从“用户登录”测试谈起
是什么
- 输入已注册的用户名和正确的密码,验证是否登录成功;
- 输入已注册的用户名和不正确的密码,验证是否登录失败,并且提示信息正确;
- 输入未注册的用户名和任意密码,验证是否登录失败,并且提示信息正确;
- 用户名和密码两者都为空,验证是否登录失败,并且提示信息正确;
- 用户名和密码两者之一为空,验证是否登录失败,并且提示信息正确;
- 如果登录功能启用了验证码功能,在用户名和密码正确的前提下,输入正确的验证码,验证是否登录成功;
- 如果登录功能启用了验证码功能,在用户名和密码正确的前提下,输入错误的验证码,验证是否登录失败,并且提示信息正确。
还需要增加:
- 用户名和密码是否大小写敏感;
- 页面上的密码框是否加密显示;
- 后台系统创建的用户第一次登录成功时,是否提示修改密码;
- 忘记用户名和忘记密码的功能是否可用;
- 前端页面是否根据设计要求限制用户名和密码长度;
- 如果登录功能需要验证码,点击验证码图片是否可以更换验证码,更换后的验证码是否可用;
- 刷新页面是否会刷新验证码;
- 如果验证码具有时效性,需要分别验证时效内和时效外验证码的有效性;
- 用户登录成功但是会话超时后,继续操作是否会重定向到用户登录界面;
- 不同级别的用户,比如管理员用户和普通用户,登录系统后的权限是否正确;
- 页面默认焦点是否定位在用户名的输入框中;
- 快捷键 Tab 和 Enter 等,是否可以正常使用。
安全还需要包括:
- 用户密码后台存储是否加密;
- 用户密码在网络传输过程中是否加密;
- 密码是否具有有效期,密码有效期到期后,是否提示需要修改密码;
- 不登录的情况下,在浏览器中直接输入登录后的 URL 地址,验证是否会重新定向到用户登录界面;
- 密码输入框是否不支持复制和粘贴;
- 密码输入框内输入的密码是否都可以在页面源码模式下被查看;
- 用户名和密码的输入框中分别输入典型的“SQL 注入攻击”字符串,验证系统的返回页面;
- 用户名和密码的输入框中分别输入典型的“XSS 跨站脚本攻击”字符串,验证系统行为是否被篡改;
- 连续多次登录失败情况下,系统是否会阻止后续的尝试以应对暴力破解;
- 同一用户在同一终端的多种浏览器上登录,验证登录功能的互斥性是否符合设计预期;
- 同一用户先后在多台终端的浏览器上登录,验证登录是否具有互斥性。
性能压力测试用例包括:
- 单用户登录的响应时间是否小于 3 秒;
- 单用户登录时,后台请求数量是否过多;
- 高并发场景下用户登录的响应时间是否小于 5 秒;
- 高并发场景下服务端的监控指标是否符合预期;
- 高集合点并发场景下,是否存在资源死锁和不合理的资源等待;
- 长时间大量用户连续登录和登出,服务器端是否存在内存泄漏。
兼容性测试用例还需要包括:
-
不同浏览器下,验证登录页面的显示以及功能正确性;
-
相同浏览器的不同版本下,验证登录页面的显示以及功能正确性;
-
不同移动设备终端的不同浏览器下,验证登录页面的显示以及功能正确性;
-
不同分辨率的界面下,验证登录页面的显示以及功能正确性。
总之:测试是测试不完的:要兼顾缺陷风险和研发成本之间的平衡
单元测试
是什么
单元测试是指,对软件中的最小可测试单元在与程序其他部分相隔离的情况下进行检查和验证的工作,这里的最小可测试单元通常是指函数或者类。
为什么
- 单元测试属于最严格的软件测试手段,是最接近代码底层实现的验证手段,可以在软件开发的早期以最小的成本保证局部代码的质量。
- 单元测试都是以自动化的方式执行,所以在大量回归测试的场景下更能带来高收益
- 单元测试的实施过程还可以帮助开发工程师改善代码的设计与实现,并能在单元测试代码里提供函数的使用示例,因为单元测试的具体表现形式就是对函数以各种不同输入参数组合进行调用,这些调用方法构成了函数的使用说明。
怎么做
- 并不是所有的代码都要进行单元测试,通常只有底层模块或者核心模块的测试中才会采用单元测试。
- 你需要确定单元测试框架的选型,这和开发语言直接相关。比如,Java 最常用的单元测试框架是 Junit 和 TestNG;C/C++ 最常用的单元测试框架是 CppTest 和 Parasoft C/C++test;框架选型完成后,你还需要对桩代码框架和 Mock 代码框架选型,选型的主要依据是开发所采用的具体技术栈。
通常,单元测试框架、桩代码 /Mock 代码的选型工作由开发架构师和测试架构师共同决定。 - 为了能够衡量单元测试的代码覆盖率,通常你还需要引入计算代码覆盖率的工具。不同的语言会有不同的代码覆盖率统计工具,比如 Java 的 JaCoCo,JavaScript 的 Istanbul。在后续的文章中,我还会详细为你介绍代码覆盖率的内容。
- 最后你需要把单元测试执行、代码覆盖率统计和持续集成流水线做集成,以确保每次代码递交,都会自动触发单元测试,并在单元测试执行过程中自动统计代码覆盖率,最后以“单元测试通过率”和“代码覆盖率”为标准来决定本次代码递交是否能够被接受。
相关概念
驱动代码,桩代码和 Mock 代码
是单元测试中最常出现的三个名词。
驱动代码是用来调用被测函数的,
桩代码和 Mock 代码是用来代替被测函数调用的真实代码的。
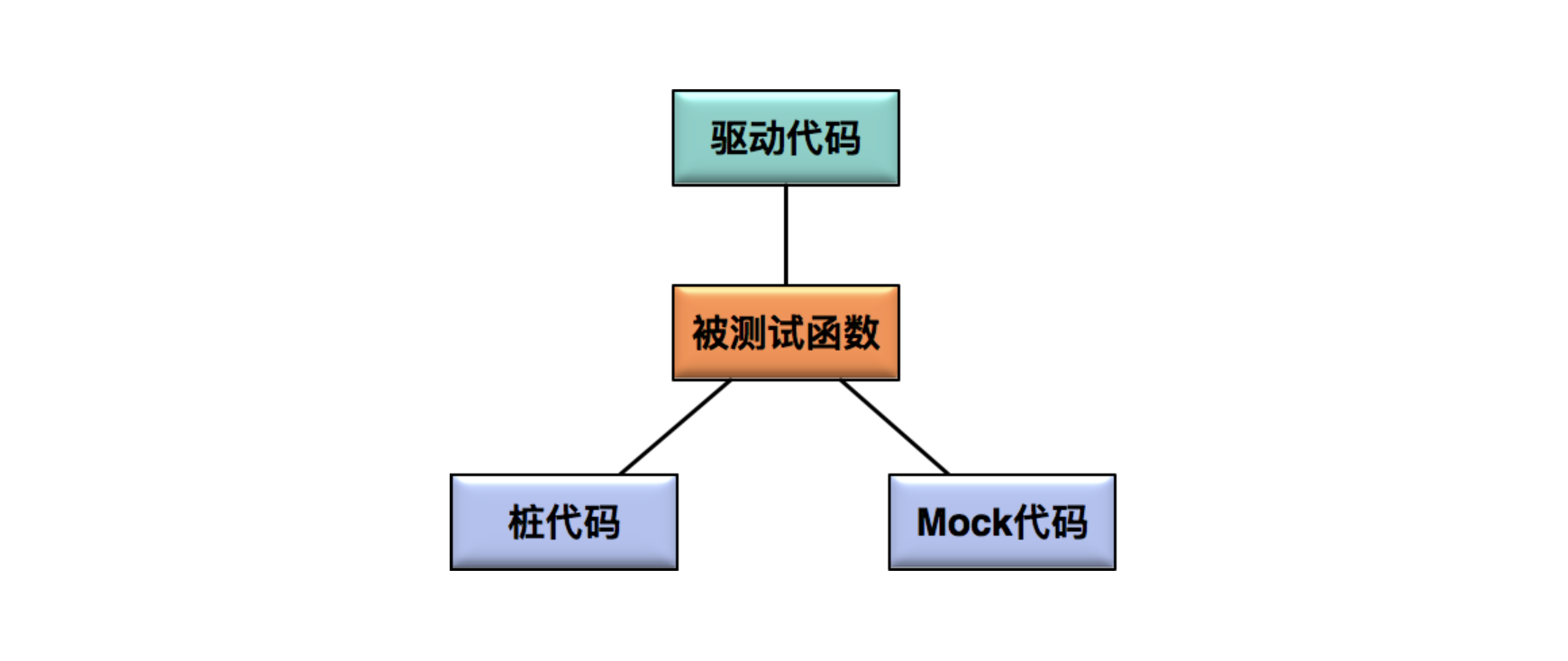
驱动代码,桩代码和 Mock 代码三者的逻辑关系
驱动代码(Driver)指调用被测函数的代码,在单元测试过程中,驱动模块通常包括调用被测函数前的数据准备、调用被测函数以及验证相关结果三个步骤。驱动代码的结构,通常由单元测试的框架决定。
桩代码(Stub)是用来代替真实代码的临时代码。 比如,某个函数 A 的内部实现中调用了一个尚未实现的函数 B,为了对函数 A 的逻辑进行测试,那么就需要模拟一个函数 B,这个模拟的函数 B 的实现就是所谓的桩代码。
总结
- 代码要做到功能逻辑正确,必须做到分类正确并且完备无遗漏,同时每个分类的处理逻辑必须正确;
- 单元测试是对软件中的最小可测试单元在与软件其他部分相隔离的情况下进行的代码级测试;
- 桩代码起到了隔离和补齐的作用,使被测代码能够独立编译、链接,并运行。
自动化测试
是什么
自动化测试是,把人对软件的测试行为转化为由机器执行测试行为的一种实践,对于最常见的 GUI 自动化测试来讲,就是由自动化测试工具模拟之前需要人工在软件界面上的各种操作,并且自动验证其结果是否符合预期
为什么要用自动化测试
- 自动化测试可以替代大量的手工机械重复性操作,测试工程师可以把更多的时间花在更全面的用例设计和新功能的测试上;
- 自动化测试可以大幅提升回归测试的效率,非常适合敏捷开发过程;
- 自动化测试可以更好地利用无人值守时间,去更频繁地执行测试,特别适合现在非工作时间执行测试,工作时间分析失败用例的工作模式;
- 自动化测试可以高效实现某些手工测试无法完成或者代价巨大的测试类型,比如关键业务 7×24 小时持续运行的系统稳定性测试和高并发场景的压力测试等;
- 自动化测试还可以保证每次测试执行的操作以及验证的一致性和可重复性,避免人为的遗漏或疏忽。
为什么取代不了手动测试
- 自动化测试并不能取代手工测试,它只能替代手工测试中执行频率高、机械化的重复步骤。你千万不要奢望所有的测试都自动化,否则一定会得不偿失。
- 自动测试远比手动测试脆弱,无法应对被测系统的变化,业界一直有句玩笑话“开发手一抖,自动化测试忙一宿”,这也从侧面反映了自动化测试用例的维护成本一直居高不下的事实。
其根本原因在于自动化测试本身不具有任何“智能”,只是按部就班地执行事先定义好的测试步骤并验证测试结果。对于执行过程中出现的明显错误和意外事件,自动化测试没有任何处理能力。 - 自动化测试用例的开发工作量远大于单次的手工测试,所以只有当开发完成的测试用例的有效执行次数大于等于 5 次时,才能收回自动化测试的成本。
- 手工测试发现的缺陷数量通常比自动化测试要更多,并且自动化测试仅仅能发现回归测试范围的缺陷。
- 测试的效率很大程度上依赖自动化测试用例的设计以及实现质量,不稳定的自动化测试用例实现比没有自动化更糟糕。
- 实行自动化测试的初期,用例开发效率通常都很低,大量初期开发的用例通常会在整个自动化测试体系成熟,和测试工程师全面掌握测试工具后,需要重构。
- 业务测试专家和自动化测试专家通常是两批人,前者懂业务不懂自动化技术,后者懂自动化技术但不懂业务,只有二者紧密合作,才能高效开展自动化测试。
- 自动化测试开发人员必须具备一定的编程能力,这对传统的手工测试工程师会是一个挑战。
适用的具体项目场景
第一,需求稳定,不会频繁变更。
第二,研发和维护周期长,需要频繁执行回归测试。
第三,需要在多种平台上重复运行相同测试的场景。
这样的场景其实有很多,比如:
- 对于 GUI 测试,同样的测试用例需要在多种不同的浏览器上执行;
- 对于移动端应用测试,同样的测试用例需要在多个不同的 Android 或者 iOS 版本上执行,或者是同样的测试需要在大量不同的移动终端上执行;
- 对于一些企业级软件,如果对于不同的客户有不同的定制版本,各个定制版本的主体功能绝大多数是一致的,可能只有个别功能有轻微差别,测试也是需要覆盖每个定制版本的所有测试;
第四,某些测试项目通过手工测试无法实现,或者手工成本太高。
第五,被测软件的开发较为规范,能够保证系统的可测试性。
第六,测试人员已经具备一定的编程能力。
如果测试团队的成员没有任何开发编程的基础,那你想要推行自动化测试就会有比较大的阻力。这个阻力会来自于两个方面:
- 前期的学习成本通常会比较大,很难在短期内对实际项目产生实质性的帮助,此时如果管理层对自动化测试没有正确的预期,很可能会叫停自动化测试;
- 测试工程师通常会非常热衷于学习使用自动化测试技术,以至于他们的工作重点会发生错误的偏移,把大量的精力放在自动化测试技术的学习与实践上,而忽略了测试用例的设计,这将直接降低软件整体的质量。
各阶段都有哪些自动化测试技术
单元测试的自动化技术
用例框架代码生成的自动化;
- 框架代码应该由自动化工具生成
部分测试输入数据的自动化生成;
- 据不同变量类型自动生成测试输入数据
- 自动化工具还需要实现 “抽桩”
自动桩代码的生成;
- 自动化工具可以对被测试代码进行扫描分析,自动为被测函数内部调用的其他函数生成可编程的桩代码,并提供基于测试用例的桩代码管理机制。此时,单元测试开发者只需重点关注桩代码内的具体逻辑实现,以及桩代码的返回值。
被测代码的自动化静态分析;
测试覆盖率的自动统计与分析。
- 自动化工具可以自动统计各种测试覆盖率,包括代码行覆盖率、分支覆盖率、MC/DC 覆盖率等
代码级集成测试的自动化技术
代码级别与单元测试的区别
代码级集成测试与单元测试最大的区别只是,代码级集成测试中被测函数内部调用的其他函数必须是真实的,不允许使用桩代码代替,而单元测试中允许使用桩代码来模拟内部调用的其他函数。
为了解耦,用 Web Service 或者 RPC 调用的方式来协作完成各个软件功能,代码级别很少用。
Web Service 测试的自动化技术
是什么
Web Service 测试,主要是指 SOAP API 和 REST API 这两类 API 测试,最典型的是采用 SoapUI 或 Postman 等类似的工具。但这类测试工具基本都是界面操作手动发起 Request 并验证 Response,所以难以和 CI/CD 集成,于是就出现了 API 自动化测试框架。
怎么做
基于 API 自动化测试框架的测试用例示例,目前最流行的 API 自动测试框架是 REST Assured,它可以方便地发起 Restful API 调用并验证返回结果。
对于基于代码的 API 测试用例,通常包含三大步骤:
- 准备 API 调用时需要的测试数据;
- 准备 API 的调用参数并发起 API 的调用;
- 验证 API 调用的返回结果。
还包括:还包括以下四个方面:
- 测试脚手架代码的自动化生成;类比:单元测试阶段的用例框架代码自动生成
- 部分测试输入数据的自动生成;
- Response 验证的自动化;对于 API 调用返回结果的验证,通常关注的点是返回状态码(status code)、Scheme 结构以及具体的字段值,Response 验证自动化的核心思想是自动比较两次相同 API 调用的返回结果,并自动识别出有差异的字段值,比较过程可以通过规则配置去掉诸如时间戳、会话 ID(Session ID)等动态值。
- 基于 SoapUI 或者 Postman 的自动化脚本生成。
GUI 测试的自动化技术
两大方向,传统 Web 浏览器和移动端原生应用(Native App)的 GUI 自动化
对于传统 Web ,Selenium
商业方案采用 Micro Focus 的 UFT(前身是 HP 的 QTP);
对于移动端原生,采用主流的 Appium
它对 iOS 环境集成了 XCUITest,对 Android 环境集成了 UIAutomator 和 Espresso。
测试覆盖率
是什么
测试覆盖率通常被用来衡量测试的充分性和完整性,从广义的角度来讲,测试覆盖率主要分为两大类,一类是面向项目的需求覆盖率,另一类是更偏向技术的代码覆盖率。
需求覆盖率
通常采用 ALM,Doors 和 TestLink 等需求管理工具来建立需求和测试的对应关系,并以此计算测试覆盖率
通常的做法是将每一条分解后的软件需求和对应的测试建立一对多的映射关系,最终目标是保证测试可以覆盖每个需求,以保证软件产品的质量
代码覆盖率
代码覆盖率是指,至少被执行了一次的条目数占整个条目数的百分比。
三种代码覆盖
- 行覆盖率又称为语句覆盖率,指已经被执行到的语句占总可执行语句(不包含类似 C++ 的头文件声明、代码注释、空行等等)的百分比。这是最常用也是要求最低的覆盖率指标。实际项目中通常会结合判定覆盖率或者条件覆盖率一起使用。
- 判定覆盖又称分支覆盖,用以度量程序中每一个判定的分支是否都被测试到了,即代码中每个判断的取真分支和取假分支是否各被覆盖至少各一次。比如,对于 if(a>0 && b>0),就要求覆盖“a>0 && b>0”为 TURE 和 FALSE 各一次。
- 条件覆盖是指,判定中的每个条件的可能取值至少满足一次,度量判定中的每个条件的结果 TRUE 和 FALSE 是否都被测试到了。比如,对于 if(a>0 && b>0),就要求“a>0”取 TRUE 和 FALSE 各一次,同时要求“b>0”取 TRUE 和 FALSE 各一次。
怎么做
代码覆盖率工具 JaCoCo
原理:注入
源代码(Source Code)注入和字节码(Byte Code)注入两大类
字节码注入又可以分为两大模式:On-The-Fly 注入模式和 Offline 注入模式。
实现:ASM 是一个 Java 字节码操纵框架,能被用来动态生成类或者增强既有类的功能,可以直接产生 class 文件,也可以在类被加载入 JVM 之前动态改变类行为。
On-The-Fly 注入模式
- 开发自定义的类装载器(Class Loader)实现类装载策略,每次类加载前,需要在 class 文件中插入探针,早期的 Emma 就是使用这种方案实现的探针插入;
- 借助 Java Agent,利用执行在 main() 方法之前的拦截器方法 premain() 来插入探针,实际使用过程中需要在 JVM 的启动参数中添加“-javaagent”并指定用于实时字节码注入的代理程序,这样代理程序在装载每个 class 文件前,先判断是否已经插入了探针,如果没有则需要将探针插入 class 文件中,目前主流的 JaCoCo 就是使用了这个方式。
Offline 注入模式。
Offline 模式也无需修改源代码,但是需要在测试开始之前先对文件进行插桩,并事先生成插过桩的 class 文件。它适用于不支持 Java Agent 的运行环境,以及无法使用自定义类装载器的场景。
这样做的优点是,JVM 启动时不再需要使用 Java Agent 额外开启代理,缺点是无法实时获取代码覆盖率信息,只能在系统停机时下获取。
Offline 模式根据是生成新的 class 文件还是直接修改原 class 文件,又可以分为 Replace 和 Inject 两种不同模式。
和 On-The-Fly 注入模式不同,Replace 和 Inject 的实现是,在测试运行前就已经通过 ASM 将探针插入了 class 文件,而在测试的运行过程中不需要任何额外的处理。Cobertura 就是使用 Offline 模式的典型代表。
缺陷报告的书写:
-
一份高效的软件缺陷报告,应该包括缺陷标题、缺陷概述、缺陷影响、环境配置、前置条件、缺陷重现步骤、期望结果和实际结果、优先级和严重程度、变通方案、根原因分析,以及附件这几大部分
-
或者:,标题,版本信息,环境描述,复现步骤,期望结果,出现问题的结果。严重程度,是否容易复现。还有系统的一些必填信息
-
1,环境配置填好
2,标题:版本-路径-缺员描述
3,重现步骤:前置条件,操作步骤(重现步骤最好简短,明确,步骤有效)
4,结果:如提交失败,原因是什么
5,期望:提交成功
6,截图:标记出错的位置和在截图上简洁描述原因
测试计划
是什么
软件项目,通常都会有详细的项目计划。软件测试作为整个项目中的重要一环,也要执行详细的测试计划。正所谓运筹帷幄之中,决胜千里之外,强调的就是预先计划的重要性和必要性。
在早期的软件工程实践中,软件测试计划的制定通常是在需求分析以及测试需求分析完成后开始,并且是整个软件研发生命周期中的重要环节。
但是,在敏捷开发模式下很少制定详细的测试计划
为什么要做
如果没有测试计划,会带来哪些问题呢?
- 很难确切地知道具体的测试范围,以及应该采取的具体测试策略;
- 很难预估具体的工作量和所需要的测试工程师数量,同时还会造成各个测试工程师的分工不明确,引发某些测试工作被重复执行而有些测试则被遗漏的问题;
- 测试的整体进度完全不可控,甚至很难确切知道目前测试的完成情况,对于测试完成时间就更难预估准确的时间节点了;
- 整个项目对潜在风险的抵抗能力很弱,很难应对需求的变更以及其他突发事件。
怎么做
- 测试范围:测试范围中需要明确“测什么”和“不测什么”。
- 测试策略:先测什么后测什么”和“如何来测”****功能,兼容性,性能
- 测试资源:人员,测试环境
- 测试进度:描述各类测试的开始时间,所需工作量,预计完成时间,并以此为依据来建议最终产品的上线发布时间。
- 测试风险预估
测试工程师的核心竞争力
七项核心竞争力,包括:测试策略设计能力、测试用例设计能力、快速学习能力、探索性测试思维、缺陷分析能力、自动化测试技术和良好的沟通能力。
测试策略设计能力
- 测试要具体执行到什么程度;
- 测试需要借助于什么工具;
- 如何运用自动化测试以及自动化测试框架,以及如何选型;
- 测试人员资源如何合理分配;
- 测试进度如何安排;
- 测试风险如何应对。
测试用例设计能力
对常见的缺陷模式、典型的错误类型以及遇到过的缺陷,要不断地总结、归纳,才能逐渐形成体系化的用例设计思维。
同时,你还可以阅读一些好的测试用例设计实例开阔思路,日后遇到类似的被测系统时,可以做到融会贯通和举一反三。
快速学习能力
快速学习能力,包含两个层面的含义:
- 对不同业务需求和功能的快速学习与理解能力;
- 对于测试新技术和新方法的学习与应用能力。
看官方文档
理解到事务的原理,而不是简单的停留在使用
探索性测试思维缺陷分析能力
探索性测试是指,测试工程师在执行测试的过程中不断学习被测系统,同时结合基于自己经验的错误猜测和逻辑推理,整理和分析出更多的有针对性的测试关注点。
本质上,探索性测试思维是“测试用例设计能力”和“快速学习能力”有机结合的必然结果。优秀的探索性测试思维可以帮助你实现低成本的“精准测试”,精准测试最通俗的理解可以概括为针对开发代码的变更,目标明确并且有针对性地对变更点以及变更关联点做测试,这也是目前敏捷测试主推的测试实践之一。
自动化测试技术
- 对于已经发现的缺陷,结合发生错误的上下文以及后台日志,可以预测或者定位缺陷的发生原因,甚至可以明确指出具体出错的代码行,由此可以大幅缩短缺陷的修复周期,并提高开发工程师对于测试工程师的认可以及信任度;
- 根据已经发现的缺陷,结合探索性测试思维,推断同类缺陷存在的可能性,并由此找出所有相关的潜在缺陷;
- 可以对一段时间内所发生的缺陷类型和趋势进行合理分析,由点到面预估整体质量的健康状态,并能够对高频缺陷类型提供系统性的发现和预防措施,并以此来调整后续的测试策略。
良好的沟通能力
需要对接产品经理和项目经理,以确保需求的正确实现和项目整体质量的达标;
还要和开发人员不断地沟通、协调,确保缺陷的及时修复与验证。
测试开发工程师的核心竞争力
第一项核心竞争力,测试系统需求分析能力
除了代码开发能力,测试开发工程师更要具备测试系统需求分析的能力。你要能够站在测试架构师的高度,识别出测试基础架构的需求和提高效率的应用场景。从这个角度说,你更像个产品经理,只不过你这个产品是为了软件测试服务的。
第二项核心竞争力,更宽广的知识体系
测试开发工程师需要具备非常宽广的知识体系,你不仅需要和传统的测试开发工程师打交道,因为他们是你构建的测试工具或者平台的用户;而且还要和 CI/CD、和运维工程师们有紧密的联系,因为你构建的测试工具或者平台,需要接入到 CI/CD 的流水线以及运维的监控系统中去。
除此之外,你还要了解更高级别的测试架构部署和生产架构部署、你还必须对开发采用的各种技术非常熟悉。
要掌握的非测试知识有哪些
- 小到 Linux/Unix/Windows 操作系统的基础知识,Oracle/MySQL 等传统关系型数据库技术,NoSQL 非关系型数据库技术,中间件技术,Shell/Python 脚本开发,版本管理工具与策略,CI/CD 流水线设计,F5 负载均衡技术,Fiddler/Wireshark/Tcpdump 等抓包工具,浏览器 Developer Tool 等;
- 大到网站架构设计,容器技术,微服务架构,服务网格(Service Mesh),DevOps,云计算,大数据,人工智能和区块链技术等。
关于前端技术的学习路径,通常你首先需要掌握最基本的 JavaScript、CSS、JQuery 和 HTML5 等知识,然后再去学习一些主流的前端开发框架,比如 Angular.js、Backbone.js 等。当然现在的 Node.js 的生态圈非常发达,你如果能够掌握 Node.js,那么很多东西实现起来都可以得心应手。
测试策略应该如何设计?
传统架构:
菱形架构:
- 以中间层的 API 测试为重点做全面的测试。
- 轻量级的 GUI 测试,只覆盖最核心直接影响主营业务流程的 E2E 场景。
- 最上层的 GUI 测试通常利用探索式测试思维,以人工测试的方式发现尽可能多的潜在问题。
- 单元测试采用“分而治之”的思想,只对那些相对稳定并且核心的服务和模块开展全面的单元测试,而应用层或者上层业务只会做少量的单元测试。
GUI测试
Selenium 结构:

Selenium RC Server,主要包括 Selenium Core,Http Proxy 和 Launcher 三部分:
- Selenium Core,是被注入到浏览器页面中的 JavaScript 函数集合,用来实现界面元素的识别和操作;
- Http Proxy,作为代理服务器修改 JavaScript 的源,以达到“欺骗”被测站点的目的;
- Launcher,用来在启动测试浏览器时完成 Selenium Core 的注入和浏览器代理的设置。

-
测试用例通过基于不同语言的 Client Libraries 向 Selenium RC Server 发送 Http 请求,要求与其建立连接。
-
连接建立后,Selenium RC Server 的 Launcher 就会启动浏览器或者重用之前已经打开的浏览器,把 Selenium Core(JavaScript 函数的集合)加载到浏览器页面当中,并同时把浏览器的代理设置为 Http Proxy。
-
测试用例通过 Client Libraries 向 Selenium RC Server 发送 Http 请求,Selenium RC Server 解析请求,然后通过 Http Proxy 发送 JavaScript 命令通知 Selenium Core 执行浏览器上控件的具体操作。
-
Selenium Core 接收到指令后,执行操作。
-
如果浏览器收到新的页面请求信息,则会发送 Http 请求来请求新的 Web 页面。由于 Launcher 在启动浏览器时把 Http Proxy 设置成为了浏览器的代理,所以 Selenium RC Server 会接收到所有由它启动的浏览器发送的请求。
-
Selenium RC Server 接收到浏览器发送的 Http 请求后,重组 Http 请求以规避“同源策略”,然后获取对应的 Web 页面。
-
Http Proxy 把接收的 Web 页面返回给浏览器,浏览器对接收的页面进行渲染。
Selenium2.0原理

-
当使用 Selenium2.0 启动浏览器 Web Browser 时,后台会同时启动基于 WebDriver Wire 协议的 Web Service 作为 Selenium 的 Remote Server,并将其与浏览器绑定。绑定完成后,Remote Server 就开始监听 Client 端的操作请求。
-
执行测试时,测试用例会作为 Client 端,将需要执行的页面操作请求以 Http Request 的方式发送给 Remote Server。该 HTTP Request 的 body,是以 WebDriver Wire 协议规定的 JSON 格式来描述需要浏览器执行的具体操作。
-
Remote Server 接收到请求后,会对请求进行解析,并将解析结果发给 WebDriver,由 WebDriver 实际执行浏览器的操作。
-
WebDriver 可以看做是直接操作浏览器的原生组件(Native Component),所以搭建测试环境时,通常都需要先下载浏览器对应的 WebDriver。
解耦
测试脚本和数据的解耦
数据驱动(Data-driven)测试
- 数据驱动很好地解决了大量重复脚本的问题,实现了“测试脚本和数据的解耦”。 目前几乎所有成熟的自动化测试工具和框架,都支持数据驱动的测试,而且除了支持 CSV 这种最常见的数据源外,还支持 xls 文件、JSON 文件,YAML 文件,甚至还有直接以数据库中的表作为数据源的,比如 QTP 就支持以数据库中的表作为数据驱动的数据源。
- 数据驱动测试的数据文件中不仅可以包含测试输入数据,还可以包含测试验证结果数据,甚至可以包含测试逻辑分支的控制变量。 图 1 中的“Result_LoginSuccess_Flag”变量其实就是用户分支控制变量。
- 数据驱动测试的思想不仅适用于 GUI 测试,还可以用于 API 测试、接口测试、单元测试等。所以,很多 API 测试工具(比如 SoapUI),以及单元测试框架都支持数据驱动测试,它们往往都是通过 Test Data Provider 模块将外部测试数据源逐条“喂”给测试脚本。
页面对象(Page Object)模型
为什么
- 解决了脚本可读性差的问题,脚本的逻辑层次也更清晰了;
- 解决了通用步骤会在大量测试脚本中重复出现的问题, 现在操作函数可以被多个测试用例共享,当某个步骤的操作或者界面控件发生变化时,只要一次性修改相关的操作函数就可以了,而不需要去每个测试用例中逐个修改。
是什么
页面对象模型的核心理念是,以页面(Web Page 或者 Native App Page)为单位来封装页面上的控件以及控件的部分操作。而测试用例,更确切地说是操作函数,基于页面封装对象来完成具体的界面操作,最典型的模式是“XXXPage.YYYComponent.ZZZOperation”。
怎么做
按照页面来进行封装
GUI测试中的测试数据
从创建的技术手段上来讲,创建测试数据的方法主要分为三种:
- API 调用;
- 数据库操作;
- 手工方式。查阅设计文档和产品代码,找到相关的 SQL 语句集合。或者,直接找开发人员索要相关的 SQL 语句集合。
- 自动方式。在测试环境中,先在只有一个活跃用户的情况下,通过 GUI 界面操作完成数据的创建、修改,然后利用数据库监控工具获取这段时间内所有的业务表修改记录,以此为依据开发 SQL 语句集。
- 综合运用 API 调用和数据库操作。
从创建的时机来讲,创建测试数据的方法主要分为两种:
- 测试用例执行过程中,实时创建测试数据,我们通常称这种方式为 On-the-fly。
- 在用例执行过程中实时创建数据,导致测试的执行时间比较长。 我曾经粗略统计过一个大型 Web GUI 自动化测试项目的执行时间,将近 30% 的时间都花在了测试数据的准备上。
- 业务数据的连带关系,导致测试数据的创建效率非常低。 比如,你需要创建一个订单数据,而这个订单必然会绑定买家和卖家,以及订单商品信息。
如果完全基于 On-the-fly 模式,你就需要先实时创建买家和卖家这两个用户,然后再创建订单中的商品,最后才是创建这个订单本身。
显然,这样的测试数据创建方式虽然是“自包含”的,但创建效率非常低,会使得测试用例执行时间变得更长,而这恰恰与互联网产品的测试策略产生冲突。 - 更糟糕的情况是,实时创建测试数据的方式对测试环境的依赖性很强。 比如,你要测试用户登录功能,基于 On-the-fly 方式,你就应该先调用测试数据工具实时创建一个用户,然后再用这个用户完成登录测试。
这时,创建用户的 API 由于各种原因处于不可用的状态(这种情况在采用微服务架构的系统中很常见),那么这时就会因为无法创建用户,而无法完成用户登录测试。
- 测试用例执行前,事先创建好“开箱即用”的测试数据,我们通常称这种方式为 Out-of-box。
- 对于相对稳定、很少有修改的数据,建议采用 Out-of-box 的方式,比如商品类目、厂商品牌、部分标准的卖家和买家账号等。
- 对于一次性使用、经常需要修改、状态经常变化的数据,建议使用 On-the-fly 的方式。
- 用 On-the-fly 方式创建测试数据时,上游数据的创建可以采用 Out-of-box 方式,以提高测试数据创建的效率。以订单数据为例,订单的创建可以采用 On-the-fly 方式,而与订单相关联的卖家、买家和商品信息可以使用 Out-of-box 方式创建。
自动化操作
页面对象自动生成技术
页面对象自动生成技术,它非常适用于需要维护大量页面对象的中大型 GUI 自动化测试项目。
页面对象自动生成技术,属于典型的“自动化你的自动化”的应用场景。它的基本思路是,你不用再手工维护 Page Class 了,只需要提供 Web 的 URL,它就会自动帮你生成这个页面上所有控件的定位信息,并自动生成 Page Class。
无头浏览器
是什么
无头浏览器,其实是一个特殊的浏览器,你可以把它简单地想象成是运行在内存中的浏览器。它拥有完整的浏览器内核,包括 JavaScript 解析引擎、渲染引擎等。
与普通浏览器最大的不同是,无头浏览器执行过程中看不到运行的界面,但是你依然可以用 GUI 测试框架的截图功能截取它执行中的页面。
为什么
- 测试执行速度更快。 相对于普通浏览器来说,无头浏览器无需加载 CSS 以及渲染页面,在测试用例的执行速度上有很大的优势。
- 减少对测试执行的干扰。 可以减少操作系统以及其他软件(比如杀毒软件等)不可预期的弹出框,对浏览器测试的干扰。
- 简化测试执行环境的搭建。 对于大量测试用例的执行而言,可以减少对大规模 Selenium Grid 集群的依赖,GUI 测试可以直接运行在无界面的服务器上。
- 在单机环境实现测试的并发执行。 可以在单机上很方便地运行多个无头浏览器,实现测试用例的并发执行。
怎么做
PhantomJS 的创建者 Ariya Hidayat 停止了它的后续维护,Headless Chrome 成了无头浏览器的首选方案。
那什么是 Puppeteer 呢?Puppeteer 是一个 Node 库,提供了高级别的 API 封装,这些 API 会通过 Chrome DevTools Protocol 与 Headless Chrome 的交互达到自动化操作的目的。
Puppeteer 也是由 Google 开发的,所以它可以很好地支持 Headless Chrome 以及后续 Chrome 的版本更新。
总结
- 对于页面对象自动生成,商用测试软件已经实现了这个功能。但是,如果你选择开源测试框架,就需要自己实现这个功能了。
- GUI 测试数据自动生成,主要是基于测试输入数据的类型以及对应的自定义规则库实现的,并且对于多个测试输入数据,可以基于笛卡尔积来自动组合出完整的测试用例集合。
- 对于无头浏览器,你可以把它简单地想象成运行在内存中的浏览器,它拥有完整的浏览器内核。与普通浏览器最大的不同是,它在执行过程中看不到运行的界面。目前,Headless Chrome 结合 Puppeteer 是最先进的无头浏览器方案,如果感兴趣,你可以下载试用。
GUI测试问题
GUI 测试不稳定的因素
- 非预计的弹出对话框;
- 页面控件属性的细微变化;
- 被测系统的 A/B 测试;
- 随机的页面延迟造成控件识别失败;
- 测试数据问题。
解决方案:
- 对于非预计的弹出对话框引起的不稳定,可以引入“异常场景恢复模式”来解决。
- 对于页面控件属性的细微变化造成的不稳定,可以使用“组合属性”定位控件,并且可以通过“模糊匹配技术”提高定位识别率。
- 对于 A/B 测试带来的不稳定,需要在测试用例脚本中做分支处理,并且需要脚本做到正确识别出不同的分支。
- 对于随机的页面延迟造成的不稳定,可以引入重试机制,重试可以是步骤级别的,也可以是页面级别的,甚至是业务流程级别的。
相关概念
- 非预期弹框:
对于非预期的弹框也可以通过检查置顶窗口是否是预期软件窗口,从而确定是否被第三方弹框影响。 - 页面控件变化:
如果是 selenium 的话,建议优先使用 xpath,这样就算 id、clases、name 等控件属性改变,只有不是页面改版,应该不会影响自动化稳定性。 - A/B 测试页面:
判断当前页面属于哪个分支,然后走兼任处理逻辑,同意这个方案。其实很多地方都可以通过类似的兼容方案进行处理,比如第一个非预期弹框,也可以算是异常场景的兼容处理。 - 页面延迟:
重试机制确实是个好办法,但是如果用例都是因为重试才执行正确,有可能会漏出和缓存相关的问题,因为重试应该算一个独立测试场景了,现在是把它作为主要测试场景了。
这地方我记得 selenium 有一个函数可以设定一个最大超时时间,在这个时间之前都会等待,一旦超时时间内满足了继续执行的条件,也可以立刻执行,这个方法还是比较不错的,既保证了用例操作的预期性,也解决了延迟的不可控的问题。 - 测试数据问题:
构造自动化数据时要特别注意,构造一些带特殊字段的数据库信息,最好是超出常人操作的数据信息,这样可以有效避免数据被误修改的风险,当然,还有一个处理办法在 15 讲的时候提到过,就是先检查测试数据是否存在/异常,不存在或异常都进行重建即可,这部分也算是测试代码的兼容处理吧。
ps:「问题步骤记录器」,直接在运行框输入 psr.exe ,评论区看到的,尝试一下挺好用的 ;
前端测试框架
Jest 是由 Facebook 发布的,是一个基于 Jasmine 的开源 JavaScript 单元测试框架,是目前主流的 JavaScript 单元测试方案
移动测试的专项测试
移动应用专项测试的思路和方法
对于移动应用,顺利完成全部业务功能测试往往是不够的。如果你的关注点只是业务功能测试,那么,当你的移动应用被大量用户安装和使用时,就会暴露出很多之前完全没有预料到的问题,比如:
- 流量使用过多;
- 耗电量过大;
- 在某些设备终端上出现崩溃或者闪退的现象;
- 多个移动应用相互切换后,行为异常;
- 在某些设备终端上无法顺利安装或卸载;
- 弱网络环境下,无法正常使用;
- Android 环境下,经常出现 ANR(Application Not Responding);
交叉事件测试、兼容性测试、流量测试、耗电量测试、弱网络测试、边界测试这 6 个最主要的专项测试来展开。
交叉事件测试
- 多个 App 同时在后台运行,并交替切换至前台是否影响正常功能;
- 要求相同系统资源的多个 App 前后台交替切换是否影响正常功能,比如两个 App 都需要播放音乐,那么两者在交替切换的过程中,播放音乐功能是否正常;
- App 运行时接听电话;
- App 运行时接收信息;
- App 运行时提示系统升级;
- App 运行时发生系统闹钟事件;
- App 运行时进入低电量模式;
- App 运行时第三方安全软件弹出告警;
- App 运行时发生网络切换,比如,由 Wifi 切换到移动 4G 网络,或者从 4G 网络切换到 3G 网络等;
兼容性测试
概念
通常都需要在各种真机上执行相同或者类似的测试用例,所以往往采用自动化测试的手段。 同时,由于需要覆盖大量的真实设备,除了大公司会基于 Appium + Selenium Grid + OpenSTF 去搭建自己的移动设备私有云平台外,其他公司一般都会使用第三方的移动设备云测平台完成兼容性测试。
平台
第三方的移动设备云测平台,国外最知名的是 SauceLab,国内主流的是 Testin。
场景
- 不同操作系统的兼容性,包括主流的 Andoird 和 iOS 版本;
- 主流的设备分辨率下的兼容性;
- 主流移动终端机型的兼容性;
- 同一操作系统中,不同语言设置时的兼容性;
- 不同网络连接下的兼容性,比如 Wifi、GPRS、EDGE、CDMA200 等;
- 在单一设备上,与主流热门 App 的兼容性,比如微信、抖音、淘宝等;
流量测试
场景
- App 执行业务操作引起的流量;
- App 在后台运行时的消耗流量;
- App 安装完成后首次启动耗费的流量;
- App 安装包本身的大小;
- App 内购买或者升级需要的流量。
工具
往借助于 Android 和 iOS 自带的工具进行流量统计,也可以利用 tcpdump、Wireshark 和 Fiddler 等网络分析工具。
对于 Android 系统,网络流量信息通常存储在 /proc/net/dev 目录下,也可以直接利用 ADB 工具获取实时的流量信息。另外,我还推荐一款 Android 的轻量级性能监控小工具 Emmagee,类似于 Windows 系统性能监视器,能够实时显示 App 运行过程中 CPU、内存和流量等信息。
对于 iOS 系统,可以使用 Xcode 自带的性能分析工具集中的 Network Activity,分析具体的流量使用情况。
控制流量的方法
- 启用数据压缩,尤其是图片;
- 使用优化的数据格式,比如同样信息量的 JSON 文件就要比 XML 文件小;
- 遇到既需要加密又需要压缩的场景,一定是先压缩再加密;
- 减少单次 GUI 操作触发的后台调用数量;
- 每次回传数据尽可能只包括必要的数据;
- 启用客户端的缓存机制;
耗电量测试
场景
- App 运行但没有执行业务操作时的耗电量;
- App 运行且密集执行业务操作时的耗电量;
- App 后台运行的耗电量。
方法
- Android 通过 adb 命令“adb shell dumpsys battery”来获取应用的耗电量信息;Google推出的history batterian工具
- iOS 通过 Apple 的官方工具 Sysdiagnose 来收集耗电量信息,然后,可以进一步通过 Instrument 工具链中的 Energy Diagnostics 进行耗电量分析。
弱网络测试
场景
经常出现需要在不同网络之间切换的场景,即使是在同一网络环境下,也会出现网络连接状态时好时坏的情况,比如时高时低的延迟、经常丢包、频繁断线,在乘坐地铁、穿越隧道,和地下车库的场景
工具
Facebook 的 Augmented Traffic Control(ATC)。
边界测试
场景
- 系统内存占用大于 90% 的场景;
- 系统存储占用大于 95% 的场景;
- 飞行模式来回切换的场景;
- App 不具有某些系统访问权限的场景,比如 App 由于隐私设置不能访问相册或者通讯录等;
- 长时间使用 App,系统资源是否有异常,比如内存泄漏、过多的链接数等;
- 出现 ANR 的场景;
- 操作系统时间早于或者晚于标准时间的场景;
- 时区切换的场景;
入门Appium的教程
官网的教程很烂,实现完没什么用,可以参考下面
https://www.cnblogs.com/liguo-wang/p/10782831.html
API 测试
步骤:
- 准备测试数据(这是可选步骤,不一定所有 API 测试都需要这一步);
- 通过 API 测试工具,发起对被测 API 的 request;
- 验证返回结果的 response。
API 测试工具
常见的命令行工具 cURL、图形界面工具 Postman 或者 SoapUI、API 性能测试的 JMeter 等。
详细的工具使用
https://www.cnblogs.com/liguo-wang/p/10782947.html
API测试的发展
早期基于 Postman 的 API 测试问题
-
当需要频繁执行大量的测试用例时,基于界面的 API 测试就显得有些笨拙;
-
基于界面操作的测试难以与 CI/CD 流水线集成。
基于 Postman 和 Newman 的 API 测试
于是就出现了集成 Postman 和 Newman 的方案,然后再结合 Jenkins 就可以很方便地实现 API 测试与 CI/CDl 流水线的集成。Newman 其实就是一个命令行工具,可以直接执行 Postman 导出的测试用例。
基于代码的 API 测试
为了解决这个问题,于是就出现了基于代码的 API 测试框架。比较典型的是,基于 Java 的 OkHttP 和 Unirest、基于 Python 的 http.client 和 Requests、基于 NodeJS 的 Native 和 Request 等。
Response结果发生变化时的自动识别
在 API 测试框架里引入一个内建数据库,推荐采用非关系型数据库(比如 MongoDB),然后用这个数据库记录每次调用的 request 和 response 的组合,当下次发送相同 request 时,API 测试框架就会自动和上次的 response 做差异检测,对于有变化的字段给出告警。
你可能会说这种做法也有问题,因为有些字段的值每次 API 调用都是不同的,比如 token 值、session ID、时间戳等,这样每次的调用就都会有告警。
但是这个问题很好解决,现在的解决办法是通过规则配置设立一个“白名单列表”,把那些动态值的字段排除在外。
微服务架构的测试
什么是微服务架构
- 每个服务运行在其独立的进程中,开发采用的技术栈也是独立的;
- 服务间采用轻量级通信机制进行沟通,通常是基于 HTTP 协议的 RESTful API;
- 每个服务都围绕着具体的业务进行构建,并且能够被独立开发、独立部署、独立发布;
- 对运维提出了非常高的要求,促进了 CI/CD 的发展与落地。
怎么做
基于消费者契约的 API 测试。todo
代码级测试
人工静态方法
本质上通过开发人员代码走查、结对编程、同行评审来完成的,理论上可以发现所有的代码错误,但也因为其对“测试人员”的过渡依赖,局限性非常大;
自动静态方法
- 主要的手段是代码静态扫描,可以发现语法特征错误、边界行为特征错误和经验特征错误这三类“有特征”的错误;
人工动态方法
就是传统意义上的单元测试,是发现算法错误和部分算法错误的最佳方式
自动动态方法
其实就是自动化的边界测试,主要覆盖边界行为特征错误。
软件性能与性能指标
终端用户、系统运维人员、软件设计开发人员,性能测试人员,
-
终端用户希望自己的业务操作越快越好;
-
系统运维人员追求系统整体的容量和稳定;
-
开发人员以“性能工程”的视角关注实现过程的性能;
-
软件性能通常会包含算法设计、架构设计、性能最佳实践、数据库相关、软件性能的可测试性这五大方面
-
第一,算法设计包含的点:
- 核心算法的设计与实现是否高效;
- 必要时,设计上是否采用 buffer 机制以提高性能,降低 I/O;
- 是否存在潜在的内存泄露;
- 是否存在并发环境下的线程安全问题;
- 是否存在不合理的线程同步方式;
- 是否存在不合理的资源竞争。
第二,架构设计包含的内容:
- 站在整体系统的角度,是否可以方便地进行系统容量和性能扩展;
- 应用集群的可扩展性是否经过测试和验证;
- 缓存集群的可扩展性是否经过测试和验证;
- 数据库的可扩展性是否经过测试和验证。
第三,性能最佳实践包含的点:
- 代码实现是否遵守开发语言的性能最佳实践;
- 关键代码是否在白盒级别进行性能测试;
- 是否考虑前端性能的优化;
- 必要的时候是否采用数据压缩传输;
- 对于既要压缩又要加密的场景,是否采用先压缩后加密的顺序。
第四,数据库相关的点:
- 数据库表设计是否高效;
- 是否引入必要的索引;
- SQL 语句的执行计划是否合理;
- SQL 语句除了功能是否要考虑性能要求;
- 数据库是否需要引入读写分离机制;
- 系统冷启动后,缓存大量不命中的时候,数据库承载的压力是否超负荷。
第五,软件性能的可测试性包含的点:
- 是否为性能分析(Profiler)提供必要的接口支持;
- 是否支持高并发场景下的性能打点;
- 是否支持全链路的性能分析。
-
-
-
性能测试人员需要全盘考量、各个击破。
性能的三个最常用的指标:并发用户数,响应时间,系统吞吐量:
- 并发用户数包含不同层面的含义,既可以指实际的并发用户数,也可以指服务器端的并发数量;
- 响应时间也包含两层含义,技术层面的标准定义和基于用户主观感受时间的定义;
- 系统吞吐量是最能直接体现软件系统承受负载能力的指标,但也必须和其他指标一起使用才能更好地说明问题。
性能测试的基本方法,应用领域
分类性能测试方法分为七大类
后端性能测试(Back-end Performance Test)、前端性能测试(Front-end Performance Test)、代码级性能测试(Code-level Performance Test)、压力测试(Load/Stress Test)、配置测试(Configuration Test)、并发测试(Concurrence Test),以及可靠性测试(Reliability Test)。接下来,我将详细为你介绍每一种测试方法。
后端
除了包括并发用户数、响应时间和系统吞吐量外,还应该包括各类资源的使用率,比如系统级别的 CPU 占用率、
内存使用率、磁盘 I/O 和网络 I/O 等,再比如应用级别以及 JVM 级别的各类资源使用率指标等。
前端
- 减少 http 请求次数:http 请求数量越多,执行过程耗时就越长,所以可以采用合并多个图片到一个图片文件的方法来减少 http 请求次数,也可以采用将多个脚本文件合并成单一文件的方式减少 http 请求次数;
- 减少 DNS 查询次数:DNS 的作用是将 URL 转化为实际服务器主机 IP 地址,实现原理是分级查找,查找过程需要花费 20~100ms 的时间,所以一方面我们要加快单次查找的时间,另一方面也要减少一个页面中资源使用了多个不同域的情况;
- 避免页面跳转:页面跳转相当于又打开一个新的页面,耗费的时间就会比较长,所以要尽量避免使用页面跳转;
- 使用内容分发网络(CDN):使用 CDN 相当于对静态内容做了缓存,并把缓存内容放在网络供应商(ISP)的机房,用户根据就近原则到 ISP 机房获取这些被缓存了的静态资源,因此可以大幅提高性能;
- Gzip 压缩传输文件:压缩可以帮助减小传输文件的大小,进而可以从网络传输时间的层面来减少响应时间;
代码级
改造现有的单元测试框架。最常使用的改造方法是:
- 将原本只会执行一次的单元测试用例连续执行 n 次,这个 n 的取值范围通常是 2000~5000;
- 统计执行 n 次的平均时间。如果这个平均时间比较长(也就是单次函数调用时间比较长)的话,比如已经达到了秒级,那么通常情况下这个被测函数的实现逻辑一定需要优化。
压力测试
故意在临界饱和状态的基础上继续施加压力,直至系统完全瘫痪,观察这个期间系统的行为;然后,逐渐减小压力,观察瘫痪的系统是否可以自愈。
配置测试
- 宿主操作系统的配置;
- 应用服务器的配置;
- 数据库的配置;
- JVM 的配置;
- 网络环境的配置;
并发测试
为了达到准确控制后端服务并发数的目的,我们需要让某些并发用户到达该集合点时,先处于等待状态,直到参与该集合的全部并发用户都到达时,再一起向后端服务发起请求。
可靠性测试
能力验证、能力规划、性能调优、缺陷发现
后端性能测试工具原理与行业常用工具
后端测试的原理
后端性能测试工具会基于客户端与服务器端的通信协议,构建模拟业务操作的虚拟用户脚本。对于目前主流的 Web 应用,通常是基于 HTTP/HTTPS 协议;对于 Web Service 应用,是基于 Web Service 协议
本质上都是通过协议模拟用户的行为
场景

业内主流的后端性能测试工具有哪些?
传统的 LoadRunner、JMeter、NeoLoad 等。现在还有很多云端部署的后端性能测试工具或平台,比如 CloudTest、Loadstorm、阿里的 PTS 等。
其中,最为常用的商业工具是 HP 软件(现在已经被 Micro Focus 收购)的 LoadRunner,由于其强大的功能和广泛的协议支持。大量的传统软件企业,也基本都使用 LoadRunner 实施性能测试,所以我在后面分享企业级服务器端性能测试的实践时,也是以 LoadRunner 为基础展开的。
另外,JMeter 是目前开源领域最主流的性能测试工具。JMeter 的功能非常灵活,能够支持 HTTP、FTP、数据库的性能测试,也能够充当 HTTP 代理来录制浏览器的 HTTP 请求,还可以根据 Apache 等 Web 服务器的日志文件回放 HTTP 流量,还可以通过扩展支持海量的并发。
其实,传统软件企业偏向于使用 LoadRunner,而互联网企业普遍采用 JMeter,是有原因的。
LoadRunner License 是按照并发用户数收费的,并发用户数越高收费也越贵,但是 LoadRunner 的脚本开发功能、执行控制、系统监控以及报告功能都非常强大,易学易用。
而传统软件企业,需要测试的并发用户数并不会太高,通常是在几百到十几万这个数量级,而且它们很在意软件的易用性和官方支持能力,所以往往热衷于直接选择成熟的商业工具 LoadRunner。
但是,互联网企业的并发用户请求数量很高,很多软件都会达到百万,甚至是千万的级别。那么,如果使用 LoadRunner 的话:
- 费用会高的离谱;
- LoadRunner 对海量并发的测试支持并不太好;
- 很多互联网企业还会有特定的工具需求,这些特定的需求很难在 LoadRunner 中实现,而在开源的 JMeter 中,用户完全可以根据需求进行扩展。
所以互联网企业往往选用 JMeter 方案,而且通常会自己维护扩展版本。
前端性能测试工具原理工具
工具:WebPagetest
测试指标
第一,First Byte Time
First Byte Time,指的是用户发起页面请求到接收到服务器返回的第一个字节所花费的时间。这个指标反映了后端服务器处理请求、构建页面,并且通过网络返回所花费的时间。
第二,Keep-alive Enabled
页面上的各种资源(比如,图片、JavaScript、CSS 等)都需要通过链接 Web 服务器来一一获取,与服务器建立新链接的过程往往比较耗费时间,所以理想的做法是尽可能重用已经建立好的链接,而避免每次使用都去创建新的链接。Keep-alive Enabled 就是,要求每次请求使用已经建立好的链接。它属于服务器上的配置,不需要对页面本身进行任何更改,启用了 Keep-alive 通常可以将加载页面的时间减少 40%~50%,页面的请求数越多,能够节省的时间就越多。
第三,Compress Transfer
如果将页面上的各种文本类的资源,比如 Html、JavaScript、CSS 等,进行压缩传输,将会减少网络传输的数据量,同时由于 JavaScript 和 CSS 都是页面上最先被加载的部分,所以减小这部分的数据量会加快页面的加载速度,同时也能缩短 First Byte Time。
第四,CDN
CDN 是内容分发网络的缩写,其基本原理是采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区的网络供应商机房内,当用户访问网站时,利用全局负载技术将用户的访问指向距离最近的、工作正常的缓存服务器上,由缓存服务器直接响应用户请求。
LoadRunner企业级服务器端测试
是什么
后端性能测试工具首先通过虚拟用户脚本生成器生成基于协议的虚拟用户脚本,然后根据性能测试场景设计的要求,通过压力控制器控制协调各个压力产生器以并发的方式执行虚拟用户脚本,并且在测试执行过程中,通过系统监控器收集各种性能指标以及系统资源占用率,最后通过测试结果分析器展示测试结果数据。
为什么

- 测试协调员以及完成数据记录的部分就是 Controller 模块;
- 大量的测试机器以及操作这些测试机器的人就是 Load Generator 模块;
- 操作这些测试机器的人的行为就是 Virtual User Generator 产生的虚拟用户脚本;
- 对测试数据的分析就是 Analysis 模块。
controller模块:
怎么做
测试过程划分成了五个阶段:性能需求收集以及负载计划制定、录制并增强虚拟用户脚本、创建并定义性能测试场景、执行性能测试场景,以及分析测试报告。