找到以某个字符串开头的字符串
var myReg=/^(abc)/gim;
如果不加m,那么只找一行,而加了m可以找到每行中以该字符串开头的匹配文本。
如:
abcsfsdfasd7890hklfahskfkaluiop7890-7890782ksdlafkasdnfklsdnf;lsabc
sdfasd
f
asd
f
asd
abcadaabcadfads
不加m只能找到一次,加了能找到两次。
String与正则表达式相关的方法
(1)test()方法
若找到则返回true,否则返回false。
测试如下:
function test1(){ var con=content.innerText; window.alert(con); var reg=/abc/gi; if(reg.test(con)){ window.alert("有abc"); }else{ window.alert("没有abc"); } }
用法是
reg.test(con)
而不是
con.test(reg);
支持正则表达式的String对象的方法。
search()方法
返回第一个匹配到的文本的起始位置。
var str="visit W3School!"; window.alert(str.search(/W3School/));
输出:6.
(2)match()
它使用正则表达式模式对字符串执行搜索,并返回一个包含搜索结果的数组。
function test2(){ var con=content.innerText; var myreg=/abc/gi; res=con.match(myreg); for(var i=0;i<res.length;i++){ window.alert(i+" "+res[0]); } }
(3)replace()
function test3(){ var con=content.innerText; var myReg=/(d){4}/gi; //把四个数,换成 var newCon=con.replace(myReg,"这里原来是四个数"); content.innerText=newCon; }
函数的返回值是替换后的新字符串。
(4)split(regExp)
该方法可以把字符串按照正则表达式来分割。
RegExp对象的属性
1. index 是当前表达式首次匹配内容的开始位置,从0开始计数。其初始值为-1,每次成功匹配时,index属性都会随之改变。
2. lastindex 是当前表达式模式首次匹配内容中最后一个字符的下一个位置,从0开始计数。
index是静态属性,直接用类名调用。
3.input 返回当前所作用的字符串
4.leftContext 是当前表达式模式最后一个匹配字符左边的所有内容。
5.rightContext 是当前表达式模式最后一个匹配字符串右边的所有内容。
function test4(){ var con=content.innerText; var myReg=/(d){4}/gi; while(res=myReg.exec(con)){ window.alert("index="+RegExp.index+" left="+RegExp.leftContext+" right="+RegExp.rightContext); } }

js的RegExp的反向
js引擎在匹配的时候,会把各个子表达式的内容捕获到内存暂存。
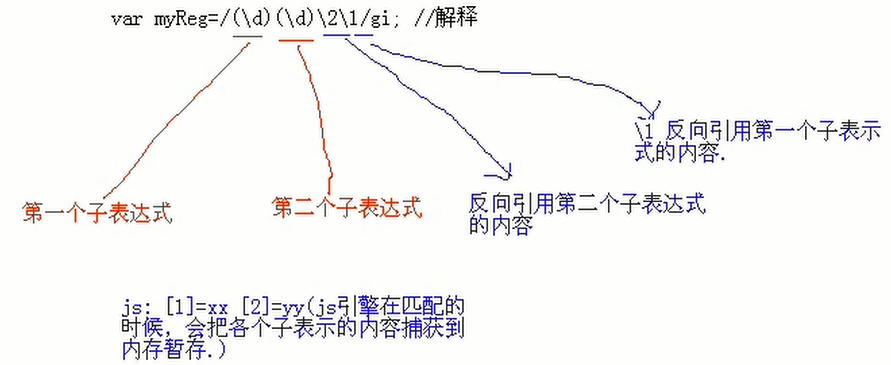
子表达式和捕获,反向引用的概念。
反向捕获主要用来要求重复数字的地方。
function test5(){ var con=content.innerText; var myReg=/(d)(d)21/gi; while(res=myReg.exec(con)){ window.alert(res[0]); } }
请思考:aabbccdd找出这样的数。
var myReg=/(d)1(d)2(d)3(d)4/gi; while(res=myReg.exec(con)){ window.alert(res[0]); }
匹配:五个数字加上一个-然后是如111222333这样的连续重复三次的9个数字
var myReg=/(d){5}-(d)22(d)33(d)44/gi; while(res=myReg.exec(con)){ window.alert(res[0]); }
元字符--限定符
{n,m}说明
n表示至少出现的n次,最多m次,
+说明:
+表示出现1从到任意多次,比如/a+/gi,
?说明:
?表示出现0次到1次,比如/a?/gi,
*说明:
*表示0到任意个。
[0-9]匹配0~9中任意一个数
[a-z]匹配a~z中任意一个字母
[^0-9]匹配不在0-9中的任意一个字符
[^a-z]匹配不在a-z中的任意一个字符
d 表示可以匹配0-9的任意一个数字,相当于[0-9]
D 表示可以匹配到不是0-9中的任意一个字符,相当于[^0-9]
w 匹配任意英文字符、数字和下划线,相当于[0-9a-zA-Z_]
W 相当于[^a-zA-Z0-9],和w刚好相反
s 匹配任何空白字符(空格,制表符等)
S 匹配任何非空白字符,和s刚好相反。
. 匹配出 之外的所有字符,如果要匹配.本身则需要使用.
function test6(){ var con=content.innerText; //var myReg=/1{3}/gi; //var myReg=/1{3,4}/gi; //var myReg=/1+/gi; //var myReg=/a1?/gi; //匹配a1和a; //var myReg=/[a-z]?/gi; //var myReg=/./gi;//匹配. var myReg=/./gi;//匹配除了 的任意字符 while(res=myReg.exec(con)){ window.alert(res[0]); } }
案例:匹配任意三个连续的字符
w是匹配英文字符、数字和下划线,并不包括所有字符(不包括不可见字符)。
所以/(w){3}/gi这样写,私以为不妥。
应该这样写:/[dD]{3}/gi。这样写才能包括不可见字符。但是韩老师是这样写
/([dD])1{2}/gi.
特殊字符匹配,如21,20
元字符-定位符
^ 符号 说明:匹配目标字符串的开始位置。
$ 符号 说明:匹配目标字符串的结束位置。
[^],^在[]中才是非的含义。
^和$匹配字符串开头和结尾,如果后面跟的字符串不是出现在开头或者结尾,则无法匹配到。
//var myReg=/^han/gi; var myReg=/han$/gi; while(res=myReg.exec(con)){ window.alert(res[0]); }
转移字符,要用转义才能找到。
需要用到转义符号的字符有以下:
. * + ( ) $ / ? [ ] ^ { }
元字符-选择匹配符
又是偶,我们在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以匹配那个,这是你需要用到选择匹配符号 |
var myReg=/(han|韩)/gi;
综合案例:验证输入的字符串是不是一个电子邮件
//综合案例:验证输入的字符串是不是一个电子邮件 function test7(){ var con=content.innerText; //var myReg=/[a-zA-Z0-9]+@([a-zA-Z0-9]+.)+(com|cn|net|org)$/; //没有用^,就无法以一系列字符打头 //如果没有^,1430026911@q@qq.com就会被当做邮箱 var myReg=/^[a-zA-Z0-9]+@([a-zA-Z0-9]+.)+(com|cn|net|org)$/; if(myReg.test(con)){ window.alert("是邮件"); }else{ window.alert("不是邮件"); } }