自下往上堆化
swap(a, i, i/2); // swap()函数作用:交换下标为i和i/2的两个元素
i = i/2;
}
}
}堆化操作:从上往下(删除堆顶)
删除堆顶元素,同样需要删除之后保持堆的特性,如果还是用之前的沿路径比较父子节点,进行交换,则存在数组空洞。所以改变思路,我们可以先交换堆顶和最后一个元素,然后再采用比较父子节点的方法,重复过程直到满足。这就是从上往下的堆化方法。
public void removeMax() {
if (count == 0) return -1; // 堆中没有数据
a[1] = a[count];
--count;
heapify(a, count, 1);
}
private void heapify(int[] a, int n, int i) { // 自上往下堆化
while (true) {
int maxPos = i;
if (i*2 <= n && a[i] < a[i*2]) maxPos = i*2;
if (i*2+1 <= n && a[maxPos] < a[i*2+1]) maxPos = i*2+1;
if (maxPos == i) break;
swap(a, i, maxPos);
i = maxPos;
}
}堆化时间复杂度:
完全二叉树高度不会超过log2n,堆化是顺着节点路径比较,与树高正比,所以插入元素与删除堆顶时间复杂度为O(logn)
堆排序过程:建堆
堆排序首先需要构造堆,有两种思路
结合插入元素的思想,假设开始只有一个数据,对后续2-n个数据进行插入操作,从前往后处理数据,每个数据插入都从下往上堆化
从后往前处理数据,每个数据从上往下堆化(可参考下文代码)
/** * 构建堆 从下标1到下标n * 从后往前处理数组,每个数据都是从上往下堆化 */ private static void buildHeap(int[] a, int n) { for (int i = n / 2; i >= 1; --i) { heapify(a, n, i); } } /** * 堆化操作 将数组a中,以i开始,n结束的数组调整为大根堆 */ private static void heapify(int[] a, int n, int i) { while (true) { int maxIndex = i; if (i * 2 <= n && a[maxIndex] < a[i * 2]) { maxIndex = i * 2; } if (i * 2 + 1 <= n && a[maxIndex] < a[i * 2 + 1]) { maxIndex = i * 2 + 1; } //已经是大根堆了 if (maxIndex == i) { break; } swap(a, i, maxIndex); //指针i移动到maxIndex下标处,继续进行下层堆化 i = maxIndex; } }
建堆时间复杂度:
叶子节点不需要堆化,所以需要堆化节点从倒数第二层开始。每个节点堆化过程,比较交换的节点个数与节点高度k成正比(从下到上为从1到h的过程)。
每个非叶子节点高度求和: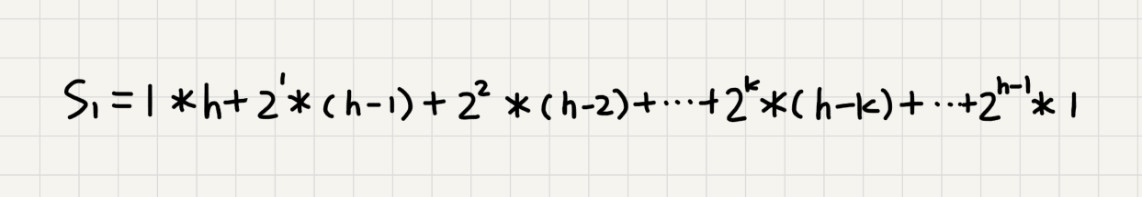
将公式左右*2,得到s2公式,并进行错位对齐相减,得到等比数列。将h=log2n代入公式,得到复杂度O(n)。
堆排序过程:排序
堆排序包括建堆排序两个过程,建堆O(n),排序O(nlogn),整体复杂度O(nlogn)。在排序过程中存在最后节点与堆顶节点互换操作,可能改变相对顺序,不是稳定排序算法。是原地排序算法。
public static void sort(int[] a) {
//1.构造大根堆
buildHeap(a, a.length - 1);
int k = a.length - 1;
while (k > 1) {
swap(a, 1, k);
--k;
heapify(a, k, 1);
}
}性能比较
实际开发中,快速排序为什么比堆排序性能好?
1.堆排序数据访问方式没快速排序友好
快速排序是顺序访问,堆排序是跳着访问。堆CPU缓存不友好。
2.同样数据,堆排序数据交换次数多于快速排序
堆排序建堆过程会打乱原有的先后顺序,有序度降低。
应用:TOPK问题
Q:从10亿搜索关键词的文件,获取热门top10
如果数据量不是这么大,我们可以通过顺序扫描,构建散列表记录关键词与次数,构造大小K的小根堆。遍历散列表,取每个关键词与次数与堆顶关键词对比,比堆顶多则删除堆顶插入,遍历完成即构造了topk小顶堆。
但是在数据量很大情况,无法将所有数据一次性加载到内存。可以根据哈希算法特点,相同数据哈希算法得到哈希值相同,将10亿关键字分片到10个文件中。如00-09对应10个空文件,哈希值对10取余分配对应文件编号。针对每个1亿的关键词的文件,利用散列表和堆求出top10。最后再把10个top10放在一起,取最多的top10。