章节:
第一章节:CentOS 7 配置hadoop(一) 安装虚拟机(伪分布)
第二章节:CentOS 7 配置hadoop(二) 配置hdfs(伪分布)
第三章节:CentOS 7 配置hadoop(三) 配置hbase(伪分布)
第四章节:CentOS 7 配置hadoop(四) 配置hive(伪分布)
第五章节:CentOS 7 配置hadoop(五) 配置sqoop(伪分布)
第六章节:CentOS 7 配置hadoop(六) 配置flume(伪分布)
第二章CentOS 7 配置hadoop(二) 配置hdfs(伪分布)
准备 hadoop 2.6 、jdk 1.8 所需内容在第一章节 CentOS 7 配置hadoop(一) 安装虚拟机
(二) 配置hdfs
续上一章登录之后
1.修改主机名
在CentOS 7中,我们可以通过hostname命令查看当前的主机名。

我们可以通过命令“hostnamectl set-hostname 主机名”来永久修改主机名。

2.配置静态IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33

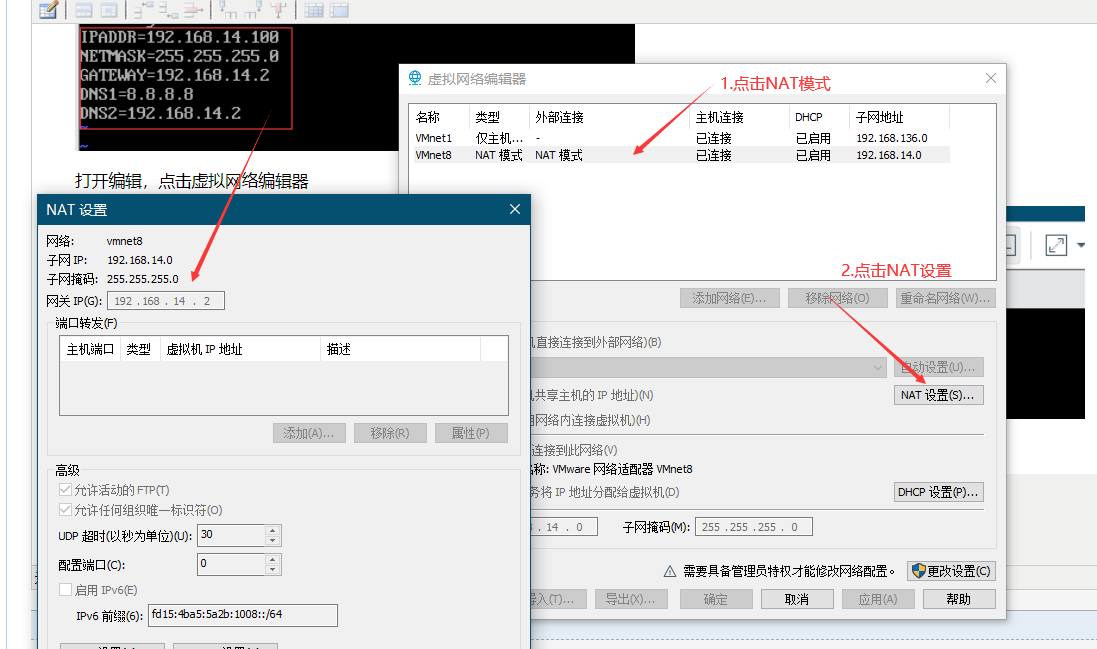
这里的红框内是在下面的NAT 设置的网络 网关 子网,其中 IPADDR 要和NAT 设置的 网关IP前三段一致 ,后一段不一样就可以
打开编辑,点击虚拟网络编辑器
注意IP的设置
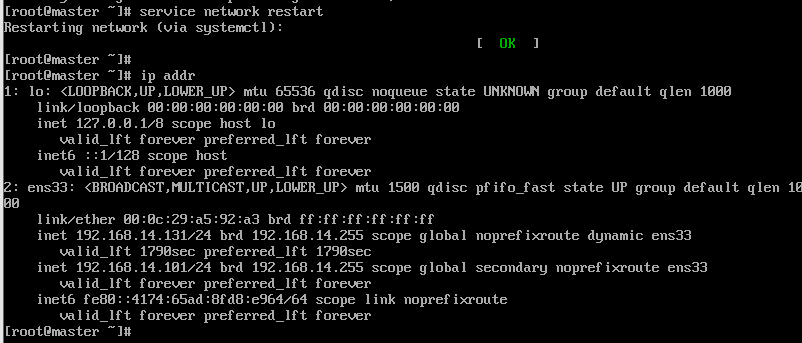
设置完记得service network restart
查看IP 指令为 ip addr
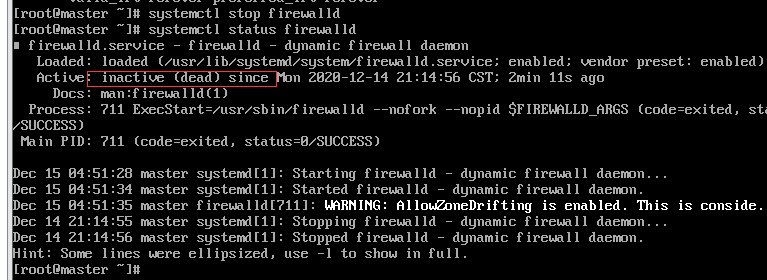
3.关闭防火墙
关闭防火墙:systemctl disable firewalld
查看防火墙:systemctl status firewalld
4.生成SSH公钥 ssh-keygen -t rsa (遇见问题直接回车)
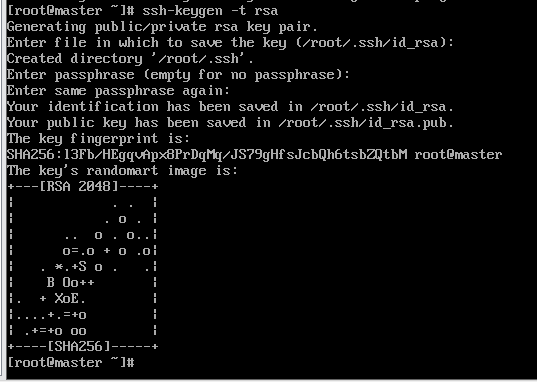
在mster的终端下输入
ssh localhost
连接本机还需要输入密码,因此我们,还需要设置master与本机的无密码连接,配置如下:
cd ~/.ssh
cat ./id_rsa.pub >> ./authorized_keys
再次输入 ssh localhost 就不需要输入密码而直接与本机连接。
重启虚拟机
5.使用 xshell工具
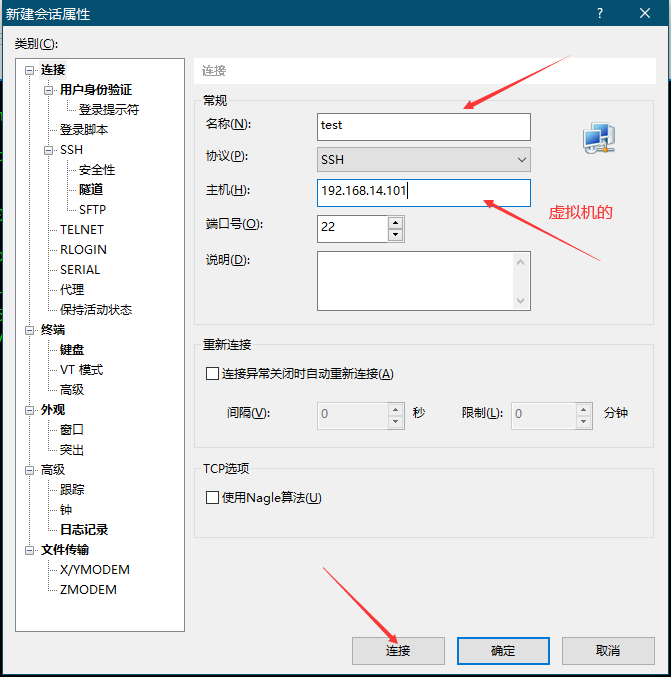
点击链接输入用户名密码
6.链接FileZilla
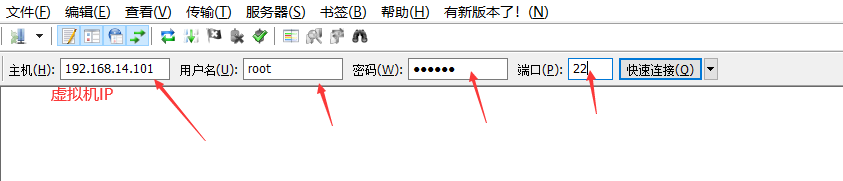
7.使用FileZilla上传文件到虚拟机 右键上传
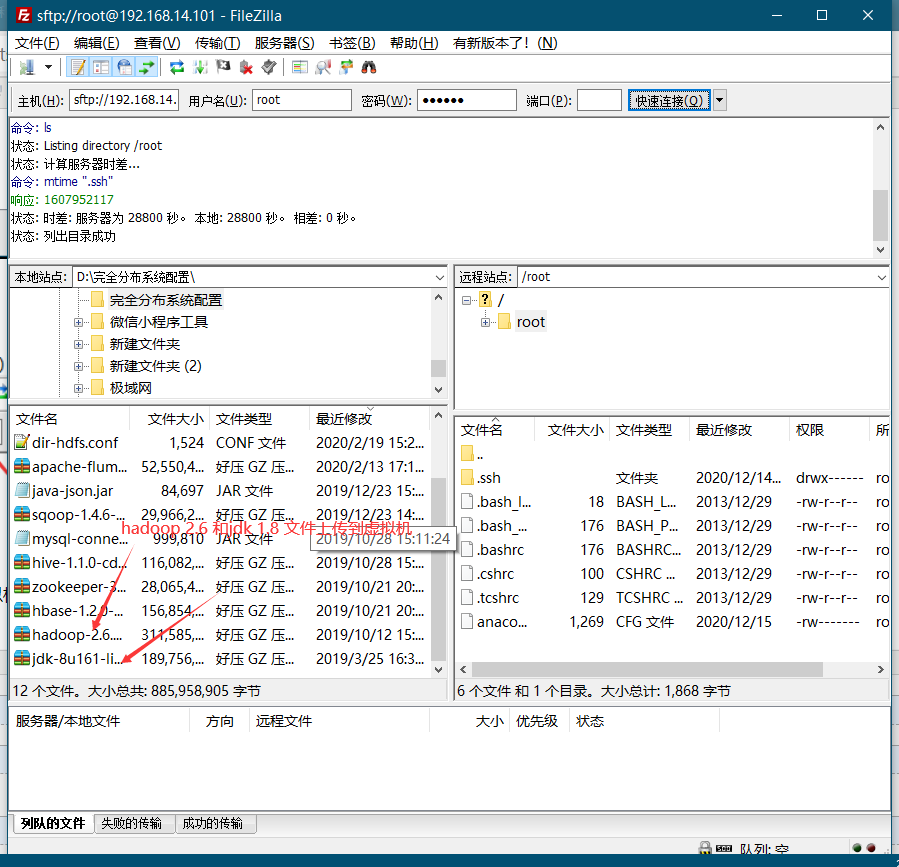
8.上传完毕到xshell工具里解压两个tar压缩包 命令 tar -xzvf 压缩包名

9.解压完成配置环境变量 vi /etc/profile
export JAVA_HOME=/root/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/root/hadoop-2.6.0-cdh5.7.0
export PATH=$PATH:$HADOOP_HOME/bin

配置完环境变量记得 source /etc/profile
10.配置hadoop 先进入 cd /root/hadoop-2.6.0-cdh5.7.0/etc/hadoop 文件目录下
1)修改hadoop-env.sh 文件
export JAVA_HOME=/root/jdk1.8.0_161
export HADOOP_HOME=/root/hadoop-2.6.0-cdh5.7.0

2)修改core-site.xml 文件
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hdfs/tmp</value>
</property>
3)修改hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/data/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/data/data</value>
</property>
4)修改mapred-site.xml文件 要先执行cp 命令(cp mapred-site.xml.template mapred-site.xml)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5)修改yarn-site.xml文件
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8080</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
6)修改slaves 文件
写入主机名(master)
11 格式化hdfs 命令hadoop namenode -format
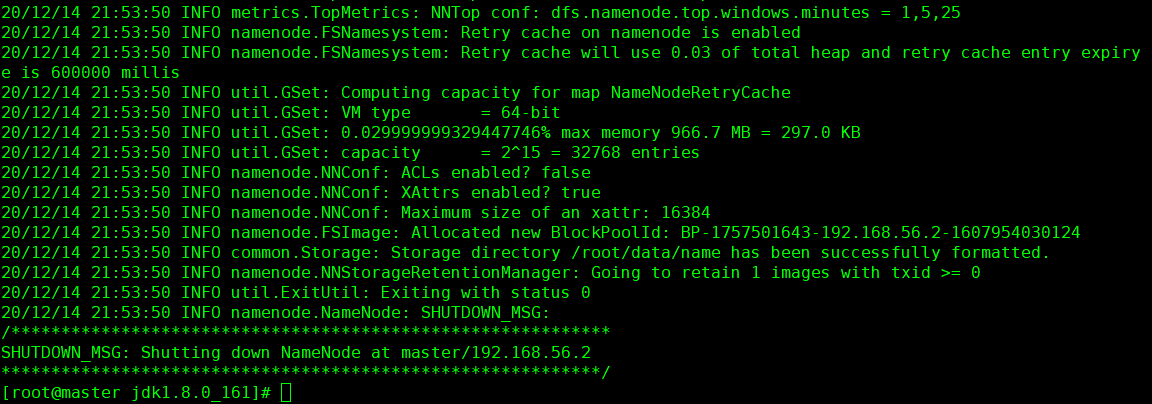
12 启动hdfs 进入到 cd /root/hadoop-2.6.0-cdh5.7.0/sbin/ 执行启动命令 ./start-all.sh 关闭命令 ./stop-all.sh
输入jps
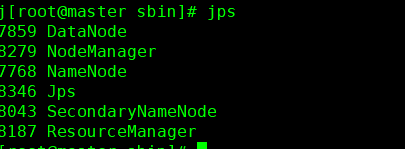
如果不足六个
关闭 hadoop 命令 ./stop-all.sh
需要在 vi /etc/hosts 文件添加 主机名

需要在 vi /etc/sysconfig/network 添加 HOSTNAME=master

删除 rm -rf /root/data /opt/hdfs (/root/data是你在修改hdfs-site.xml文件 的地址 /opt/hdfs是你在修改core-site.xml 文件 的地址)
执行 hadoop namenode -format 格式化 之后再次启动 hadoop就可以了 (启动命令./start-all.sh)