转载请注明源出处:http://www.cnblogs.com/lighten/p/7381905.html
1.前言
查看JDK源码总是能发现一些新东西,IdentityHashMap也是Map的一个子类,其也是一个有特性的Map。一样是通过Hash表的方法实现了Map接口,但是其比较键值是否相等的时候,并没有使用compare方法,而是使用是否是同一个引用来判断。所以k1和k2只有完全是同一个的时候才会相等k1==k2(通常是都不为null时k1.equals(k2)来判断)。
该类的一个典型使用是拓扑保存对象图的转换(topology-preserving object graph transformations),例如序列化或者是深度拷贝。要进行这样一个转换,程序必须保存节点表来追踪所有的已经产生了的对象引用。节点表不能将不同的对象看成是一样的,哪怕其值相等。另一个典型的运用就是保存代理对象。例如,调试工具可能希望为正在调试的程序中的每个对象维护一个代理对象。
IdentityHashMap同样允许空的键和值,但是不保证map中的顺序,尤其是不保证顺序会恒定不变。这个类有一个用于调优的参数--最大容量。这个参数用于确定最初包含哈希表的桶数。预期最大尺寸和桶数之间的精确关系未指定。map的大小超过预期值,桶的数量就会增加,这个过程的代价可能十分高,所以最好创建一个合适大小的map。但是另一方面,迭代器的性能与桶的数量成相关性,所以如果你关注迭代器的性能和内存使用,这个值不能设置的太大。
注意此map是线程不安全的。迭代器是快速失败的,请注意,迭代器的故障快速行为不能得到保证,一般来说,在未同步并发修改的情况下不可能做出任何硬保证。该特性只能用于检测bug。这是一个简单的线性探测哈希表。
2.IdentityHashMap
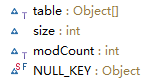
上图就是此map的一个基本数据结构了,就是一个数组hash表和一个size大小。默认大小32,实际初始化是2倍容量,如果自己传值x,其最终table大小是x<2n,等式成立时,最小的n时的2倍,具体看源代码。2倍大小是有原因的,和其结构有关,具体看下面。

System.identityHashCode(x);这个方法看源码上的注释,意思是会返回默认的hashCode()方法的值,不管该类有没有覆写hashCode()方法。查了一下好像这个值的计算与其在内存中所处地址有关,不同的对象内存地址肯定不相同,所以这样可以满足IdentityHashMap的需求。上面返回的都是偶数。

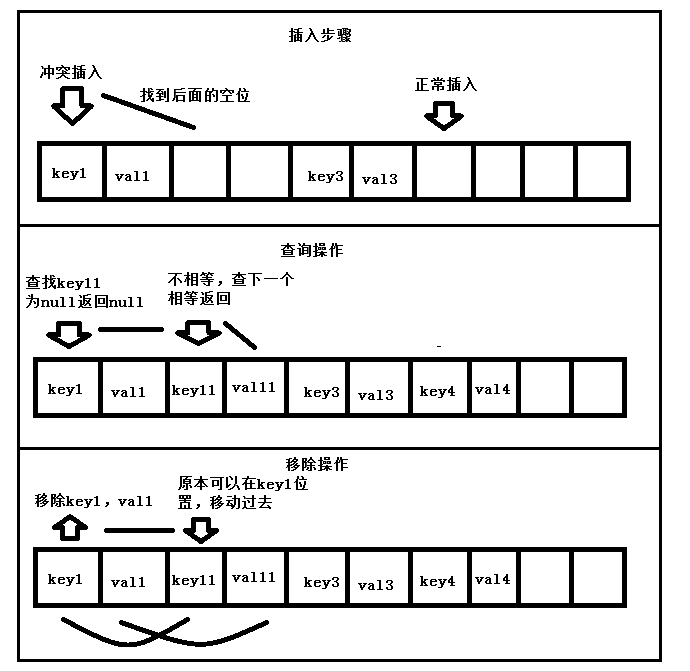
首先是处理了键为null的情况,然后算出hash值。循环判断,如果表中该位置与get的key是同一个,返回的是其后面的那个值。这里就可以看出实际的表为什么是容量的2倍了,因为其存储结构是key,value,key,value...。如果该位置为null,意味着表中没有该键,返回null。后面就是+2位进行查找了,这也就是此Hash表处理冲突的方法,并没有采取hashMap使用链表和树的方式,而是查找下面一个空位填入,这也就是为什么要弄成这种排列方式的原因。

put方法也验证了这一点。先假定put的key存在,就找到它并替换。没有找到的时候,预判容量,如果3倍的预期数量大于2倍的现在的容量,就要扩表。否者就是放入其中。

resize方法也较简单,不进行描述。其它的也只有remove方法了,remove方法要注意,由于put是有冲突的,所以其remove了一个函数后会检测后面是否由冲突导致的,会还原到其应该处在的位置。剩余的迭代器不进行描述。
3.图