F-strings
在python3.6.2版本中,PEP 498 提出一种新型字符串格式化机制,被称为“字符串插值”或者更常见的一种称呼是F-strings(主要因为这种字符串的第一个字母是f)
简单了解:
①、F-strings提供了一种明确且方便的方式将python表达式嵌入到字符串中来进行格式化:
import math
radius = 10
pi = math.pi
print(f'Circumference of a circle with radius {radius}:{2*pi*radius}')
# Circumference of a circle with radius 10:62.83185307179586
②、同样的,在F-strings中我们也可以执行函数:
import math
radius = 10
def area_of_circle(radius):
return 2 * math.pi * radius
print(f'Area of a circle with radius {radius}:{area_of_circle(radius=radius)}')
# Area of a circle with radius 10:62.83185307179586
③、F-strings的运行速度很快。比%-string和str.format()这两种格式化方法都快得多——这两种是最常用的两种字符串格式化的方式。

实测F-string大多情况下比%-string要快,但偶尔也不一定(无法解释)
 实测对比
实测对比对比剖析:
①、为什么F-strings的运行速度这么快?它们是以怎样的形式运行得呢?PEP 498给出了如下的线索:
使用最小的语法,F-strings提供了一种在字符串中嵌入表达式的方法。需要注意的是,F-strings是运行过程中形成的表达式,而不是常数值。在Python源代码中,F-strings是一个以f为前缀,其中包含了表达式的字符串。表达式的结果将显示在其所在的位置上。
重点是F-strings是运行过程中进行计算的表达式,而不是一个常数值。这意味着F-strings和其他python表达式一样都是在运行过程中计算出结果的。CPython编译器在将F-strings解析成字符串和表达式以生成合适的抽象语法树的阶段使性能得到巨大的提升:
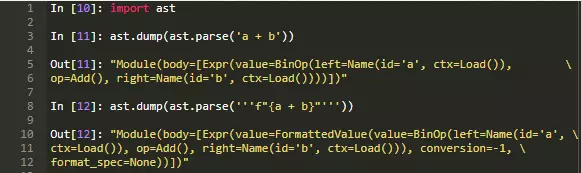
我们使用ast模块来查看一个简单的表达式a + b在F-strings之中和之外两种情况下的抽象语法树的情况。可以看到表达式F-strings中的表达式被解析成一个普通的旧式的二进制操作,和单独的表达式 a + b解析成的结果是一样的。甚至在字节码层面我们也可以看到F-strings表达式也像普通表达式那样进行计算。

add_two函数简单的将两个本地变量a和b进行相加并返回结果值。add_two_fstring函数实现的功能类似,但相加的表达式放到f-strings内。在add_two_fstring函数反汇编出的字节码中,FORMAT_VALUE指令(这个指令出现在这里因为毕竟一个F-strings需要将其内部的表达式字符串化),和不使用F-strings的 a + b表达式的结果是一样的。
F-strings的过程主要分为两步:一是把花括号中的表达式计算出来(和普通的Python表达式一样),然后将其结果填充到花括号的位置,并将组合后的字符串作为结果返回。这些步骤不需要额外的运行过程处理。这使得F-strings运行速度更快也更有效率。
②、为何str.format()会比F-strings慢得多呢?当看过其对应的反汇编字节码之后,原因就很明显了。
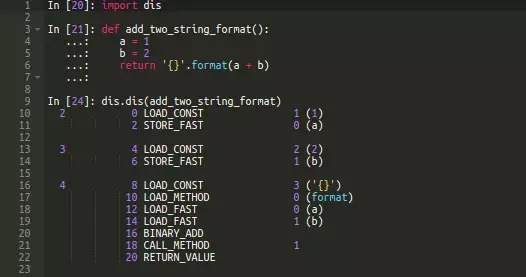
反汇编得到的字节码中,第一眼就能看到两个字节码指令:LOAD_METHOD和 CALL_METHOD。当我们使用上str.format()时,首先要在全局范围内寻找format函数。这个步骤是通过LOAD_METHOD指令实现的。全局变量查找是一个开销比较大的操作,包括了一系列的步骤(如果比较感兴趣的话,可以看看我之前关于属性查找方面的博文)。一旦format函数被定位到,二进制加操作(BINARY_ADD)将会被唤醒对变量a、b进行相加。最后,通过CALL_METHOD字节码指令调用format函数,然后将格式化后的结果返回。Python中的函数调用具有相当大的开销。当使用str.format()时,消耗在LOAD_METHOD和 CALL_METHOD上额外的时间导致str.format()比F-strings慢的多。
③、那么%-strings 这种格式化方法又是什么原因呢?之前的结果可以看到,它的运行速度介于str.format()和F-strings之间。让我们再一次看一下使用%-strings 格式化方法反汇编后的字节码来寻找一些线索:
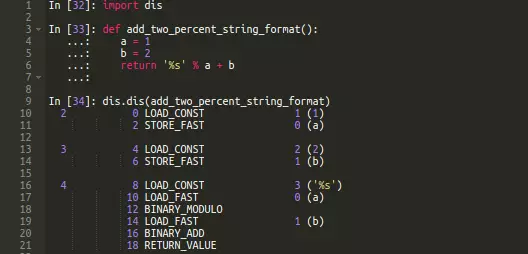
一瞬间,我们就发现字节码中并没有LOAD_METHOD和 CALL_METHOD指令——所以 %-string 这种方法避免了全局属性查找和函数调用的开销。这解释了为什么%-strings 要比str.format()快。但为什么%-strings 的运行速度仍然比f-strings要慢呢?在BINARY_MODULO字节码指令上,%-strings 可能会消耗额外的时间。通过分析BINARY_MODULO字节码我并没得出结果,但看了CPython源代码后,我们就可以了解为什么在调用BINARY_MODULO时会产生很小的额外开销。

上图的Python源代码中可以看出,BINARY_MODULO操作是过载的。每次被调用时,它总需要检查运算对象的类型来决定元算对象是否为字符串对象(代码的第7-13行)。如果它们是,然后modulo 执行字符串格式操作。如果不是,它将执行日常的模块(返回第一个参数和第二个参数的余数)。尽管很小,但这种类型检查确实产生了一些额外开销,而F-strings并不存在这些问题。
希望这篇文章能给大家一些启发,帮助大家理解为什么F-strings能从众多字符串格式化方法中脱颖而出。F-strings快速、易学、实用,能有效减少代码量,何不快快用起来!
英文原文:https://ogmcsrgk5.qnssl.com/vcdn/1/优质文章长图/a-closer-look-at-how-python-f-strings-work-f197736b3bdb.png