一、全文检索与ES
(一)全文检索
数据可以分为结构化数据和非结构化数据,比如说我们常用的sql语句就都是操作结构化数据,邮件等信息都是非结构化数据;
对于结构化数据的查询可以使用sql语句进行查询,速度较快;
对于非结构化数据的查询可以把非结构化数据变成结构化数据:先根据空格进行字符串拆分,得到一个基础的单词列表。需要去掉标点符号、转换大小写、去除停用词、重复的单词只记录一次,就得到了一个最终的单词列表。然后基于单词列表创建一个索引。查询时直接查询索引,找到关键词后根据关键词和文档的对应关系,找到文档列表。这个过程就是全文检索的过程。
全文检索的场景有:搜索引擎、站内搜索、系统文件搜索
全文检索技术有:
Lucene:使用该技术需要对Lucene的API和底层架构非常了解,而且需要编写大量的JAVA代码
Solr:使用JAVA实现一个web应用,可以使用rest方式的http请求,进程远程API调用
ElasticSearch(ES):可以使用rest方式的http请求,进行远程API调用
全文检索可以分为两大步骤:创建索引和搜索索引

1、创建索引:
1)获得原始文档
原始文档就是待搜索的文档。
搜索引擎:原始文档就是整个互联网的网页
电商搜索:数据库中的商品数据
站内搜索:微博搜索,微博的数据。
如何获得原始文档:
搜索引擎:使用爬虫程序
电商搜索:使用jdbc查询数据库
站内搜索:数据库中的数据
2)需要对应每个原始文档创建一个Document对象
Document对象是对原始文档的封装,需要使用Field对象保存原始文档的属性。例如:描述一个文件,需要有文件名称、文件的内容、文件的路径、文件的大小……
Field:叫做字段或者域。field由两部分组成:名称和内容
一个Document中可以有多个Field,不同的Document中可以有不同的Field。
3)分析文档
field中包含文件的相关属性,其中有些field是需要分词的。
对需要分词的field的内容进行分词处理:
1)字符串拆分
2)去除标点符号
3)转换大小写
4)去除停用词
最终得到一个单词列表。单词列表中每个单词需要封装成一个Term对象。
term中包含两部分内容:term所在的field的名称关键词本身
基于Term创建索引。
注意:不是所有的field都需要分词
4)创建索引
基于上一步得到的单词列表创建索引,然后把索引和文档以及关键词和文档的对应关系保存到磁盘。
索引库中包含的内容:索引、文档和索引与文档的对应关系
2、搜索索引:
1)用户交互接口:接收到用户输入的查询内容。
2)把查询内容封装:封装成一个Query对象,其中包含要查询的内容以及要查询的field。
3)根据关键词到索引上查询:迅速的定位到一个关键词,根据关键词和文档对应关系找到文档列表。
4)根据文档的id列表取文档对象:得到一个文档列表,把文档列表展示给用户。
索引库结构:索引库分为索引域和文档域,索引域里面存储的是term字典和文档的倒排索引,文档域存储的就是document。

(二)ElasticSearch
ElasticSearch是一款开源的高扩展分布式全文检索引擎。其是使用JAVA开发并使用Lucene作为核心来实现所有索引和搜索功能的。
ES与Lucene对比:ES通过简单的Restful API来隐藏Lucene的复杂性,从而让全文检索变得简单。
ES与Solr对比:Solr是通过ZK进行分布式管理的,而ES自身带的有分布式协调管理功能;Solr支持更多格式的数据,ES只支持Json格式的数据;Solr在传统搜索应用中表现好于ES,但是在处理实时搜索应用时效率明显低于ES,因为Solr创建索引时,会产生IO阻塞。
二、ES概念与架构
(一)概念
ES不仅仅是存储,还会索引整个文档的内容让其可以进行搜索,在ES中,可以对文档进行索引、搜索、排序、过滤等操作。
ES的概念有索引index、类型type、文档document、字段field和映射mapping
1、索引index
索引可以看作是MySQL中的数据库,一套数据可以使用一套索引。
一个索引由一个名字来标识,名字必须全部是小写字母,当我们对这个索引中文档进行索引、搜索、更新和删除的时候,都需要使用这个名字。
2、类型type
类型类似与MySQL中的表,在一个索引中可以创建多个type。这个在es7及以后已经被废弃,只有_doc。
3、文档document
文档类似MySQL中的一条数据,存储的是具体的数据,存储格式为Json
4、字段field
相当于MySQL中的字段。
5、映射mapping
mapping对处理数据方式和规则做的一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等
(二)架构

ES的架构总体如上图所示,从下到上分为网关、搜索引擎、四大组件、自动发现、通信和Restful API
1、Gateway网关
其作用是用来对数据进行持久化以及ES重启后重新恢复数据。
es支持多种类型的gateway,有本地文件系统、分布式文件系统、Hadoop的HDFS等。
其存储的信息包括索引信息、集群信息、mapping等
2、districted lucene directory搜索引擎
Gateway上层就是Lucene的分布式检索框架。
ES是分布式的搜索引擎,虽然底层用的是Lucene,但是需要在每个节点上都运行Lucene进行相应的索引、查询、更新等操作,所以需要做成一个分布式的运行框架来满足业务需要。
3、四大组件模块
districted lucene directory之上就是ES的四大模块。
Index Model:索引模块,对数据建立索引(通常是建立倒排索引)
Seacher Model:搜索模块,就是对数据进行查询搜索
Mapping Model:是数据映射与解析模块,数据的每个字段可以根据建立的表结构通过mapping进行映射解析;如果没有建立表结构,那么ES会根据数据类型来推测数据结构,并自动生成一个mapping,然后根据mapping进行解析
River Model:在es2.0之后被取消了,表示可以使用插件处理。例如可以通过一些自定义脚本将传统数据库的数据实时同步到es中。
4、自动发现Discovery Script
es集群中各个节点通过discovery相互发现的,默认使用的是Zen。es是一个基于p2p的系统,他先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
es还可以支持多种script脚本语言,例如mvel、js、python等。
5、通信(Transport)
代表es内部节点或集群与客户的交互方式,默认内部使用tcp协议进行交互,同时其还支持http协议,thrift、servlet、memcached、zeroMQ等通信协议。
节点间通信端口默认9300-9400
6、Restful接口
最上层就是ES暴漏给我们的访问接口。
三、Restful访问ES
使用Restful访问ES的方式:curl X<VERB> <PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>d <BOD
其中VERB是请求方式(post、get....),PROTOCOL是协议(http、https......),HOST和PORT是es的ip和端口,PATH是API的终端路径,QUERY_STRING表示任何可选的查询字符串参数(例如@pertty将格式化的输出JSON格式),BODY是一个Json格式的请求体。
1、创建索引和mapping映射(PUT ip:9200/test)
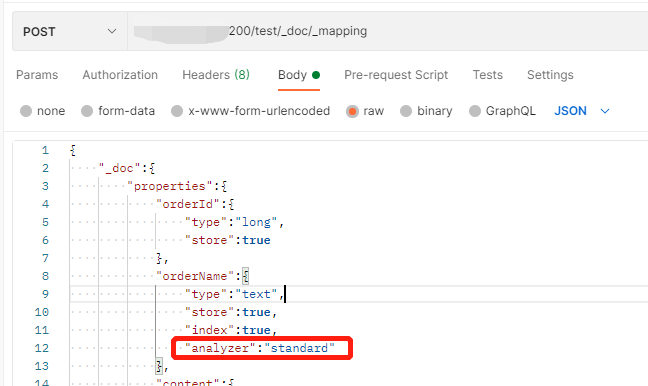
{ "settings":{ "index":{ "number_of_shards":"5", "number_of_replicas":"1" } }, "mappings":{ "_doc":{ "properties":{ "orderId":{ "type":"long", "store":true, "index":true }, "orderName":{ "type":"text", "store":true, "index":true, "analyzer":"standard" }, "content":{ "type":"text", "store":true, "index":true, "analyzer":"standard" } } } } }
也可以先设置索引,然后再设置mapping,设置mapping的路径:post ip:9200/test/_doc/_mapping,参数与上面设置mapping的参数一样
{ "_doc":{ "properties":{ "orderId":{ "type":"long", "store":true }, "orderName":{ "type":"text", "store":true, "index":true, "analyzer":"standard" }, "content":{ "type":"text", "store":true, "index":true, "analyzer":"standard" } } } }
这里需要特殊说明一下,如果是es5及以前的版本,type可以随意定义,如果是es6,一个索引库中只能有一个type,如果是es7,一个索引库只能有一个type,且必须为“_doc”,其实Lucene是没有type这个概念的。
对field属性:
type:数据类型,如果是text,就一定会分词,如果是keyword,就不会分词
store:是否存储原始数据,取决于是否要展示给用户看,但是不影响分词和索引
index:是否要把当前field的内容添加到索引中,如果分词,就一定要索引,不分词也可以索引(例如身份证号或订单号)
analyzer:具体的分词器,如果不写,则使用默认分词器
2、删除索引
直接使用:delete ip:9200/test
3、document处理
对于文档的操作,都是:ip:9200/test/_doc/123(其中test为index,_doc为type,123为document的id),post请求表示增改操作,delete请求表示删除操作,get请求表示查询操作。其中只有post请求需要传递参数,也就是设置document的参数。
{"orderId":123,"orderName":"123的测试订单号","content":"修改随便写一个进行测试"}
四、查询表达式(Query DSL)
1、查询全部
请求地址:post ip:9200/_search 查询可以添加索引或type进行查询:ip:9200/test/_doc/123
请求参数:{"query":{"match_all":{}}}
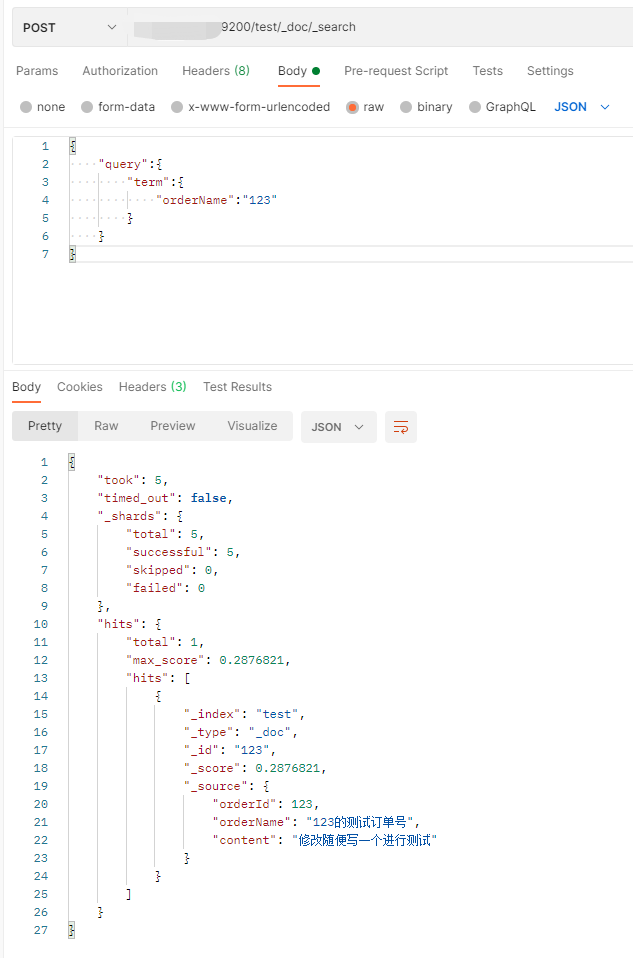
2、term查询
请求地址:post ip:9200/test/_doc/_search
请求参数:{"query":{"term":{"orderName":"123"}}}

3、queryString查询
请求地址:post ip:9200/test/article/_search
请求参数:{"query":{"query_string":{"default_field":"orderName","query":"123"}}}
4、multi_match查询
请求地址与上面一样,参数可以设置多个field进行查询:{"query":{"multi_match":{"query":"123","fields":["orderId", "orderName"]}}}
5、bool查询
布尔过滤器,其是一个符合过滤器,可以结果多个其他过滤器作为参数,并将这些过滤器组合成各式各样的布尔组合。
{ "bool":{ "must":[], "should":[], "must_not":[], "filter":[] } }
如上所示,一个布尔查询由must、should、must_not、filter四部分组成。
must:必须为真,才会被匹配到
should:查询列表中,只要有一个为真,就会被匹配到
must_not:所有必须都不为真,才会被匹配到
filter:对数据进行过滤,filter可以是多个
以下是示例:
{ "query":{ "bool":{ "must":{ "query_string":{ "query":"李四", "default_field":"name" } }, "should":{ "term":{ "address":"上海" } }, "filter":{ "query_string":{ "query":"男", "default_field":"sex" } } } } }
五、IK分词器和ElasticScher集成使用
(一)使用标准分词器存在的问题
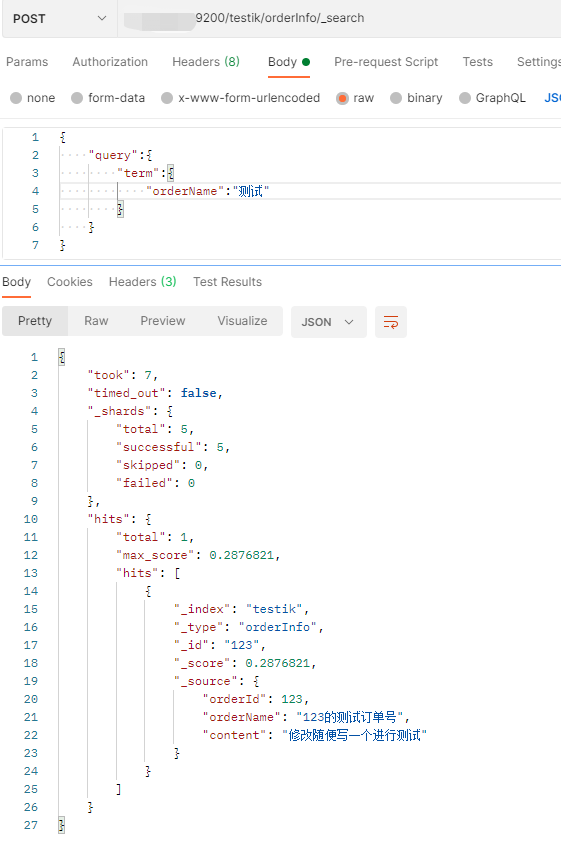
在查询数据时,在orderName中使用123就可以查询成功,但是使用”测试“去查询,就查询不到数据。这是因为在创建索引的时候,使用了标准分词器导致。
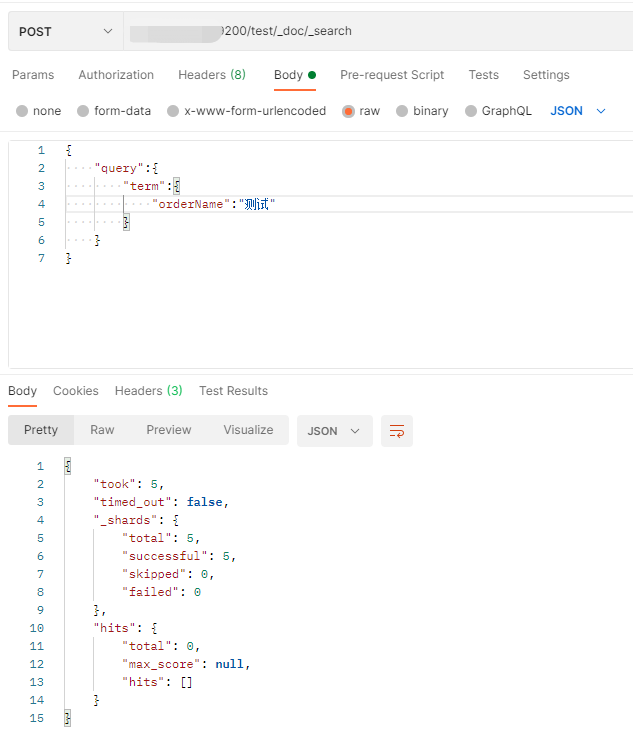
可以使用:post ip:9200/_analyze查看分词结果,如下图所示,可以看到,中文都被分成了一个一个汉字。

(二)使用IK分词器
安装IK分词器,安装地址:https://github.com/medcl/elasticsearch-analysis-ik/releases,这里需要注意一样,ES的版本要和IK分词器的版本对应,如果不对应,ES启动不起来。
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
版本不一致启动出现的异常信息

访问IK分词器查看分词效果:post ip:9200/_analyze,里面只需要传入analyzer和text,其中text为测试分词的文本,analyzer在IK分词器中有ik_smart和ik_max_word两种,分别是最少切分和最细力度切分。

然后使用IK分词器创建索引:"analyzer":"ik_max_word",然后用中文词组搜索,就可以搜索到了。