目录
Generalization: Peril of Overfitting
Low loss, but still a bad model?
How Do We Know If Our Model Is Good?
What If We Only Have One Data Set?
Generalization: Peril of Overfitting
- Develop intuition about overfitting.
- Determine whether a model is good or not.
- Divide a data set into a training set and a test set.
Low loss, but still a bad model?

The model overfits the peculiarities of the data it trained on.
An overfit model gets a low loss during training but does a poor job predicting new data.
Overfitting is caused by making a model more complex than necessary.
The fundamental tension of machine learning is between fitting our data well, but also fitting the data as simply as possible.
How Do We Know If Our Model Is Good?
- Theoretically:
- Interesting field: generalization theory
- Based on ideas of measuring model simplicity / complexity
- Intuition: formalization of Occam's Razor principle
- The less complex a model is, the more likely that a good empirical result is not just due to the peculiarities of our sample
- Empirically:
- Asking: will our model do well on a new sample of data?
- Evaluate: get a new sample of data-call it the test set
- Good performance on the test set is a useful indicator of good performance on the new data in general:
- If the test set is large enough
- If we don't cheat by using the test set over and over
The ML Fine Print
Three basic assumptions
- We draw examples independently and identically (i.i.d.独立同分布) at random from the distribution
- The distribution is stationary: It doesn't change over time
- We always pull from the same distribution: Including training, validation, and test sets
In practice, we sometimes violate these assumptions. For example:
- Consider a model that chooses ads to display. The i.i.d. assumption would be violated if the model bases its choice of ads, in part, on what ads the user has previously seen.
- Consider a data set that contains retail sales information for a year. User's purchases change seasonally, which would violate stationarity.
When we know that any of the preceding three basic assumptions are violated, we must pay careful attention to metrics.
Summary
Overfitting occurs when a model tries to fit the training data so closely that it does not generalize well to new data.
- If the key assumptions of supervised ML are not met, then we lose important theoretical guarantees on our ability to predict on new data.
Glossay
generalization:refers to your model's ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model.
overfitting:occurs when a model tries to fit the training data so closely that it does not generalize well to new data.
stationarity:A property of data in a data set, in which the data distribution stays constant across one or more dimensions. Most commonly, that dimension is time, meaning that data exhibiting stationarity doesn't change over time. For example, data that exhibits stationarity doesn't change from September to December.
- training set:The subset of the data set used to train a model.
- validation set:A subset of the data set—disjunct from the training set—that you use to adjust hyperparameters.
- test set:The subset of the data set that you use to test your model after the model has gone through initial vetting by the validation set.
Training and Test Sets
- Examine the benefits of dividing a data set into a training set and a test set.
What If We Only Have One Data Set?
- Divide into two sets:
- training set
- test set
- Classic gotcha: do not train on test data
- Getting surprisingly low loss?
- Before celebrating, check if you're accidentally training on test data
Splitting Data
Make sure that your test set meets the following two conditions:
- Is large enough to yield statistically meaningful results.
- Is representative of the data set as a whole. In other words, don't pick a test set with different characteristics than the training set.
Assuming that your test set meets the preceding two conditions, your goal is to create a model that generalizes well to new data. Our test set serves as a proxy for new data.
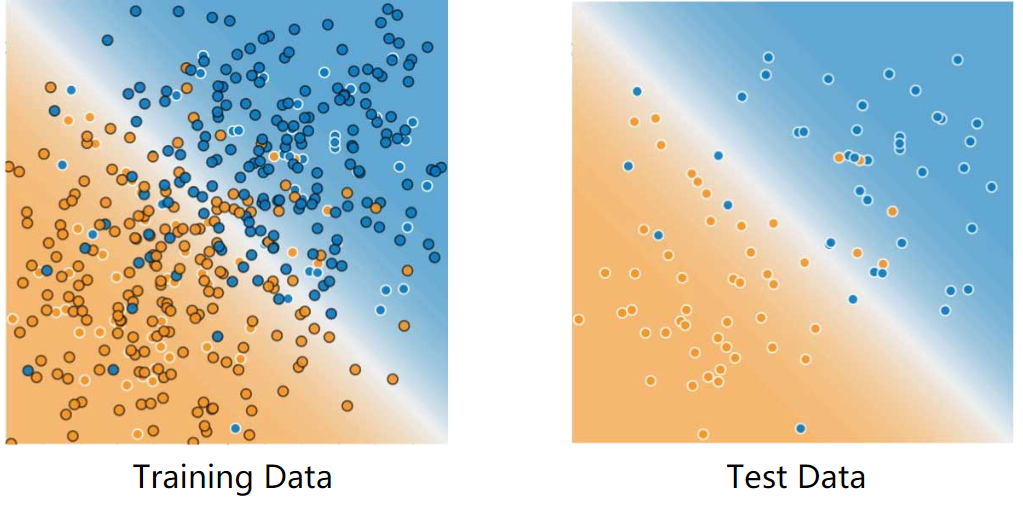
For example, consider the following figure. Notice that the model learned for the training data is very simple. This model doesn't do a perfect job—a few predictions are wrong. However, this model does about as well on the test data as it does on the training data. In other words, this simple model does not overfit the training data.
Never train on test data. If you are seeing surprisingly good results on your evaluation metrics, it might be a sign that you are accidentally training on the test set. For example, high accuracy might indicate that test data has leaked into the training set.
For example, consider a model that predicts whether an email is spam, using the subject line, email body, and sender's email address as features. We apportion the data into training and test sets, with an 80-20 split. After training, the model achieves 99% precision on both the training set and the test set. We'd expect a lower precision on the test set, so we take another look at the data and discover that many of the examples in the test set are duplicates of examples in the training set (we neglected to scrub duplicate entries for the same spam email from our input database before splitting the data). We've inadvertently trained on some of our test data, and as a result, we're no longer accurately measuring how well our model generalizes to new data.
Validation
Check Your Intuition
We looked at a process of using a test set and a training set to drive iterations of model development. On each iteration, we'd train on the training data and evaluate on the test data, using the evaluation results on test data to guide choices of and changes to various model hyperparameters like learning rate and features. Is there anything wrong with this approach? (Pick only one answer.)
- (F)This is computationally inefficient. We should just pick a default set of hyperparameters and live with them to save resources.
Although these sorts of iterations are expensive, they are a critical part of model development. Hyperparameter settings can make an enormous difference in model quality, and we should always budget some amount of time and computational resources to ensure we're getting the best quality we can.
- (T)Doing many rounds of this procedure might cause us to implicitly fit to the peculiarities of our specific test set.
Yes indeed! The more often we evaluate on a given test set, the more we are at risk for implicitly overfitting to that one test set. We'll look at a better protocol next.
- (F)Totally fine, we're training on training data and evaluating on separate, held-out test data.
Actually, there's a subtle issue here. Think about what might happen if we did many, many iterations of this form.
Validation
- Understand the importance of a validation set in a partitioning scheme.
Partitioning a data set into a training set and test set lets you judge whether a given model will generalize well to new data. However, using only two partitions may be insufficient when doing many rounds of hyperparameter tuning.
Another Partition
The previous module introduced partitioning a data set into a training set and a test set. This partitioning enabled you to train on one set of examples and then to test the model against a different set of examples.
With two partitions, the workflow could look as follows:
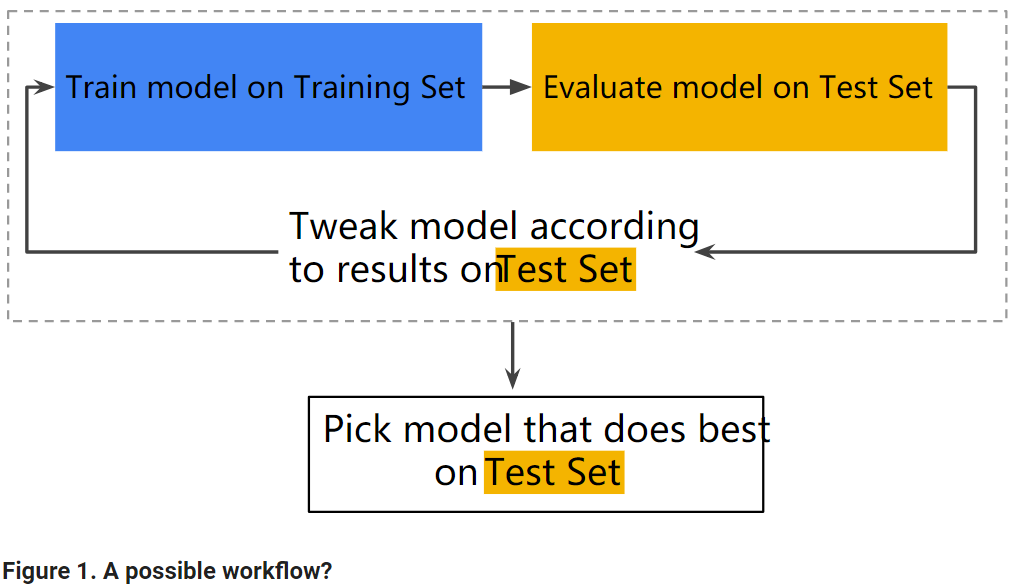
In the figure, "Tweak model" means adjusting anything about the model you can dream up—from changing the learning rate, to adding or removing features, to designing a completely new model from scratch. At the end of this workflow, you pick the model that does best on the test set.
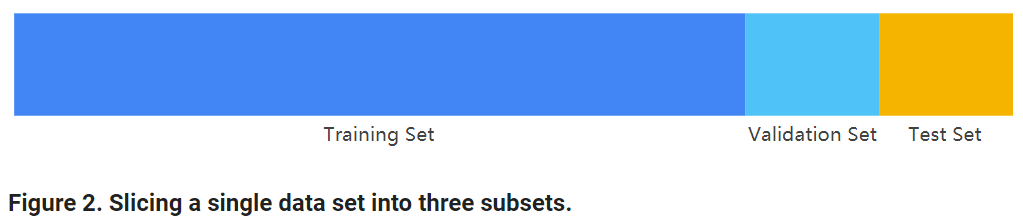
Dividing the data set into two sets is a good idea, but not a panacea. You can greatly reduce your chances of overfitting by partitioning the data set into the three subsets shown in the following figure:
Use the validation set to evaluate results from the training set. Then, use the test set to double-check your evaluation after the model has "passed" the validation set. The following figure shows this new workflow:
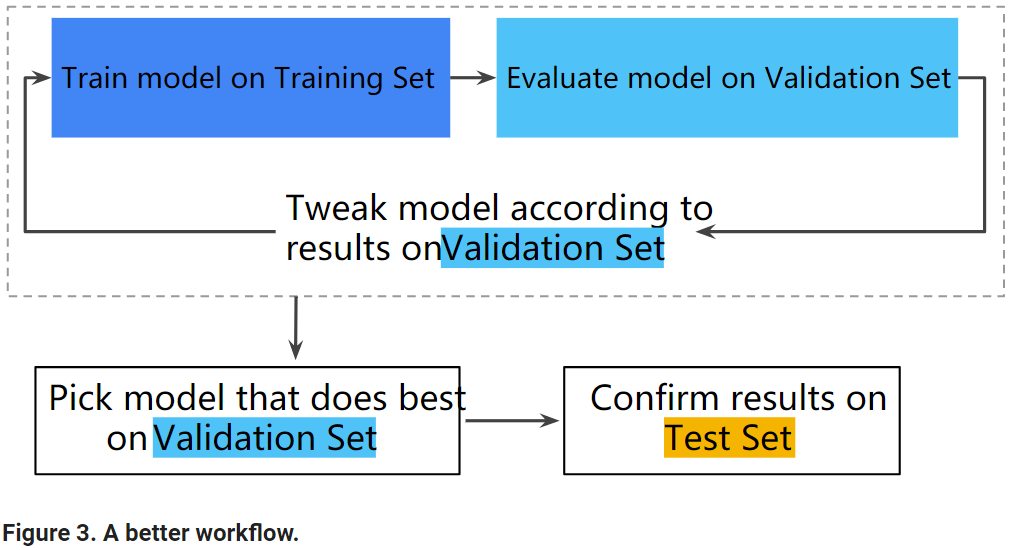
In this improved workflow:
- Pick the model that does best on the validation set.
- Double-check that model against the test set.
This is a better workflow because it creates fewer exposures to the test set.
Tip
- Test sets and validation sets "wear out" with repeated use. That is, the more you use the same data to make decisions about hyperparameter settings or other model improvements, the less confidence you'll have that these results actually generalize to new, unseen data. Note that validation sets typically wear out more slowly than test sets.
- If possible, it's a good idea to collect more data to "refresh" the test set and validation set. Starting anew is a great reset.
Programming Exercise
Learning Objectives:
- Use multiple features, instead of a single feature, to further improve the effectiveness of a model
- Debug issues in model input data
- Use a test data set to check if a model is overfitting the validation data