一、K-均值聚类
K-均值聚类的目的是将各个样本点映射到距离某个质心最近的聚类中。假设样本点为$ extbf{x}^{t},t=1,2,3,...,n$,第$i$个聚类的质心为$ extbf{m}_{i},i=1,2,...,k$。则,$ extbf{x}^{t}$属于聚类$i$可以表示为:
$|| extbf{x}^{t}- extbf{m}_{i}||==min_{j}|| extbf{x}^{t}- extbf{m}_{j}||$
其中,将$ extbf{x}^{t}$划分为聚类$i$的误差表示为:$|| extbf{x}^{t}- extbf{m}_{i}||^{2}$。全体样本的总误差表示为:
$E=sum_{t}sum_{i}b_{i}^{t}|| extbf{x}^{t}- extbf{m}_{i}||^{2}$
其中,如果$|| extbf{x}^{t}- extbf{m}_{i}||==min_{j}|| extbf{x}^{t}- extbf{m}_{j}||$,$b_{i}^{t}=1$,否则,$b_{i}^{t}=0$。
选择的质心必须能够最小化总误差。但是由于$b_{i}^{t}$的取值依赖于$ extbf{m}_{i}$,反过来$ extbf{m}_{i}$又依赖与$ extbf{m}_{i}$,这样使得最小化问题无法直接求解。对此,Kmeans的解法是首先确定$ extbf{m}_{i}$的值,然后依据$ extbf{m}_{i}$的值去确定每个样本点的$ extbf{m}_{i}$,有了$ extbf{m}_{i}$,在总误差的公式中$ extbf{m}_{i}$为已知项,只存在一个未知量,因此最小化问题得以求解。总误差通过对$ extbf{m}_{i}$求导并令其等于0,得到
$ extbf{m}_{i}=frac{sum_{t}b_{i}^{t} extbf{x}^{t}}{sum_{t}b_{i}^{t}}$
这样$ extbf{m}_{i}$得以更新。这是一个迭代的过程,一旦我们计算出心的$ extbf{m}_{i}$,$ extbf{m}_{i}$就会发生改变并需要重新计算,这反过来又会影响$ extbf{m}_{i}$,这样反反复复的重复,知道$ extbf{m}_{i}$不再发生改变。
Kmeans的伪代码:
初始化$ extbf{m}_{i},i=1,2,3...,k$。
Repeat
For 所有的$ extbf{x}^{t} in X$
如果$|| extbf{x}^{t}- extbf{m}_{i}||==min_{j}|| extbf{x}^{t}- extbf{m}_{j}||$,$b_{i}^{t}=1$,否则,$b_{i}^{t}=0$
For 所有的$ extbf{m}_{i},i=1,2,...,k$
$ extbf{m}_{i}=frac{sum_{t}b_{i}^{t} extbf{x}^{t}}{sum_{t}b_{i}^{t}}$
Unitill $ extbf{m}_{i}$收敛
Kmeans的缺点是,它是一个局部搜索的过程,并且最终的$ extbf{m}_{i}$高度依赖于出事的$ extbf{m}_{i}$的选择。因此初始化相当重要,常见的初始化方法包括:
- 简单的随机选择$k$个实例作为出事的$ extbf{m}_{i}$;
- 计算所有数据的均值,并将一些小的随机向量加到均值上,得到$k$个初始的$ extbf{m}_{i}$;
- 计算主成分,将它的值域划分为$k$个相等的去见,将数据划分为$k$个分组,然后取每个分组的质心作为初始的质心。


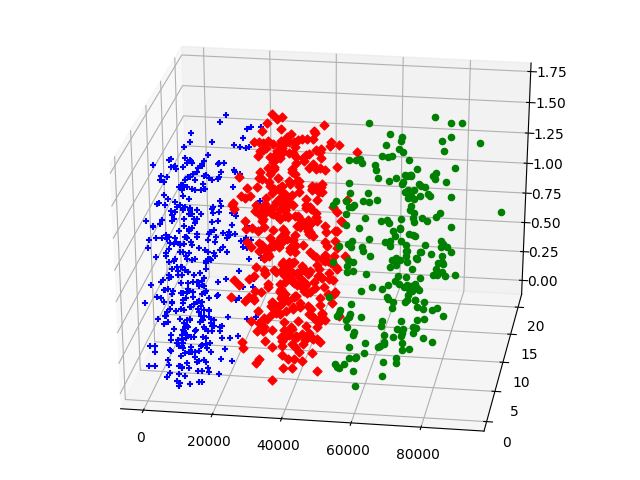
1 # -*- coding=utf-8 -*- 2 """ 3 kmeans: 4 1. 加载数据 5 2. 计算欧式距离 6 3. 随机生成k个中心 7 """ 8 from mpl_toolkits.mplot3d import Axes3D 9 import matplotlib.pyplot as plt 10 from numpy import * 11 #加载文件数据,将标签转换为数值类型 12 def loadDataSet(filename): 13 dataMat = [] 14 fr = open(filename, 'r') 15 #依次读取数据,将每行数据分别加入到list中 16 for line in fr: 17 curLine = line.strip().split(' ') 18 #fltLine = map(float, curLine) 19 dataMat.append(curLine) 20 dataMat = mat(dataMat) 21 #标签类型是string,需要转换为123这样的 22 labels = dataMat[:,shape(dataMat)[1] - 1] 23 #set集合,得到所有种类的标签 24 labelsVec = [] 25 for i in range(shape(labels)[0]): 26 labelsVec.append(labels[i,0]) 27 labelsSet = set(labelsVec) 28 #print labelsSet 29 labelFlag = 0 30 #对相同的标签赋予相同的值 31 for item in labelsSet: 32 index = nonzero(dataMat[:,shape(dataMat)[1] - 1].A == item)[0] 33 # print index 34 dataMat[index,shape(dataMat)[1] - 1] = labelFlag 35 labelFlag += 1 36 #print dataMat 37 fr.close() 38 dataMat = dataMat.tolist() 39 resMat = [] 40 #将string类型数据转化为数值类型 41 for i in range(shape(dataMat)[0]): 42 item = dataMat[i] 43 tmp = map(float, item) 44 resMat.append(tmp) 45 resMat = mat(resMat) 46 return resMat 47 #计算欧式距离 48 def distEclud(vecA, vecB): 49 return sqrt(sum(power(vecA - vecB, 2))) 50 #随即选择中心 51 def randCent(dataSet, k): 52 col = shape(dataSet)[1] 53 centrals = mat(zeros((k, col))) 54 for j in range(col): 55 #取最大最小值,注意max与min返回的是matrix,需要转化为单个数值 56 minJ = min(dataSet[:, j])[0, 0] 57 maxJ = max(dataSet[:, j])[0, 0] 58 rangeJ = maxJ - minJ 59 centrals[:, j] = minJ + rangeJ * random.rand(k, 1) 60 return centrals 61 #kmeans算法 62 def kMeans(dataSet, k, distMeans = distEclud, createCent = randCent): 63 #m表示数据集的size,行数 64 m = shape(dataSet)[0] 65 clusterAssment = mat(zeros((m, 2))) 66 #随机生成k个中心 67 centrals = createCent(dataSet, k) 68 #聚集不再发生改变时停止循环 69 clusterChanged = True 70 while clusterChanged: 71 clusterChanged = False 72 #依次测量每个数据点到各个聚集的距离 73 for i in range(m): 74 minDist = inf 75 minIndex = -1 76 #依次处理k个聚集的中心 77 for j in range(k): 78 distJI = distMeans(centrals[j,:], dataSet[i,:]) 79 #比较相对每个中心的距离,取最小距离对应的聚集 80 if distJI < minDist: 81 minDist = distJI 82 minIndex = j 83 #判断第i个样本点的最小距离是否发生变化 84 if clusterAssment[i,0] != minIndex: 85 clusterChanged = True 86 #将每个样本点按距离分配到不同的聚集中 87 clusterAssment[i,:] = minIndex, minDist**2 88 #print central 89 #更新各个聚集的中心 90 for cent in range(k): 91 ptsInClust = dataSet[nonzero(clusterAssment[:,0] == cent)[0]] 92 centrals[cent,:] = mean(ptsInClust, axis = 0) 93 return centrals, clusterAssment 94 datingSet = loadDataSet("/home/lichao/DataSet/datingtestset.txt") 95 dataSet = datingSet[:, 0:(shape(datingSet)[1] - 1)] 96 labelSet = datingSet[:, shape(datingSet)[1]-1] 97 central, clusterAssment = kMeans(dataSet, 3) 98 print "kmeans算法使用后得到的k个中心的坐标:" 99 print central 100 fig = plt.figure() 101 ax = Axes3D(fig) 102 for i in range(shape(dataSet)[0]): 103 if clusterAssment[i,0] == 0: 104 ax.scatter(dataSet[i,0],dataSet[i,1],dataSet[i,2],c='r', marker='D') 105 elif clusterAssment[i,0] == 1: 106 ax.scatter(dataSet[i,0],dataSet[i,1],dataSet[i,2],c='b', marker='+') 107 else: 108 ax.scatter(dataSet[i,0],dataSet[i,1],dataSet[i,2],c='G', marker='o') 109 plt.show()
运行结果: