何鹏是即刻搜索研发部系统平台组的工程师,即刻搜索是人民网其下的搜索引擎,由人民搜索转变而来,于今年6月20日正式上线。据何鹏介绍,即刻搜索 目前存放了200亿个文件以上,其整个系统架构采用Hadoop海量数据分析平台,并针对特定环境对应用程序做了修改。在本次演讲中,何鹏工程师将为我们 分析基于Hadoop的海量网页分析案例。

▲即刻搜索研发部系统平台组工程师何鹏
即刻搜索整体架构借助了Hadoop整个海量分析平台,并针对特定环境增删修改了部分中间件,改良了部分应用程序,以提高性能,下图所展示的是即刻搜索的整体框架图:
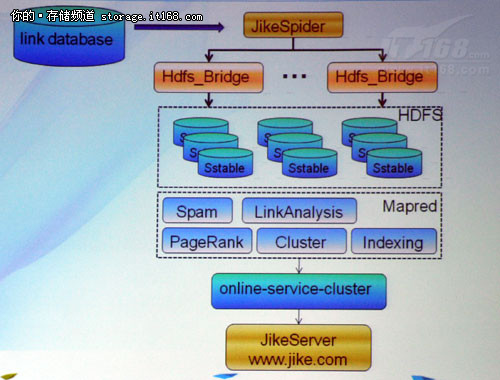
▲即刻搜索整体架构图
在上图中,HDFS即为Hadoop海量数据处理平台,其中Hdfs_Bridge为新添加的中间件,并且,JikeSpider为即刻搜索工程师新开发的应用,并对部分程序进行了改良。
Hdfs_Bridge为即刻搜索海量数据处理平台的中间件,主要是满足爬虫的快速写,并对文件提供自动Flush sstable功能。其通过将写转化为内存写,用DFS直接Flush。以此替代HDFS的多次不必要的序列化和反序列化。
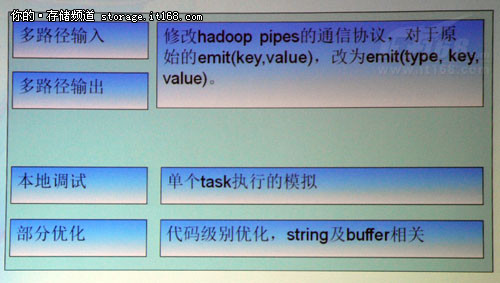
▲
并且,即刻还对Hadoop Pipes进行了改良。通过修改Hadoop pipse的通信写u,将单一的路劲输入输出改为多路径输入输出。还进行本地化调试,并对部分代码进行了优化。
据何鹏工程师介绍,目前即刻搜索的海量数据处理平台还存在一些不足,正在不断优化。比如在部分大型作业时,多个task分配到同一台及其,导致该机器负载过大,从而拖慢整个作业进度,甚至在极端状况下,出现内存过慢的情况。何鹏认为,其主要原因在于任务调度分配不合理,其技术团队正在开发一个中间件,以对集群内的机器任务进行合理分配。
何鹏介绍说,其初步设想是通过tasktracker对CPU、内存、硬盘以及网络等信息进行搜集,并汇报给jobtracker。调度器接受到这些信息之后,在调度任务时将CPU、内存、硬盘以及网络等信息纳入考虑之中,在进行合理的任务分配。
并且,由于数据中心的能耗较大,何鹏希望能够通过技术手段来降低数据中心的能耗。例如集群能源进行管理,当CPU、I/O以及磁盘长时间处于idle时,即可整机进入省电模式;甚至还可对idle较长的模块进行关闭操作。