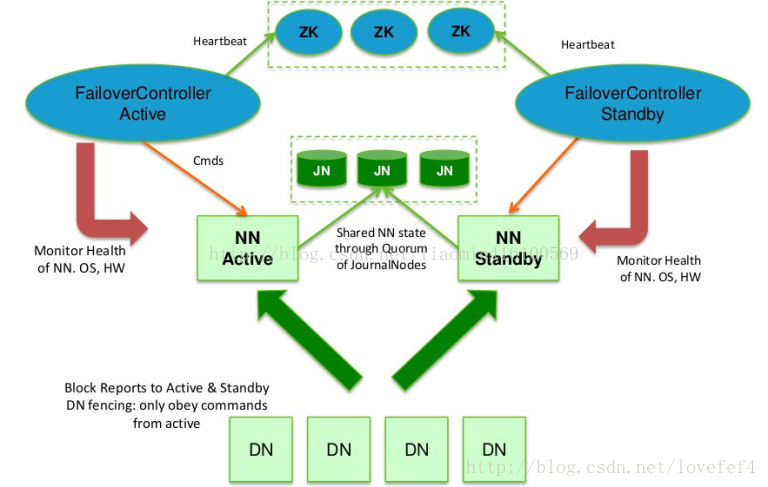
一 。QJM简介和原理
hadoop集群环境 namenode元数据保存在一台机器中 存在单点故障 传统的高可用解决方案 至少有一台从机 用于备份主机数据,同一时间只有主机
对外提供服务,如果主机宕机 从机能够自动接管主机服务,从机为了同步主机的数据 必须定期同步主机的edits日志 但是如果主机宕机 edits日志必定
无法读取 此时产生了新的组件 JournalNodes(同secondarynamenode) 该组件实现了高可用 必须保证3台以上机器 所有主namenode产生的edtis日志
保存在JournalNodes中 初始化时 主namenode和从namenode的元数据 fsimage必须保持一致 从namenode定时从JournalNodes同步日志 更新fsimage
fsimage中没有保存块的位置信息 所以所有的datanode必须同时上报块的数据信息到主和从namenode 为了防止主和从之间因为网络断开产生的
列脑 (双主机问题) JournalNodes 只允许一台namenode写入edits信息,
qjm实现自动切换的原理是:
实现自动切换 引入zookeeper调度和ZKFC切换主从
每个namenode都会持续上报活动信息给zookeeper(产生一个临时节点 不上报就自动过期)当前从namenode的ZKFC程序检测到主的namenode已经
宕机 自动将从namenode激活为 active
二 。QJM配置
1》注意点
qjm要求每个qjm集群必须拥有一个nameserviceid用于区别其他集群 每个namnode都需要一个namenodeid(也叫serviceid)用于区分不同的namenode
JournalNodes 必须三台以上 datanode必须三台以上 JournalNodes是轻量级的 所以可以和datanode主机对应
2》 配置环境
/etc/hosts
192.168.58.147 node1
192.168.58.149 node2
192.168.58.150 node3
192.168.58.151 node4
集群nameserviceid:jiaozi
namenode
node1 namenodeid:cherry
node2 namenodeid:qianqian
JournalNodes
node2
node3
node4
DataNodes
node2
node3
node4hdfs-site.xml
<configuration>
<!--配置node1和node2的fsimage的存储目录 node1和node2上必须先创建该目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/namedata</value>
</property>
<!--配置datanode节点的块数据存储目录 该目录 node2-node4都必须创建-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/blockdata</value>
</property>
<!--配置集群的id nameserviceid-->
<property>
<name>dfs.nameservices</name>
<value>jiaozi</value>
</property>
<!--配置所有的namenode节点的namenodeid-->
<property>
<name>dfs.ha.namenodes.jiaozi</name>
<value>cherry,qianqian</value>
</property>
<!--给nameserviceid下的namenodeid指定是哪台机器 哪个端口 对外提供上传服务
cherry->node1
qianqian->node2
-->
<property>
<name>dfs.namenode.rpc-address.jiaozi.cherry</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.jiaozi.qianqian</name>
<value>node2:8020</value>
</property>
<!--给nameserviceid下的namenodeid指定是http端口 可以使用浏览器打开查看的 -->
<property>
<name>dfs.namenode.http-address.jiaozi.cherry</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.jiaozi.qianqian</name>
<value>node2:50070</value>
</property>
<!--配置journal的所有节点所在的主机 node2-node4 后面的jiaozi是随意的 最好配置为 nameservieid -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node2:8485;node3:8485;node4:8485/jiaozi</value>
</property>
<!--配置自动切换的代理 也就是前面提到的zkfc 如果是手动切换主从 不需要配置这个 后面使用自动 先配上-->
<property>
<name>dfs.client.failover.proxy.provider.jiaozi</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--主机挂掉 登录到主机做的后续操作-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--主机私钥-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--journalnode所在edtis文件保存的目录 node2-node4都需要先创建该目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/journaldata</value>
</property>
</configuration><configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://jiaozi</value> <!--这里的jiaozi就是上面配置的集群id nameserviceid-->
</property>
</configuration>scp -r /soft/hadoop-2.7.4/etc/hadoop/* root@node2:/soft/hadoop-2.7.4/etc/hadoop
scp -r /soft/hadoop-2.7.4/etc/hadoop/* root@node3:/soft/hadoop-2.7.4/etc/hadoop
scp -r /soft/hadoop-2.7.4/etc/hadoop/* root@node4:/soft/hadoop-2.7.4/etc/hadoop3》初始化和启动
初始化namenode 需要先启动 所有的journame
node2-node4执行
hadoop-daemon.sh start journalnode任何一台namenode(选取node1)上执行格式化(确保namenode(/namedata)和journode(journaldata)目录都创建 )
注意(如果之前有了元数据 无需格式化 直接拷贝就行)
hdfs namenode -formatscp -r /namedata root@node2:/启动node1的namenode
hadoop-daemon.sh start namenodenode2上执行拷贝
hdfs namenode -bootstrapStandby 上面步骤完成后 node1上执行
start-dfs.sh 自动开启所有的节点 (已经启动的journode这些不用关 自动连上集群)
访问主从的http地址查看是否可以正常访问http://192.168.58.147:50070/ #node1ip是147 node2的ip是149
http://192.168.58.149:50070/ hdfs haadmin -transitionToActive cherry hadoop-daemon.sh stop namenode此时使用hdfs dfs ls / 发现无法查询 连接异常 (因为没有配置自动 所有无法切换到qianqian的node2节点为active)
强制切换active节点到node2节点
haadmin -transitionToActive --forceactive qianqian 手工切换始终麻烦 必须换成自动
三。自动切换配置
自动切换 添加zookeeper集群 这里就单机zk 懒得装了(window主机 ip是58.1 下载个zookeeper直接bin/zkServer.cmd启动
如果希望安装集群自行百度或者参考http://blog.csdn.net/liaomin416100569/article/details/71642091
)
hdfs-site.xml添加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.58.1:2181</value>
</property>将hdfs-site.xml配置中的
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>值修改为
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>fence就是当active的namenode发生宕机时 standby的namenode需要接管active 之前active的namenode自动调用的方法 该方法必须返回true才能实现切换
默认配置sshfence 如果之前active的namenode网线断了,系统挂了导致的无法连接都会导致 无法返回true 而无法实现切换 如果不需要做任何事情 在之前的active的namenode 就直接返回true 就可以实现自动切换
停止所有服务
stop-dfs.shhdfs zkfc -formatZK重启服务
start-dfs.sh通过http地址访问发现一台active 一台为standby
模拟故障 (干掉active那个namenode)
hadoop-daemon.sh stop namenode http://node1:50070/dfshealth.html#tab-overview
http://node2:50070/dfshealth.html#tab-overview使用 hdfs dfs -ls / 看是否可以正常查看文件系统文件
四。NFS共享目录存储edits文件
创建nfs共享文章请参考(http://blog.csdn.net/liaomin416100569/article/details/76673703)这里不一定是nfs samba或者ftp都行
node4(151机器上添加nfs服务 将/nfsdata目录共享出来用于存储edtis日志)
添加目录
mkdir -p /nfsdata
chown -R nfsnobody:nfsnobody /nfsdatanode1+node2(需要安装nfs)都需要挂载151共享目录
[root@node1 hadoop]# showmount -e 192.168.58.151
Export list for 192.168.58.151:
/nfsdata 192.168.58.0/24
[root@node1 hadoop]# mount -t nfs 192.168.58.151:/nfsdata /mnt
[root@node1 hadoop]# cd /mnt因为使用了共享文件 不再需要journode节点
配置之前停掉之前的journode集群
stop-dfs.sh注释hdfs-site.xml这两配置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node2:8485;node3:8485;node4:8485/jiaozi</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/journaldata</value>
</property><property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///mnt/</value>
</property>复制配置文件到所有的节点 node2-node4
scp -r /soft/hadoop-2.7.4/etc/hadoop/* root@node2:/soft/hadoop-2.7.4/etc/hadoop
scp -r /soft/hadoop-2.7.4/etc/hadoop/* root@node3:/soft/hadoop-2.7.4/etc/hadoop
scp -r /soft/hadoop-2.7.4/etc/hadoop/* root@node4:/soft/hadoop-2.7.4/etc/hadoop格式化node1
hdfs namenode -format启动node1 namenode
hadoop-daemon.sh start namenodenode2同步格式化的fsimage和edtis日志
hdfs namenode -bootstrapStandby[root@node1 mnt]# pwd
/mnt
[root@node1 mnt]# ls
current如果是之前的环境 因为fsimage被格式化了 所有的数据块的目录也需要全部清空否则datanode无法启动 无法上报快的数据
node2-node4执行
rm -rf /blockdata/* start-dfs.sh同journalnode一样测试互相关闭是否切换active
关闭node2的namenode 启动node1的namenode 上传一个文件
关闭node1的namenode 启动node2的namenode 看是否存在上传文件如果存在说明edits确实是共享在了/mft