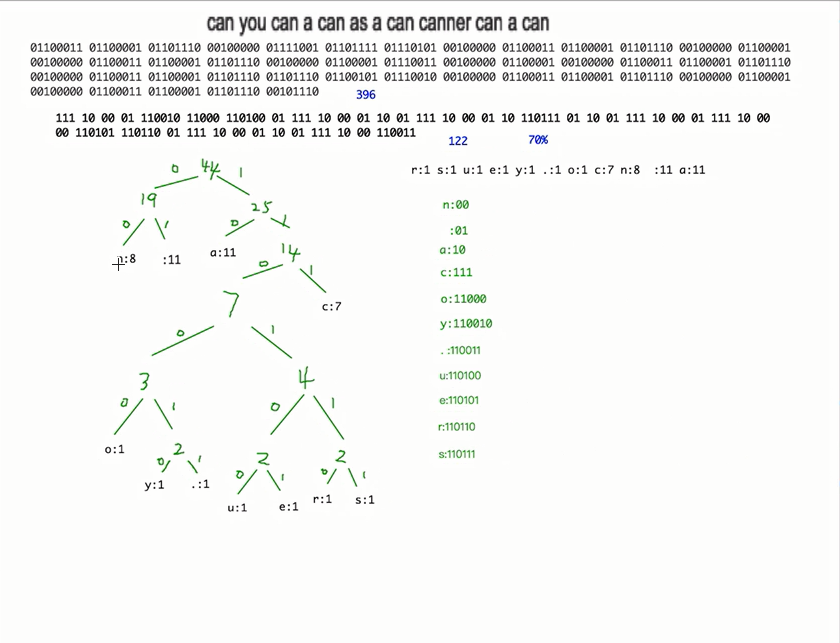
编码压缩思路:给定一个字符串,先统计字符串中每个字节出现的次数,并放入集合(键为字节元素,也为树节点的data;值为出现的次数,也为树节点的权重)中。将每一个键值对转换为节点对象。利用得到的节点对象生成一个赫夫曼树,根据赫夫曼树进行赫夫曼编码,返回一个赫夫曼编码表的集合(键为节点的data,值为节点的路径,也为赫夫曼编码),由此得到了每一个字节对应的赫夫曼编码。依次对给定字符串进行赫夫曼编码,得到一个赫夫曼编码的字节数组,最后将字节数组每八位进行压缩,得到最终编码后的压缩字节数组。
package demo10;
public class Node implements Comparable<Node> {
Byte data;
int weight;
Node left;
Node right;
public Node(Byte data,int weight) {
this.data=data;
this.weight=weight;
}
@Override
public String toString() {
return "Node [data=" + data + ", weight=" + weight + "]";
}
@Override
public int compareTo(Node o) {
return o.weight-this.weight;
}
}
package demo10;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
public class TestHuffmanCode {
public static void main(String[] args) {
// String msg="can you can a can as a can canner can a can.";
// byte[] bytes = msg.getBytes();
// //进行赫夫曼编码压缩
// byte[] b = huffmanZip(bytes);
// //使用赫夫曼编码进行解码
// byte[] newBytes = decode(huffCodes,b);
// System.out.println(new String(newBytes));
String src="1.bmp";
String dst="2.zip";
// try {
// zipFile(src, dst);
// } catch (IOException e) {
// e.printStackTrace();
// }
try {
unZip("2.zip", "3.bmp");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件的解压
* @param src
* @param dst
* @throws Exception
*/
public static void unZip(String src,String dst) throws Exception {
//创建一个输入流
InputStream is = new FileInputStream("2.zip");
ObjectInputStream ois = new ObjectInputStream(is);
//读取byte数组
byte[] b = (byte[]) ois.readObject();
//读取赫夫曼编码表
Map<Byte, String> codes = (Map<Byte, String>) ois.readObject();
ois.close();
is.close();
//解码
byte[] bytes = decode(codes, b);
//创建一个输出流
OutputStream os = new FileOutputStream(dst);
//写出数据
os.write(bytes);
os.close();
}
/**
* 压缩文件
* @param src
* @param dst
* @throws IOException
*/
public static void zipFile(String src,String dst) throws IOException {
//创建一个输入流
InputStream is = new FileInputStream(src);
//创建一个和输入流指向的文件大小一样的byte数组
byte[] b = new byte[is.available()];
//读取文件内容
is.read(b);
is.close();
//使用赫夫曼编码进行编码
byte[] byteZip = huffmanZip(b);
//输出流
OutputStream os = new FileOutputStream(dst);
ObjectOutputStream oos = new ObjectOutputStream(os);
//把压缩后的byte数组写入文件
oos.writeObject(byteZip);
//把赫夫曼编码表写入文件
oos.writeObject(huffCodes);
oos.close();
os.close();
}
/**
* 使用指定的赫夫曼编码表进行解码
* @param huffCodes2
* @param b
* @return
*/
private static byte[] decode(Map<Byte, String> huffCodes, byte[] bytes) {
StringBuilder sb = new StringBuilder();
//把byte数组转为一个二进制的字符串
for(int i=0;i<bytes.length;i++) {
byte b = bytes[i];
//是否是最后一个。
boolean flag = (i==bytes.length-1);
sb.append(byteToBitStr(!flag,b));
}
//把字符串按照指定的赫夫曼编码进行解码
//把赫夫曼编码的键值对进行调换
Map<String, Byte> map = new HashMap<>();
for(Map.Entry<Byte, String> entry:huffCodes.entrySet()) {
map.put(entry.getValue(), entry.getKey());
}
//创建一个集合,用于存byte
List<Byte> list = new ArrayList<>();
//处理字符串
for(int i=0;i<sb.length();) {
int count=1;
boolean flag = true;
Byte b=null;
//截取出一个byte
while(flag) {
String key = sb.substring(i, i+count);
b = map.get(key);
if(b==null) {
count++;
}else {
flag=false;
}
}
list.add(b);
i+=count;
}
//把集合转为数组
byte[] b = new byte[list.size()];
for(int i=0;i<b.length;i++) {
b[i]=list.get(i);
}
return b;
}
private static String byteToBitStr(boolean flag,byte b) {
int temp=b;
if(flag) {
temp|=256;
}
String str = Integer.toBinaryString(temp);
if(flag) {
return str.substring(str.length()-8);
}else {
return str;
}
}
/**
* 进行赫夫曼编码压缩的方法
* @param bytes
* @return
*/
private static byte[] huffmanZip(byte[] bytes) {
//先统计每一个byte出现的次数,并放入一个集合中
List<Node> nodes = getNodes(bytes);
//创建一颗赫夫曼树
Node tree = createHuffmanTree(nodes);
//创建一个赫夫曼编码表
Map<Byte, String> huffCodes = getCodes(tree);
//编码
byte[] b = zip(bytes,huffCodes);
return b;
}
/**
* 进行赫夫曼编码
* @param bytes
* @param huffCodes2
* @return
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffCodes) {
StringBuilder sb = new StringBuilder();
//把需要压缩的byte数组处理成一个二进制的字符串
for(byte b:bytes) {
sb.append(huffCodes.get(b));
}
//定义长度
int len;
if(sb.length()%8==0) {
len=sb.length()/8;
}else {
len=sb.length()/8+1;
}
//用于存储压缩后的byte
byte[] by = new byte[len];
//记录新byte的位置
int index = 0;
for(int i=0;i<sb.length();i+=8) {
String strByte;
if(i+8>sb.length()) {
strByte = sb.substring(i);
}else {
strByte = sb.substring(i, i+8);
}
byte byt = (byte)Integer.parseInt(strByte, 2);
by[index]=byt;
index++;
}
return by;
}
//用于临时存储路径
static StringBuilder sb = new StringBuilder();
//用于存储赫夫曼编码
static Map<Byte, String> huffCodes = new HashMap<>();
/**
* 根据赫夫曼树获取赫夫曼编码
* @param tree
* @return
*/
private static Map<Byte, String> getCodes(Node tree) {
if(tree==null) {
return null;
}
getCodes(tree.left,"0",sb);
getCodes(tree.right,"1",sb);
return huffCodes;
}
private static void getCodes(Node node, String code, StringBuilder sb) {
StringBuilder sb2 = new StringBuilder(sb);
sb2.append(code);
if(node.data==null) {
getCodes(node.left, "0", sb2);
getCodes(node.right, "1", sb2);
}else {
huffCodes.put(node.data, sb2.toString());
}
}
/**
* 创建赫夫曼树
* @param nodes
* @return
*/
private static Node createHuffmanTree(List<Node> nodes) {
while(nodes.size()>1) {
//排序
Collections.sort(nodes);
//取出两个权值最低的二叉树
Node left = nodes.get(nodes.size()-1);
Node right = nodes.get(nodes.size()-2);
//创建一颗新的二叉树
Node parent = new Node(null, left.weight+right.weight);
//把之前取出来的两颗二叉树设置为新创建的二叉树的子树
parent.left=left;
parent.right=right;
//把前面取出来的两颗二叉树删除
nodes.remove(left);
nodes.remove(right);
//把新创建的二叉树放入集合中
nodes.add(parent);
}
return nodes.get(0);
}
/**
* 把byte数组转为node集合
* @param bytes
* @return
*/
private static List<Node> getNodes(byte[] bytes) {
List<Node> nodes = new ArrayList<>();
//存储每一个byte出现了多少次。
Map<Byte, Integer> counts = new HashMap<>();
//统计每一个byte出现的次数
for(byte b:bytes) {
Integer count = counts.get(b);
if(count==null) {
counts.put(b, 1);
}else {
counts.put(b, count+1);
}
}
//把每一个键值对转为一个node对象
for(Map.Entry<Byte, Integer> entry:counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
}