树上点分治
思想
两个点之间的距离无非就是两种关系:我们约定(dis[i])表示这个点到当前根节点的距离
- (dis[u] + dis[v]),在同一个根节点的不同子树上。
- (dis[u] + dis[v]),在同一个根节点的同一个节点上。
树上点分治的思想就是通过改变根节点从而转化任意两点的距离为在同一个根节点下的情况。
举个例子
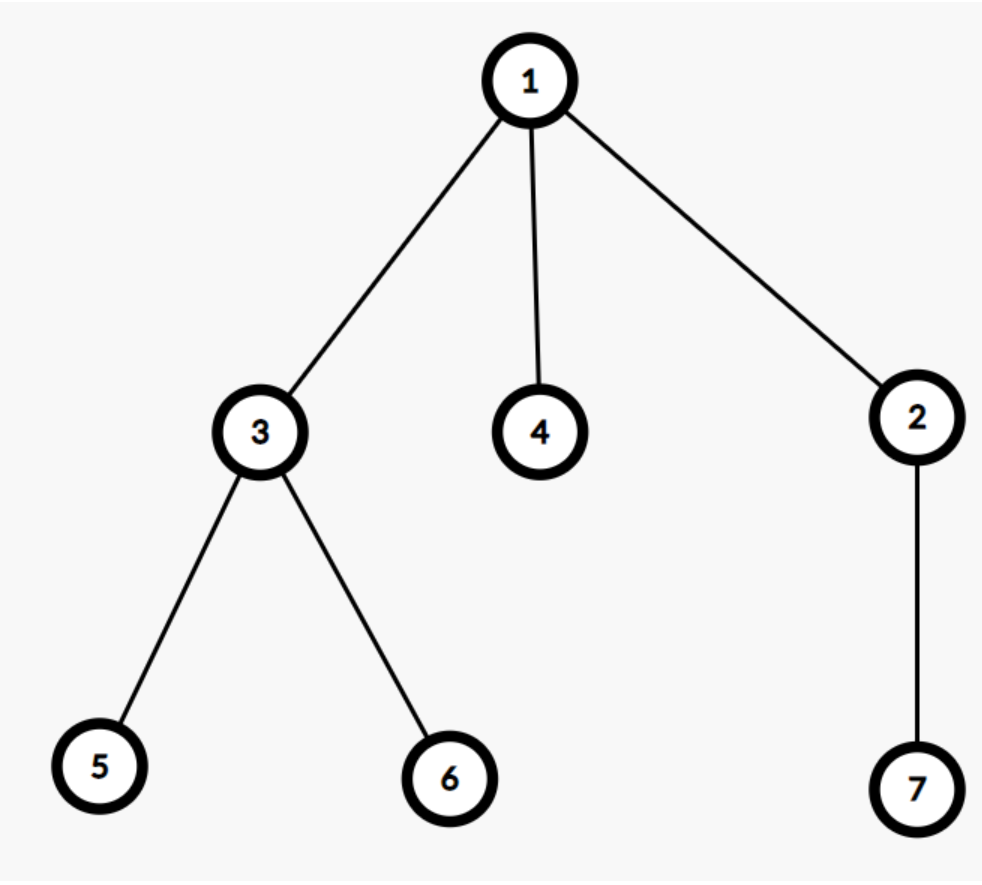
当我们选定1号节点作为我们的根节点时,我们可以简单的得到(三号节点的子树上的点到节点1, 4, 2, 7的距离,也就是不在三号节点子树上的点的距离)(4, 2子树同理)。
通过这一步转换我们只需要得到三号节点子树上的点之间的距离即可,这就是分治思想的体现,我们可以不断地递归最后只剩一个节点,这个节点的子树上的点到其子树上的点的距离就是确定的了,就是0嘛,只可能是它自己到它自己。
所以简而言之,点分治就是去不断地递归某个节点地子树,知道没有子树。
假如我们的点是连接成一串的,我们能任选一个点去当初始节点的子树吗?
这里显然是不能的,当我们选定的节点刚好是端点的时候,这个时候复杂度将会变成(n^2),这完全违背了我们优化其的初衷。
于是这里有一个简单的优化方法,就是每次我们选取每颗子树的重心去充当根节点,这样的分治效果显然是最优的。
于是我们的树上点分治算法好像已近逐渐可以写出来了,我们通过下面这个例子来更加理解一下实现过程吧。
P3806 【模板】点分治1 + 代码
/*
树上点分治
*/
#include <bits/stdc++.h>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 1e5 + 10;
int head[N], to[N << 1], nex[N << 1], value[N << 1], cnt = 1;
int sz[N], maxsz[N], dis[N], pre[N], vis[N], judge[10000010], is_true[110], query[110], q[N];
int n, m, sum, root;
inline int read() {
int f = 1, x = 0;
char c = getchar();
while(c < '0' || c > '9') {
if(c == '-') f = -1;
c = getchar();
}
while(c >= '0' && c <= '9') {
x = (x << 1) + (x << 3) + (c ^ 48);
c = getchar();
}
return f * x;
}
void get_root(int rt, int fa) {//简单的找重心
sz[rt] = 1, maxsz[rt] = 0;
for(int i = head[rt]; i; i = nex[i]) {
if(vis[to[i]] || to[i] == fa) continue;//加了一个vis判断,防止跑到已经访问过的根节点给上去。
get_root(to[i], rt);
maxsz[rt] = max(maxsz[rt], sz[to[i]]);
sz[rt] += sz[to[i]];
}
maxsz[rt] = max(maxsz[rt], sum - sz[rt]);
if(maxsz[rt] < maxsz[root]) root = rt;
}
void get_dis(int rt, int fa) {//就是dfs树上最短路的实现过程。
pre[++pre[0]] = dis[rt];//记录其子树的每个节点到根节点的距离。
for(int i = head[rt]; i; i = nex[i]) {
if(to[i] == fa || vis[to[i]]) continue;
dis[to[i]] = dis[rt] + value[i];
get_dis(to[i], rt);
}
}
void calc(int rt) {//核心。
int p = 0;
for(int i = head[rt]; i; i = nex[i]) {
if(vis[to[i]]) continue;//同样的也是访问子树。
dis[to[i]] = value[i];//这里一定要记得重置。
pre[0] = 0;
get_dis(to[i], rt);
for(int j = 1; j <= pre[0]; j++)//查询有没有点到当前子树的点的距离是符合query中的要求的。
for(int k = 1; k <= m; k++)
if(query[k] >= pre[j])
is_true[k] |= judge[query[k] - pre[j]];
for(int j = 1; j <= pre[0]; j++)//记录我们judge中被标记的点,方便在下一次分治之前重置。
if(pre[j] <= 1e7 + 5)//特判一下吧,题目的dis可能会到1e8,为了防止数组越界,
q[++p] = pre[j], judge[pre[j]] = 1;
}
for(int i = 1; i <= p; i++)//不用memset重置,防止变成n^2的算法。
judge[q[i]] = 0;
}
void solve(int rt) {
vis[rt] = judge[0] = 1;//置这个点被访问过,防止其子树上的点再次访问这个点。
calc(rt);
for(int i = head[rt]; i; i = nex[i]) {
if(vis[to[i]]) continue;//我们肯定是找一个没有访问的子树上的点去进行下一次分治递归。
sum = sz[to[i]], root = 0;
maxsz[root] = INF;
get_root(to[i], 0);
solve(root);
}
}
void add(int x, int y, int w) {
to[cnt] = y;
nex[cnt] = head[x];
value[cnt] = w;
head[x] = cnt++;
}
int main() {
// freopen("in.txt", "r", stdin);
n = read(), m = read();
int x, y, w;
for(int i = 1; i < n; i++) {//双向建边。
x = read(), y = read(), w = read();
add(x, y, w);
add(y, x, w);
}
for(int i = 1; i <= m; i++)
query[i] = read();
root = 0;//寻找初始的递归根节点。
maxsz[root] = INF;
get_root(1, 0);
solve(root);
for(int i = 1; i <= m; i++)
puts(is_true[i] ? "AYE" : "NAY");
return 0;
}