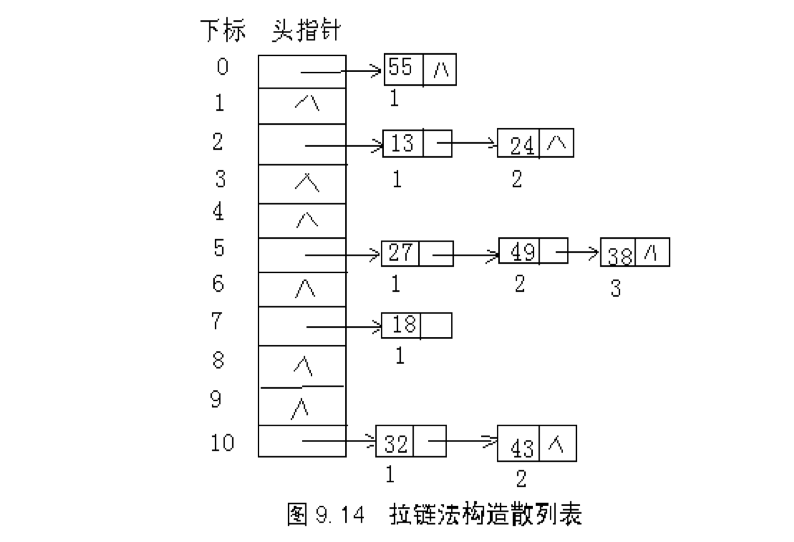
利用分离连接法解决冲突需要用到链表数据结构,同一个链表中保存的数据是关键字经过hash后映射到相同hash表位置的数据,当在hash表中查找数据时,首先对关键字进行hash找到链表在hash表中的位置,然后在链表中查找数据。插入删除操作遵循相同的步骤,首先找到要操作的数据,然后在链表上进行处理。这里的hash表可以理解成链表数组,数组大小就是hash表的大小,数组索引就是Hash表的索引。使用分离连接法的Hash表逻辑结构如下:
使用分离连接法的Hash表定义如下:
#ifndef _HashSeq__H
struct ListNode;
typedef struct ListNode *Position;
struct HashTbl;
typedef struct HashTbl *HashTable;
HashTable InitializeTable(int TableSize);
Void DestoryTable(HashTable H);
Position Find(ElementType Key,HashTable H);
Void Insert(ElementTType Key,HashTable H);
ElementType Retrieve(Position P);
#endif
struct Listnode
{
ElementType Element;
Position Next;
}
typedef Position List;
struct HashTbl
{
int TableSize;
List* TheLists;
}
TheLists是一个指向指向ListNode结构的指针的指针,使用typedef定义List可以使结构看起来更明晰。
下面描述怎么构造一个Hash表,构造hash表首先需要构建一个数组,这个数组对应着hash表散列到的数值范围,同时这个数组的数据类型是一个指针,指向保存数据的节点,这个指针维持着一个链表用来保存有相同hash值的数据。实现如下:
HashTable InitializeTable(int TableSize)
{
HashTable H;
Int I;
H=Malloc(sizeof(struct HashTbl));
H->TableSize=NextPrime(TableSize);
H->TheLists=malloc(sizeof(List)*H->TableSize);
For(i=0;i<H->TableSize;i++)
{
H->TheLists[i]=malloc(sizeof(struct ListNode));
H->TheLists[i]->Next=NULL;
}
}
在hash表中查找元素的操作比较简单,主要步骤就是先hash关键字在数组中找到相应链表的位置,然后直接在链表中查找数据元素。例程如下:
Position Find(ElementType Key,HashTable H)
{
Position P;
List L;
L=H->TheLists[Hash(key,H->TableSize)];
P=L->Next;
While(P!=NULL&&P->Element!=Key)
{
p =p->Next;
}
return P;
}
插入例程思路上也比较简单,主要就是通过常数时间的hash操作找到关键字在hash表中的位置,然后在链表中查找是否已经存在要保存的数据,已存在则不处理,未存在则放到链表的表头(或者其他位置)。