Hadoop最底部是 Hadoop Distributed File System(HDFS),它存储Hadoop集群中所有存储节点上的文件。HDFS(对于本文)的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库。
- HDFS:对外部客户机而言,HDFS就像一个传统的分级文件系统。
- NameNode:负责管理文件系统名称空间和控制外部客户机的访问。
- DataNode:响应来自 HDFS客户机的读写请求。它们还响应来自NameNode的创建、删除和复制块的命令。
最近搞Dubbo、Zookeeper,故顺路复习一下Hadoop。
安装环境
3台CentOS7,64位,Hadoop2.7需要64位Linux,需要安装好JDK,老夫安装JDK1.7
- Master 192.168.1.244
- Slave1 192.168.1.245
- Slave2 192.168.1.246
配置SSH无密码登陆
SSH免密码登录,因为Hadoop需要通过SSH登录到各个节点进行操作,老夫用root用户,每台服务器都生成公钥,再合并到authorized_keys
- CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置,
#RSAAuthentication yes #PubkeyAuthentication yes - 输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,每台服务器都要设置,
- 合并公钥到authorized_keys文件,在Master服务器,进入/root/.ssh目录,通过SSH命令合并,
cat id_rsa.pub>> authorized_keys ssh root@192.168.1.245 cat ~/.ssh/id_rsa.pub>> authorized_keys ssh root@192.168.1.246 cat ~/.ssh/id_rsa.pub>> authorized_keys - 把Master服务器的authorized_keys、known_hosts复制到Slave服务器的/root/.ssh目录
- 完成,ssh root@192.168.1.245、ssh root@192.168.1.246就不需要输入密码了
安装Hadoop2.7
- 下载“hadoop-2.7.0.tar.gz”,放到/home/hadoop目录下
- 解压,输入命令,tar -xzvf hadoop-2.7.0.tar.gz
- 在/home/hadoop目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
- 注:安装Hadoop2.7,只在Master服务器解压,再复制到Slave服务器
Hadoop配置
涉及的配置文件如下:
hadoop-2.6.0/etc/hadoop/hadoop-env.sh
hadoop-2.6.0/etc/hadoop/yarn-env.sh
hadoop-2.6.0/etc/hadoop/core-site.xml
hadoop-2.6.0/etc/hadoop/hdfs-site.xml
hadoop-2.6.0/etc/hadoop/mapred-site.xml
hadoop-2.6.0/etc/hadoop/yarn-site.xml
1)配置hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.7.0_79
2)配置yarn-env.sh
#export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/java/jdk1.7.0_79/
3)配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.244:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
4)配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.244:9001</value>
大专栏 Hadoop2.7搭建s="nt"></property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
5)配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.244:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.244:19888</value>
</property>
</configuration>
6)配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.244:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.244:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.244:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.244:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.244:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>768</value>
</property>
</configuration>
7)配置slaves
删除默认的localhost,增加2个从节点,
192.168.0.183
192.168.0.184
8)将配置好的Hadoop复制到各个节点对应位置上
scp -r /home/hadoop 192.168.1.245:/home/
scp -r /home/hadoop 192.168.1.246:/home/
Hadoop启动
在Master服务器启动hadoop,从节点会自动启动,进入/home/hadoop/hadoop-2.7.0目录
- 初始化,输入命令,bin/hdfs namenode -format
- 全部启动sbin/start-all.sh,也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh
- 停止的话,输入命令,sbin/stop-all.sh
- 输入命令,jps,可以看到相关信息
Web访问
要先开放端口或者直接关闭防火墙
- 输入命令,systemctl stop firewalld.service
- 浏览器打开http://192.168.1.244:8088/
- 浏览器打开http://192.168.1.244:50070/
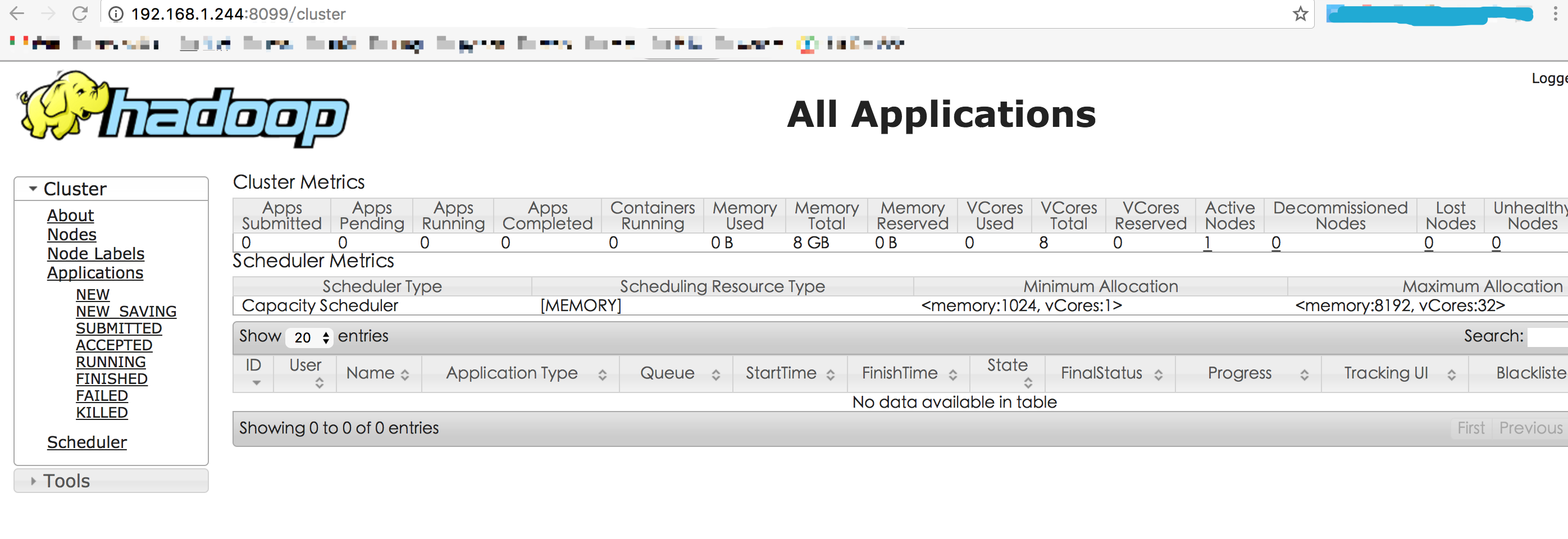
注:因老夫8088端口被占用,故使用8099端口。 ⤧ Next post 归纳数据库规范 ⤧ Previous post F5负载均衡