不论是一般的筛法求素数还是改进的欧拉筛法,每次要用的时候就忘了具体怎么实现的。欲成一劳永逸之功,写了这篇博客。勉之勉之
筛法求素数的原理:
通俗的来说就是象一个筛芝麻的大筛子,筛掉其中不合格的部分,那么剩下的自然而然就是素数。
例如:我们求100内的所有素数
1不是素数 舍去
2是素数 依次去掉2的倍数
3是素数 依次去掉3的倍数
以此类推 直到筛子里只剩下素数为止。
原理很简单(ps:筛子的确定给我的感觉就是一种dp算法赶脚)
先试写一个一般的筛法求素数:
一般的筛法的筛子是如何取的呢,就是单纯的的除开1之外的所有的数从小到大依次当作质数。
简单在脑海算一下就发现精妙之处
2的倍数 4 6 8 10被筛去
接下来 3的倍数 6 9 12 被筛去
接下来就是4的倍数该被筛选啦 可是4在第一次的筛选中已经被定义为不是素数啦!!所以会直接跳过4 把5当作质数继续筛选
好到这里就是筛法的关键之处.所有的合数只会被筛选一次,并且不会有遗漏之处(虽然一般筛法没有实现所有的合数只能筛选一次)
至于原理就是每个合数都可以表示成一串唯一的质数的乘积:n=p1*p2*p3…………
当我们从小到大把每个数都当作质数进行筛选时是不会漏掉任何一个合数的,因为筛子中包含啦合数和质数,但是必定包含了所有的素数
而每个合数都是素数的乘积,所以不会漏掉任何一个合数的。原理过程都清楚啦!
下面贴出代码:
1 import java.util.*; 2 class Su 3 { 4 public static void main(String[] args) 5 { 6 boolean[] Is_prime=new boolean[10001];//默认所有的数都是质数,false代表质数 7 //int[] dp=new int[];//还没有筛的所有的芝麻 8 for(int i=2;i<Math.sqrt(10000);i++)//98=2*49 把2当作筛子和把49当作筛子的含义是一样的 9 { 10 if(!Is_prime[i]){//判断这个合数是不是已经被筛选为合数 11 for(int j=2;j*i<=10000;j++) 12 { 13 Is_prime[i*j]=true; 14 } 15 } 16 } 17 for(int i=1;i<10000;i++){ 18 if(!Is_prime[i]) 19 System.out.print(i+"\t"); 20 } 21 } 22 }
值得注意的是第8行,我们一般习惯把循环上限设为sqrt(n)。“但是如果n很大的时候,上限是n平方根会让算法的效率在数量级上大于n的,还深信n每扩大一百倍,它所耗费的时间只会随之增加大概十倍。”--http://blog.csdn.net/rmartin/article/details/1132312
改进的筛法求素数即欧拉筛法(理解较为复杂,需要耐心细读):
素数筛法的一个关键是筛子,同时影响效率也在筛子上
一般筛法的筛子默认是所有的数,然后每次运算后改变boolea数组的值,筛子逐渐减小。
上文的红字已经提到,一般筛法并没实现所有合数只筛选一次。出现了什么问题呢?
例如:30这个合数
当2作为筛子的时候 2*15筛选了一次
3作为筛子的时候筛选了一次
5作为筛子的时候又再筛选了一次
这样看来30这个合数不停的被筛选,极大的影响啦效率
当我们换个思路,会发现豁然开朗
我们不再追求局部的全部筛除,而追求整体的不重复。如何实现呢?
欧拉线性筛法的原理:(简单的说就是只通过最小因子筛选合数)
1.如果i是质数,那么就将它与之前的质数的乘积筛掉
2.如果i是合数,那么就将它与从2到它最小的质因子之间的质数的乘积分别筛掉
我们先在下面算法的15行中加入System.out.println(i*P[j]+" "+P[j]);可以看到这些合数到底是如何被筛掉的。
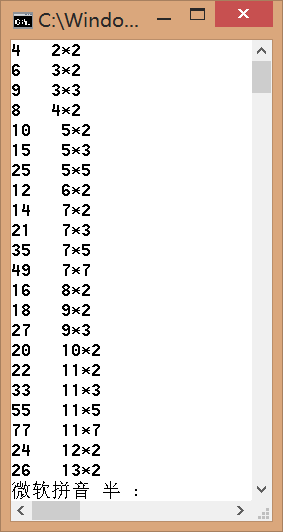
重点1.为什么下面的算法不会遗漏所有的合数(保证算法的正确性):(注意是讨论而不是严格的证明,严格的证明请参考相关数论的书籍)
重点2.每个合数只会被筛选一次(保证算法的线性或者说时间复杂度):
复杂度:最主要是break那里,上文原理也说到欧拉线性筛中一个数字只被它最小的素因子筛掉:取个例子12
12被2筛掉,当i等于6的时候2*6==12筛掉12,这时候6%2==0可以break了,如果不break,那么6还会把18筛掉,可是显然18最小的素因子是2,所以当i枚举到9的时候有9*2==18,这样18就又被筛了一次,因此在i等于6的时候不能拿6去筛18.
用代数式子来解释:
当p[j]是i的因子时,设i=p[j]* k,因为素因子从小到大存入到p数组里的,所以p[j]是i的最小素因子,此时i已经无需再去剔除p[j++] * i
(j’>j) 形式的合数了,因为p[j++]* i可以写成p[j’]* (p[j]*
k)=p[j](p[j’] k),也就是说所有的p[j’]* i将会被将来的某个i’=p[j’]*k剔除掉。
我用反证法不那么严谨的证明一下:已知条件n=p1*p2*p3*p4……,p1 p2 p3是质数并且p1<p2<p3<……。假如n能被非最小素因子乘积p1*n1之外组合p2*n2筛除。n=p1*p2*p3*p4=p1*n1=p2*n2(p1<p2),所以n1>n2
按照for循环i 先等于n2。n2包含素因子p1,所以n2只能筛除n2*p1这个合数,筛除这个数,进行i%p1的判断时break,n2是绝对不能筛除n2*p2这个合数的。所以假设不成立,即每个合数只能被最小素因数筛除,这也就保证了线性。
所以对比一般的筛法就能得出算法的正确性:一般算法中的所有i*j的组合都能在欧拉筛法中找到对应的最小因子乘以i。所以这个算法首先是正确的
需要注意的是我们把if(!Is_prime[i] ) P[ x++ ]=i; 放在了循环的前面
1 import java.util.*; 2 class Su2 3 { 4 public static void main(String[] args) 5 { 6 boolean[] Is_prime=new boolean[101];//默认所有的数都是质数,false代表质数 7 int[] P=new int[101]; 8 int x=0; 9 for( int i = 2 ; i <= 100 ; ++i ){ 10 if(!Is_prime[i] )// 11 P[ x++ ]=i; 12 for(int j=0;j<x;++j){//j<x是每次筛除的都是i去*那些质数 13 if( i*P[ j ] > 100 ) 14 break; //当过大了就跳出,当然也可以写在for的判定条件中 15 Is_prime[ i * P[ j ] ] = true; 16 //筛去素数 17 if( i % P[ j ] == 0 ) break; 18 } 19 } 20 //这里是关键,如果i是一个合数(这当然是存在的)我们仅仅筛除i*2后 21 for(int i=0;i<100;i++){ 22 if(!Is_prime[i]) 23 System.out.print(i+"\t"); 24 } 25 } 26 } 27
欧拉筛法在积性函数也有运用,且待有空再研究吧!!!