preface
近来公司利润上升,购买了10几台服务器,趁此机会,把mysql的主从同步的架构进一步扩展,为了适应日益增长的流量。针对mysql架构的扩展,先是咨询前辈,后和同事探讨,准备采用Mysql+heartbeat+drbd+lvs的方案。
Mysql+heartbeat+drbd+lvs是一套成熟的集群解决方案在现在多数企业里面,通过heartbeat+DRBD完成Mysql的主节点写操作的高可用性,通过Mysql+lvs实现Mysql数据库的主从复制和Mysql读写的负载均衡。这个方案在读写方面进行了分离,融合了写操作的高可用和读操作的负载均衡。
有问题请联系本人邮箱18500777133@sina.cn (温柔易淡),博客地址为http://www.cnblogs.com/liaojiafa
mysql 高可用集群概述
很多解决方案能够实现不同的SLA(服务水平协定),这些方案可以保证数据库服务器高可用性。
那么就说说目前比较流行的高可用解决方案如下几种:
- Mysql的主从复制功能是通过建立复制关系的多台或多台机器环境中,一台宕机就切换到另一台服务器上,保证mysql的可用性,可以实现90.000%的SLA。
- mysql的复制功能加一些集群软件可以实现95.000%的SLA。
- Mysql+heartbeat+DRBD的复制功能可以实现99.999%的SLA。
- 共享存储+MYSQL复制功能可以实现99.990%的SLA
- Mysql cluster的标准版和电信版可以达到99.999%的SLA。
在上述方案中,对于Mysql来说,使用共享存储的相对较少,使用方法最多的就是heartbeat+drbd+mysql cluster的方案。
DRBD原理阐述
DRBD官网:http://www.drbd.org/en/doc/users-guide-90
DRBD的英文全称是Distributed Replicated Block Deivce(分布式块设备复制),是linux内核的存储层一个分布式存储系统。可以利用DRBD在两台服务器之间共享块设备,文件系统和数据。类似于一个网络RAID1的功能。
它有三个特点:
- 实时复制:一端修改后马上复制过去。
- 透明的传输: 应用程序不需要感知(或者认识)到这个数据存储在多个主机上。
- 同步或者异步通过:同步镜像,应用程序写完成后会通知所有已连接的主机;异步同步;应用程序会在本地写完之前通知其他的主机。
他有三个协议
- A 写I/O达到本地磁盘和本地的TCP发送发送缓存区后,返回操作成功。
- B 写I/O达到本地磁盘和远程节点的缓存区之后,返回操作成功。
- C 写I/O达到本地磁盘和远程节点的磁盘之后,返回操作成功。
架构图如下所示:
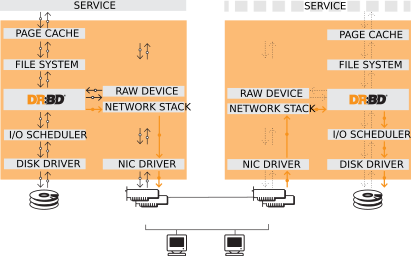
当数据写入到本地主节点的文件系统时,这些数据会通过网络发送到另一台主节点上。本地节点和远程节点数据通过TCP/IP协议保持同步,主节点故障时,远程节点保存着相同的数据,可以接替主节点继续提供数据。两个节点之间通过使用heartbeat来检测对方是否存活。
同步过程如下
左为node1,右为node2
- 在NODE1上写操作被提交,然后通过内核传给DRBD模块。
- DRBD发送写操作到NODE2。
- NODE2上的DRBD发送写操作给本地磁盘
- 在node2上的DRBD向node1发送确认信息,确认已经收到写操作并发给本地磁盘。
- NODE1上的DRBD发送写操作给本地磁盘。
- NODE1上的内核回应写操作完成。
部署Mysql高可用扩展集群
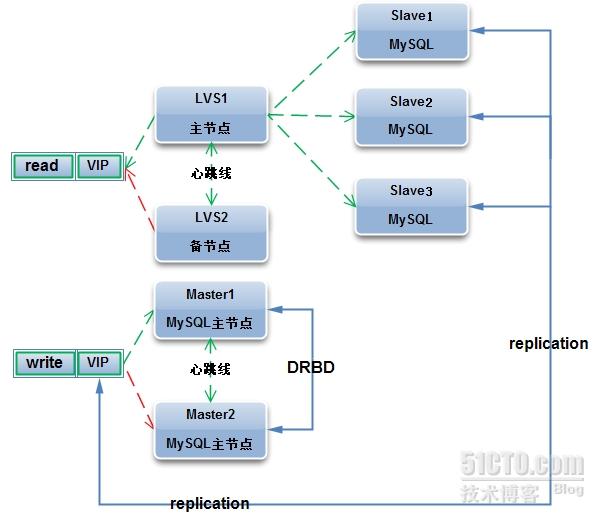
公司Mysql集群具备高可用,可以扩展,易管理,低成本的特点。通常采用Mysql读写分离的方法,而读写之间的数据同步采用Mysql的单向或者双向复制技术实现。Mysql写操作一般采用基于heartbeat+DRBD+MYSQL搭建高可用集群的方案,而读操作普遍采用基于LVS+keepalived搭建高可用扩展集群方案。
下面是我们环境的设备信息
| 主机名 | IP | 角色 |
|---|---|---|
| dbmaster81 | 172.16.22.81 | heartbeat+DRBD+Mysql的主节点 |
| dbbackup136 | 172.16.22.136 | heartbeat+DRBD+Mysql的备节点 |
| dbrepslave142 | 172.16.22.142 | mysql-salve,master_host=172.16.160.251 |
| dbrepslave134 | 172.16.22.134 | mysql-salve,master_host=172.16.160.251 |
| lvsmaster162 | 172.16.22.162 | lvs+keepalived master |
| lvsbackup163 | 172.16.160.163 | lvs+keepalived backup |
- keepalived 所使用的IP为 172.16.22.251
- heartbeat 所使用的IP为172.16.22.250
- lvs 对应的realserver 为 172.16.22.142和172.16.22.134
- 以上都是CentOs6.6的系统
Notice
如果读取的流量非常大,我们还可以考虑在LVS前面加一个Memcached,使其Memcached作为Mysql读数据的一层缓冲层。至于如何让Memcached与Mysql进行联动,请参考我的另一篇博文:http://www.cnblogs.com/liaojiafa/p/6029313.html
架构图如下:
基础工作要到位
1. /etc/hosts
所有服务器的/etc/hosts这个文件必须包含所有主机名和主机IP。如下所示:
[root@dbmaster81 ~]# cat /etc/hosts
127.0.0.1 mfsmaster localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.22.162 lvsmaster162
172.16.22.163 lvsbackup163
172.16.22.142 dbrepslave142
172.16.22.134 dbrepslave134
172.16.22.81 dbmaster81
172.16.22.136 dbbackup136
2. 磁盘分区
数据服务器最好划分一个块单独的分区给数据库文件使用。包含mysql的datadir目录,binlog文件,relay log文件,my.cnf文件,以及ibd文件(单独表空间),ibdata文件和ib_logfile文件。互为主备或者同一集群下面 最好磁盘分区一致。避免磁盘空间大小不同导致出现的问题。
3. 网络环境
咱们使用DRBD进行同步的网络状况是否良好。DRBD同步操作对网络环境要求很好,特别是在写入大量数据的时候,网络越好同步速度和可靠性越高。可以考虑把DB对外服务和DRBD同步网络分开,使他们不会互相干扰。关于心跳线的,两台服务器之间最好为2根,这样不会一根线故障导致VIP的切换。在要求较高的环境下,都要求3根心跳线进程心跳检测,以此减少误切换和脑裂的问题,同时要确认上层交换机是否禁止ARP广播。
开始部署
DRBD的部署
可以采用源码安装或者yum安装,我这边为了更方便就采用yum安装,源码安装比较麻烦了。
首先安装yum源,然后再安装BRBD,yum参考文档:http://www.drbd.org/en/doc/users-guide-84/s-distro-packages
在172.16.22.81上安装drbd
[root@dbmaster81 ~]# yum update kernel-devel kernel # 先升级内核,不然安装不上DRBD,我的内核旧的是(2.6.32-504.el6.x86_64),升级后的是2.6.32-642.11.1.el6.x86_64。
[root@dbmaster81 ~]# reboot # 启动之前先检测当前使用的内核版本,同时确认grub.conf里面默认启动的是新内核
[root@dbmaster81 ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
[root@dbmaster191 ~]# ls /etc/yum.repos.d/ # 下面是yum源
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-fasttrack.repo CentOS-Media.repo CentOS-Vault.repo elrepo.repo
[root@dbmaster81 ~]# yum -y install drbd84-utils kmod-drbd84
[root@dbmaster81 ~]# modprobe drbd # 加载drbd模块
[root@dbmaster81 ~]# lsmod |grep -i drbd
drbd 372759 0
libcrc32c 1246 1 drbd
安装确认无误后,先格式化磁盘给drbd使用,然后来看是配置:
[root@dbmaster81 ~]# fdisk /dev/sdb # 划分一个分区为sdb1,master和backup分区大小一致。
[root@dbmaster81 ~]# cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
#include "drbd.d/global_common.conf"; #注释掉这行,避免和我们自己写的配置产生冲突。
include "drbd.d/*.res";
include "drbd.d/*.cfg";
[root@dbmaster81 ~]# cat /etc/drbd.d/drbd_basic.cfg #主要配置文件
global {
usage-count yes; # 是否参与DRBD使用者统计,默认为yes,yes or no都无所谓
}
common {
syncer { rate 30M; } # 设置主备节点同步的网络速率最大值,默认单位是字节,我们可以设定为兆
}
resource r0 { # r0为资源名,我们在初始化磁盘的时候就可以使用资源名来初始化。
protocol C; #使用 C 协议。
handlers {
pri-on-incon-degr "echo o > /proc/sysrq-trigger ; halt -f ";
pri-lost-after-sb "echo o > /proc/sysrq-trigger ; halt -f ";
local-io-error "echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib4/heartbeat/drbd-peer-outdater -t 5";
pri-lost "echo pri-lst. Have a look at the log file. | mail -s 'Drbd Alert' root";
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
}
net {
cram-hmac-alg "sha1";
shared-secret "MySQL-HA";
# drbd同步时使用的验证方式和密码信息
}
disk {
on-io-error detach;
fencing resource-only;
# 使用DOPD(drbd outdate-peer deamon)功能保证数据不同步的时候不进行切换。
}
startup {
wfc-timeout 120;
degr-wfc-timeout 120;
}
device /dev/drbd0; # 这里/dev/drbd0是用户挂载时的设备名字,由DRBD进程创建
on dbmaster81 { #每个主机名的说明以on开头,后面是hostname(必须在/etc/hosts可解析)
disk /dev/sdb1; # 使用这个磁盘作为drbd的磁盘/dev/drbd0。
address 172.16.22.81:7788; #设置DRBD的监听端口,用于与另一台主机通信
meta-disk internal; # drbd的元数据存放方式
}
on dbbackup136 {
disk /dev/sdb1;
address 172.16.22.136:7788;
meta-disk internal;
}
}
[root@dbmaster81 ~]# drbdadm create-md r0 # 在/dev/sdb1分区上创建DRBD元数据库信息,也称元数据。
WARN:
You are using the 'drbd-peer-outdater' as fence-peer program.
If you use that mechanism the dopd heartbeat plugin program needs
to be able to call drbdsetup and drbdmeta with root privileges.
You need to fix this with these commands:
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /sbin/drbdmeta
chmod o-x /sbin/drbdmeta
chmod u+s /sbin/drbdmeta
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created. # 创建成功
success
#上面提示的命令如下,不必要执行:
useradd haclient
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /sbin/drbdmeta
chmod o-x /sbin/drbdmeta
chmod u+s /sbin/drbdmeta
[root@dbmaster81 ~]# service drbd start
[root@dbmaster81 ~]# drbdadm primary all #把当前服务器设置为primary状态(主节点),如果这一步执行不成功,那么执行这个命令“drbdadm -- --overwrite-data-of-peer primary all”
- 如果可以正常启动,那么就把/etc/drbd.d/drbd_basic.cfg和/etc/drbd.conf复制到backup172.16.22.136上。
- 如果不正常启动,像下面这样的报错,那么就按步骤来:
[root@dbmaster81 ~]# drbdadm primary all
0: State change failed: (-2) Need access to UpToDate data # 报错,无法设置为Primary
Command 'drbdsetup-84 primary 0' terminated with exit code 17
[root@dbmaster81 ~]# drbd-overview
0:r0/0 Connected Secondary/Secondary Inconsistent/Inconsistent
[root@dbmaster81 ~]# drbdadm primary --force r0 # 强制设置为Primary。
[root@dbmaster81 ~]# drbd-overview
0:r0/0 SyncSource Secondary/Secondary UpToDate/Inconsistent
[>....................] sync'ed: 0.1% (511600/511884)M #同步中 ,500G的磁盘,同步需要一会时间,取决于网速(交换机和网卡)
这里我就简要说说136做的操作了,其实两者做的操作也一样。
- 格式化磁盘,使用配置文件指定的/dev/sdb1,两者的容量要大小相同。
- 使用drbdadm create-md r0 创建元数据库在/dev/sdb1。
- 启动服务。service drbd start。
- 查看状态。service drbd status.
在backup服务器上做完上述说的操作后,我们在bakcup服务器查看drbd的状态:
[root@dbbackup136 ~]# service drbd status #dbbackup136上查看
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Primary UpToDate/UpToDate C #进入的主备状态,刚开始启动的时候会进入同步状态,会显示同步进度的百分比
[root@dbmaster81 ~]# service drbd status # drbd master上查看
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C
##进入的主备状态
[root@dbmaster81 ~]# drbdadm dstate r0
UpToDate/UpToDate
[root@dbmaster81 ~]# drbdadm role r0
Primary/Secondary
挂载DRBD的磁盘
我们在dbmaster81(drbd master)上操作:
[root@dbmaster81 ~]# mkfs.ext4 /dev/drbd0
[root@dbmaster81 ~]# mkdir /database
[root@dbmaster81 ~]# mount /dev/drbd0 /database/
[root@dbmaster81 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda2 ext4 28G 2.8G 24G 11% /
tmpfs tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 ext4 283M 57M 212M 22% /boot
/dev/drbd0 ext4 11G 26M 9.6G 1% /database #g挂载成功
主端挂载完后去格式化备端和挂载,主要是检测备端是否能够正常挂载和使用,格式化之前需要主备状态切换,切换的方法请看下面的DRBD设备角色切换的内容。下面就在备端格式化和挂载磁盘。
[root@dbbackup136 ~]# drbdadm primary r0
[root@dbbackup136 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C # 确保是Primary状态才可以格式化挂载使用。主要是
[root@dbbackup136 ~]# mkfs.ext4 /dev/drbd0
备端也可以这样挂载磁盘,但是挂载的前提是备端切换成master端。只有master端可以挂载磁盘。
问题经验总结
这里说说我当初遇到的一个问题:
drbd在一次使用LVM的时候,使用的是500M的逻辑卷,然后在Primary格式化挂载,发现是500M的容量后,就删除500M的逻辑卷通过lvremove命令。于是重新分了500G的逻辑卷,drbd同步元数据后,直接挂载在mysql数据目录下,通过df命令发现还是drbd0的大小还是500M的,找了半天的原因,最后发现,原来在使用新逻辑卷500G的时候,没有mkfs.ext4格式化磁盘就挂载在mysql数据目录下导致的。 解决方法就是重新格式化drbd0磁盘后挂载就可以使用500G的容量了
DRBD设备角色切换
DRBD设备在角色切换之前,需要在主节点执行umount命令卸载磁盘先,然后再把一台主机上的DRBD角色修改为Primary,最后把当前节点的磁盘挂载
第一种方法:
在172.16.22.81上操作(当前是primary)。
[root@dbmaster81 ~]# umount /database/
[root@dbmaster81 ~]# drbdadm secondary r0
[root@dbmaster81 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Secondary UpToDate/UpToDate C #状态已经转变了
在172.16.22.136上操作。
[root@dbbackup136 ~]# drbdadm primary r0
WARN:
You are using the 'drbd-peer-outdater' as fence-peer program.
If you use that mechanism the dopd heartbeat plugin program needs
to be able to call drbdsetup and drbdmeta with root privileges.
You need to fix this with these commands:
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /sbin/drbdmeta
chmod o-x /sbin/drbdmeta
chmod u+s /sbin/drbdmeta
[root@dbbackup136 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C #状态已经转变了
[root@dbbackup136 ~]# mkfs.ext4 /dev/drbd0 # 在没有切换成primary状态的时候,是没法格式化磁盘的。
第二种方法:
在172.16.22.136上操作(当前是primary)。
[root@dbbackup136 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C /database ext4
[root@dbbackup136 ~]# service drbd stop # 先停止服务
Stopping all DRBD resources:
在172.16.22.81上操作
[root@dbmaster81 ~]# drbdadm -- --overwrite-data-of-peer primary all #强行切换为primary
[root@dbmaster81 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 WFConnection Primary/Unknown UpToDate/Outdated C # 切换成功
DRBD的性能优化
1. 网络环境
使用千兆或多张千兆网卡绑定的网络接口,交换机也必须是千兆级别的,且数据同步网络需要和业务网络隔开,避免两者相互干扰。
2. 磁盘性能
给DRBD做磁盘分区的硬盘性能尽量好点,可以考虑转速15K/Min的SAS硬盘或者SSD,或者使用RAID5 或者RAID 0等,在网络环境很好的情况下,DRBD分区可能由于I/O的写性能成为瓶颈。
3. 更新系统
尽量把系统更新成最新的内容,同时使用最新的DRBD,目前kernel2.6.13已经准备把DRBD作为Linux Kernel的主干分支了。
4. syncer的参数
syncer主要用来设置同步相关参数,可以设置“重新”同步(re-synchronization)的速率,当节点间出现不一致的block时,DRBD就需要执行re-synchronization动作,而syncer中的参数rate就是设置同步速率的,rate设置与网络和磁盘IO能力密切相关。
对于这个rate值的设定,官方建议是同步速率和磁盘写入速率中最小者的30%带宽来设置re-synchronization是比较合适。
例如:网络是千兆的(速率为125MB/S),磁盘写入速度(110MB/S),那么rate应该设置为33MB(110*30%=33MB)。这样设置的原因是因为:DRBD同步由两个不同的进程来负责,一个replication进程用来同步block的更新,这个值受限于参数;一个synchronization进程来同步元数据信息,这个值不收参数设置限制。。如果写入量非常大,设置的参数超过了磁盘的写入性能,那么元数据同步就会收到干扰,传输速度变慢,导致机器负载很高,性能下降的很厉害,所这个这个rate值要根据实际环境设置,如果设置过大,就会把所有的带宽占满,导致replication进程没有带宽可用,最终导致I/O停止,出现同步不正常的现象。
5. al-extents 参数设置
al-extents控制着一次向磁盘写入多少个4MB的数据块。增大这个参数的值有以下几个好处:
- 可以减少更新元数据到DRBD设备的频率。
- 降低同步数据时对I/O流中断数量。
- 提高修改DRBD设备的速度。
但是也有一个风险,当主节点宕机以后,所有活动的数据(al-extends的值*4M的数据库)需要在同步连接建立后重新同步,即在主节点出现宕机时,备用节点出现数据不一致的情况。所以不建议在HA部署上调整这个参数。可以在极个别情况下根据需求调整。
更多内容请参考官网地址:http://www.drbd.org/en/doc/users-guide-84/ch-admin#s-check-status