Semi-supervised Classification on a Text Dataset
https://scikit-learn.org/stable/auto_examples/semi_supervised/plot_semi_supervised_newsgroups.html#sphx-glr-auto-examples-semi-supervised-plot-semi-supervised-newsgroups-py
使用20新闻组数据集合, 演示半监督学习分类器。
In this example, semi-supervised classifiers are trained on the 20 newsgroups dataset (which will be automatically downloaded).
You can adjust the number of categories by giving their names to the dataset loader or setting them to
Noneto get all 20 of them.
Code
import os import numpy as np from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.preprocessing import FunctionTransformer from sklearn.linear_model import SGDClassifier from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.semi_supervised import SelfTrainingClassifier from sklearn.semi_supervised import LabelSpreading from sklearn.metrics import f1_score data = fetch_20newsgroups(subset='train', categories=None) print("%d documents" % len(data.filenames)) print("%d categories" % len(data.target_names)) print() # Parameters sdg_params = dict(alpha=1e-5, penalty='l2', loss='log') vectorizer_params = dict(ngram_range=(1, 2), min_df=5, max_df=0.8) # Supervised Pipeline pipeline = Pipeline([ ('vect', CountVectorizer(**vectorizer_params)), ('tfidf', TfidfTransformer()), ('clf', SGDClassifier(**sdg_params)), ]) # SelfTraining Pipeline st_pipeline = Pipeline([ ('vect', CountVectorizer(**vectorizer_params)), ('tfidf', TfidfTransformer()), ('clf', SelfTrainingClassifier(SGDClassifier(**sdg_params), verbose=True)), ]) # LabelSpreading Pipeline ls_pipeline = Pipeline([ ('vect', CountVectorizer(**vectorizer_params)), ('tfidf', TfidfTransformer()), # LabelSpreading does not support dense matrices ('todense', FunctionTransformer(lambda x: x.todense())), ('clf', LabelSpreading()), ]) def eval_and_print_metrics(clf, X_train, y_train, X_test, y_test): print("Number of training samples:", len(X_train)) print("Unlabeled samples in training set:", sum(1 for x in y_train if x == -1)) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print("Micro-averaged F1 score on test set: " "%0.3f" % f1_score(y_test, y_pred, average='micro')) print("-" * 10) print() if __name__ == "__main__": X, y = data.data, data.target X_train, X_test, y_train, y_test = train_test_split(X, y) print("Supervised SGDClassifier on 100% of the data:") eval_and_print_metrics(pipeline, X_train, y_train, X_test, y_test) # select a mask of 20% of the train dataset y_mask = np.random.rand(len(y_train)) < 0.2 # X_20 and y_20 are the subset of the train dataset indicated by the mask X_20, y_20 = map(list, zip(*((x, y) for x, y, m in zip(X_train, y_train, y_mask) if m))) print("Supervised SGDClassifier on 20% of the training data:") eval_and_print_metrics(pipeline, X_20, y_20, X_test, y_test) # set the non-masked subset to be unlabeled y_train[~y_mask] = -1 print("SelfTrainingClassifier on 20% of the training data (rest " "is unlabeled):") eval_and_print_metrics(st_pipeline, X_train, y_train, X_test, y_test) if 'CI' not in os.environ: # LabelSpreading takes too long to run in the online documentation print("LabelSpreading on 20% of the data (rest is unlabeled):") eval_and_print_metrics(ls_pipeline, X_train, y_train, X_test, y_test)
Output
11314 documents 20 categories Supervised SGDClassifier on 100% of the data: Number of training samples: 8485 Unlabeled samples in training set: 0 Micro-averaged F1 score on test set: 0.909 ---------- Supervised SGDClassifier on 20% of the training data: Number of training samples: 1688 Unlabeled samples in training set: 0 Micro-averaged F1 score on test set: 0.791 ---------- SelfTrainingClassifier on 20% of the training data (rest is unlabeled): Number of training samples: 8485 Unlabeled samples in training set: 6797 End of iteration 1, added 2852 new labels. End of iteration 2, added 694 new labels. End of iteration 3, added 183 new labels. End of iteration 4, added 68 new labels. End of iteration 5, added 37 new labels. End of iteration 6, added 31 new labels. End of iteration 7, added 11 new labels. End of iteration 8, added 8 new labels. End of iteration 9, added 4 new labels. End of iteration 10, added 2 new labels. Micro-averaged F1 score on test set: 0.835 ----------
SelfTrainingClassifier
https://scikit-learn.org/stable/modules/generated/sklearn.semi_supervised.SelfTrainingClassifier.html#sklearn.semi_supervised.SelfTrainingClassifier
自训练分类器,输入监督型的分类器, 允许学习无标签的数据。
循环预测假标签,直到达到最大循环次数,或者没有假标签添加到训练集合。
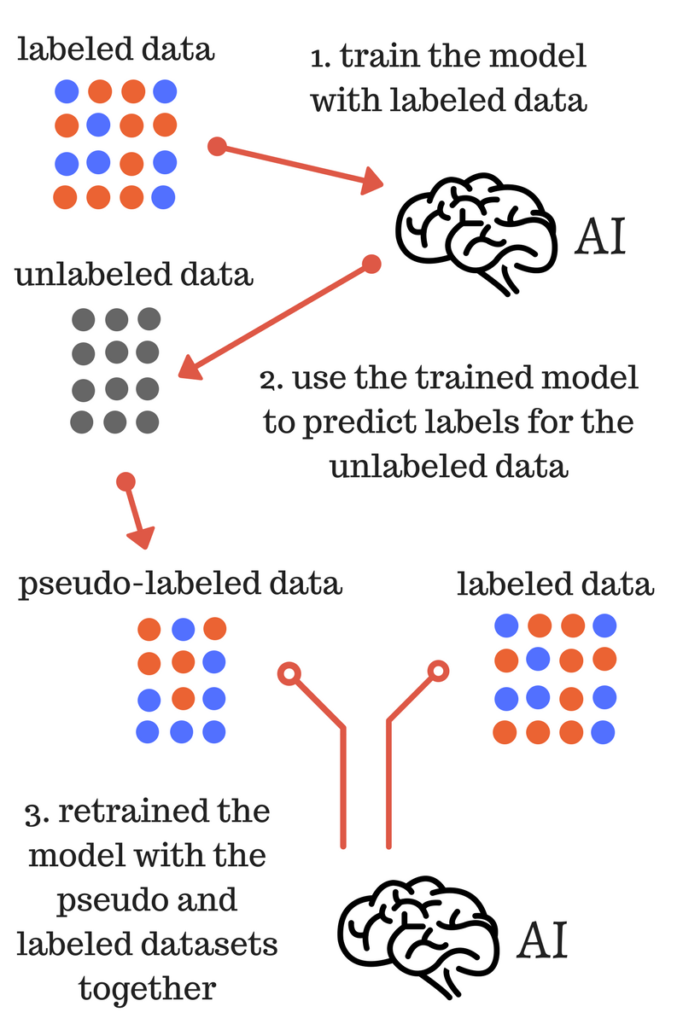
Self-training classifier.
This class allows a given supervised classifier to function as a semi-supervised classifier, allowing it to learn from unlabeled data. It does this by iteratively predicting pseudo-labels for the unlabeled data and adding them to the training set.
The classifier will continue iterating until either max_iter is reached, or no pseudo-labels were added to the training set in the previous iteration.
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import SelfTrainingClassifier >>> from sklearn.svm import SVC >>> rng = np.random.RandomState(42) >>> iris = datasets.load_iris() >>> random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3 >>> iris.target[random_unlabeled_points] = -1 >>> svc = SVC(probability=True, gamma="auto") >>> self_training_model = SelfTrainingClassifier(svc) >>> self_training_model.fit(iris.data, iris.target) SelfTrainingClassifier(...)
LabelSpreading
https://scikit-learn.org/stable/modules/generated/sklearn.semi_supervised.LabelSpreading.html#sklearn.semi_supervised.LabelSpreading
标签扩展, 类似于基础的标签传播算法, 但是使用亲密度矩阵。
LabelSpreading model for semi-supervised learning
This model is similar to the basic Label Propagation algorithm, but uses affinity matrix based on the normalized graph Laplacian and soft clamping across the labels.
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import LabelSpreading >>> label_prop_model = LabelSpreading() >>> iris = datasets.load_iris() >>> rng = np.random.RandomState(42) >>> random_unlabeled_points = rng.rand(len(iris.target)) < 0.3 >>> labels = np.copy(iris.target) >>> labels[random_unlabeled_points] = -1 >>> label_prop_model.fit(iris.data, labels) LabelSpreading(...)
f1_score
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score
此标准是 精确度 和 召回率的一个调和。
Compute the F1 score, also known as balanced F-score or F-measure.
The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal. The formula for the F1 score is:
F1 = 2 * (precision * recall) / (precision + recall)In the multi-class and multi-label case, this is the average of the F1 score of each class with weighting depending on the
averageparameter.
>>> from sklearn.metrics import f1_score >>> y_true = [0, 1, 2, 0, 1, 2] >>> y_pred = [0, 2, 1, 0, 0, 1] >>> f1_score(y_true, y_pred, average='macro') 0.26... >>> f1_score(y_true, y_pred, average='micro') 0.33... >>> f1_score(y_true, y_pred, average='weighted') 0.26... >>> f1_score(y_true, y_pred, average=None) array([0.8, 0. , 0. ]) >>> y_true = [0, 0, 0, 0, 0, 0] >>> y_pred = [0, 0, 0, 0, 0, 0] >>> f1_score(y_true, y_pred, zero_division=1) 1.0...
https://en.wikipedia.org/wiki/F-score
In statistical analysis of binary classification, the F-score or F-measure is a measure of a test's accuracy. It is calculated from the precision and recall of the test, where the precision is the number of correctly identified positive results divided by the number of all positive results, including those not identified correctly, and the recall is the number of correctly identified positive results divided by the number of all samples that should have been identified as positive. Precision is also known as positive predictive value, and recall is also known as sensitivity in diagnostic binary classification.
The F1 score is the harmonic mean of the precision and recall. The more generic

 score applies additional weights, valuing one of precision or recall more than the other.
score applies additional weights, valuing one of precision or recall more than the other. 半监督学习
https://www.cnblogs.com/kamekin/p/9683162.html
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习(semi-supervised learning)。
要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设。假设的本质是“相似的样本拥有相似的输出”。
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning),前者假定训练数据中的未标记样本并非待测的数据,
而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。