一、IO操作的概述
文件操作就是一种IO操作,所以在了解文件系统前首先要了解什么是IO操作。
I/O在计算机中是指Input/Output,也就是Stream(流)的输入和输出。这里的输入和输出是相对于内存来说的,Input Stream(输入流)是指数据从外(磁盘、网络)流进内存,Output Stream是数据从内存流出到外面(磁盘、网络)。程序运行时,数据都是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方(通常是磁盘、网络操作)就需要IO接口。
操作系统屏蔽了底层硬件,向上提供通用接口。因此,操作I/O的能力是由操作系统的提供的,每一种编程语言都会把操作系统提供的低级C接口封装起来供开发者使用,Python也不例外。
二、文件操作
1. 文件操作的接口
python中有一个内置函数open(),我们可以直接通过接收"文件路径"以及“文件打开模式”等参数获取我们的文件对象(这就是我们在程序中要操作的文件对象),并返回该文件对象的文件描述符.这样我们就可以对文件对象进行读写操作了。
2. 文件操作的流程
# 打开文件,获取文件描述符 f = open('a.txt', 'r', encoding='utf8') # 操作文件描述符--读/写 res = f.read() print(res) # 关闭文件 f.close()
那么文件系统在计算机中是怎么实现的呢?
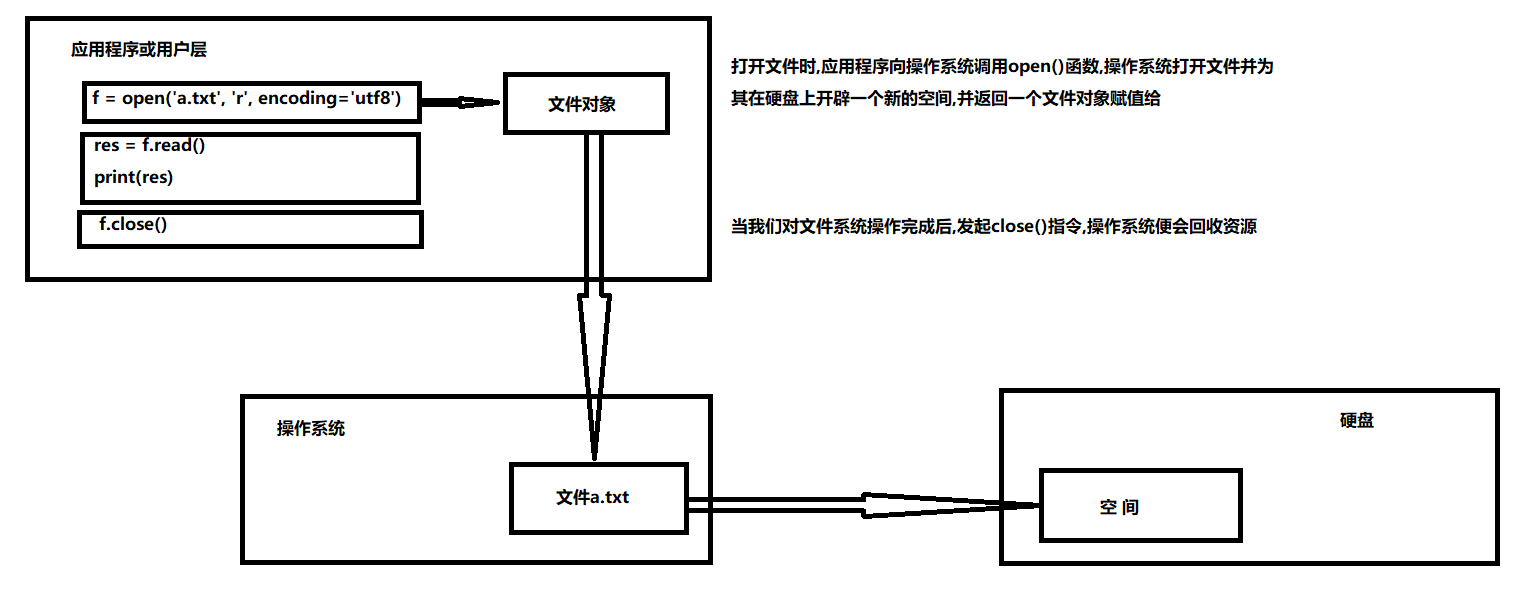
3. 文件的资源回收
文件读写操作完成后,应该及时关闭。一方面,文件对象会占用操作系统的资源;另外一方面,操作系统对同一时间能打开的文件描述符的数量是有限制的,如果不及时关闭文件,还可能会造成数据丢失。因为我将数据写入文件时,操作系统不会立刻把数据写入磁盘,而是先把数据放到内存缓冲区异步写入磁盘。当调用close方法时,操作系统会保证把没有写入磁盘的数据全部写到磁盘上,否则可能会丢失数据。
python还提供了with关键字帮助我们管理上下文,自动关闭文件,这样我们就可以不用手动关闭文件了。
with open('a.txt', 'a',encoding='utg8') as f: res = f.read() print(res)
三、文件的打开模式
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。相当于rt |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。相当于wt |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。相当于at |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
r+、w+和a+的区别 :
- r+会覆盖当前文件指针所在位置的字符,如原来文件内容是"Hello,World",打开文件后写入"hi"则文件内容会变成"hillo, World"
- w+与r+的不同是,w+在打开文件时就会先将文件内容清空,感觉和w没啥区别啊
- a+与r+的不同是,a+只能写到文件末尾(无论当前文件指针在哪里)
四、文件读写与字符编码
`在使用open()方法打来一个文件时,可以指定字符的编码,如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。 这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
详细可以看一下博客https://www.cnblogs.com/yyds/p/6186621.html
五、python文件读取的相关方法
1.文件的操作方法
| 方法 | 描述 |
|---|---|
| read() | 一次读取文件所有内容,返回一个str |
| read(size) | 每次最多读取指定长度的内容,返回一个str;在Python2中size指定的是字节长度,在Python3中size指定的是字符长度 |
| readlines() | 一次读取文件所有内容,按行返回一个list |
| readline() | 每次只读取一行内容 |
1. read()方法 ---- 读取所有内容,光标移动到文件末尾
f = open('a.txt', 'r', encoding='utf8') res = f.read() print(res) print(type(res)) # 返回一个字符串类型 f.close() “”” 匆匆那年我们 究竟说了几遍 再见之后再拖延 可惜谁有没有 爱过不是一场 七情上面的雄辩 <class 'str'> “””
2. read(szie)
- 文件打开方式为文本模式时,代表读取size个字符
- 文件打开方式为b模式时,代表读取size个字节
3. readlines()
with open('a.txt', 'r', encoding='utf8') as f: res = f.readlines() print(res) print(type(res)) “”” ['匆匆那年我们 究竟说了几遍 再见之后再拖延 ', '可惜谁有没有 爱过不是一场 七情上面的雄辩'] <class 'list'> “””
这种方式的缺点与read()方法是一样的,都是会消耗大量的内存空间.前面讲过打开的文件对象也是一个迭代器,所以我们可以通过迭代器对文件进行读取.
with open('a.txt', 'r',encoding='utf8') as f: for line in f: print(line)
4. readline()
with open('a.txt', 'r', encoding='utf8') as f: res = f.readline() print(res) print(type(res)) """ 匆匆那年我们 究竟说了几遍 再见之后再拖延 <class 'str'> """
2. 此外,还要两个个与文件指针位置相关的方法
| 方法 | 描述 |
|---|---|
| seek(n) | 将文件指针移动到指定字节的位置 |
| tell() | 获取当前文件指针所在字节位置 |
注意这两种种方法在文件内光标移动都是以字节为单位
1. seek()
seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
- 0 模式 : 默认模式,表示指针移动的字节数是以文件开头为参照
f = open('a.txt', 'r', encoding='utf8') f.seek(6, 0) print(f.tell()) print(f.read()) f.close() """ 6 那年我们 究竟说了几遍 再见之后再拖延 可惜谁有没有 爱过不是一场 七情上面的雄辩 """
需要注意的是,在t模式下会将读取的文件自动解码,所以我们必须保证读取的内容是一个完整的数据(中文占3个字节,数字字母占一个字节),否则会报错
f = open('a.txt', 'r', encoding='utf8') f.seek(5, 0) print(f.tell()) print(f.read()) f.close() """ UnicodeDecodeError: 'utf-8' codec can't decode byte 0x86 in position 0: invalid start byte """
- 1模式:表示指针移动的字节数是以当前所在位置为参照,必须是以b的形式打开
with open('a.txt', 'rb') as f: f.seek(5, 1) # 当前位置为文件开头 print(f.tell()) f.seek(7, 1) # 当前位置为5 print(f.tell()) print(f.read().decode('utf8')) """ 5 12 我们 究竟说了几遍 再见之后再拖延 可惜谁有没有 爱过不是一场 七情上面的雄辩 """
- 2模式: 表示指针移动的字节数是以文件末尾位置为参照
指针从后面往前面移动的话,步长要为负数
with open('a.txt', 'rb') as f: f.seek(-6, 2) # 文件从末尾向前移动了6个字节 print(f.tell()) print(f.read().decode('utf8')) """ 114 雄辩 """
3. file类的其他方法:
| 方法 | 描述 |
|---|---|
| flush() | 刷新缓冲区数据,将缓冲区中的数据立刻写入文件 |
| next() | 返回文件下一行,这个方法也是file对象实例可以被当做迭代器使用的原因 |
| truncate([size]) | 截取文件中指定字节数的内容,并覆盖保存到文件中,如果不指定size参数则文件将被清空; Python2无返回值,Python3返回新文件的内容字节数 |
| write(str) | 将字符串写入文件,没有返回值 |
| writelines(sequence) | 向文件写入一个字符串或一个字符串列表,如果字符串列表中的元素需要换行要自己加入换行符 |
| fileno() | 返回一个整型的文件描述符,可以用于一些底层IO操作上(如,os模块的read方法) |
| isatty() | 判断文件是否被连接到一个虚拟终端,是则返回True,否则返回False |
六、文件的修改操作
因为文件数据是存储在磁盘或硬盘上的,所以无法被修改,但如果真的想要修改一个文件,可以通过覆盖的形式来实现,这也是我们平时看到的修改文件的方法.
import os with open('a.txt', encoding='utf8') as read_f, open('.a.txt.swap', 'w', encoding='utf8') as write_f: data = read_f.read() # 全部读入内存,如果文件很大,会很卡 data = data.replace('再见', '你好') # 在内存中完成修改 # 可以再优化一下,利用迭代器将文件一行行读入和修改 """ for line in read_f: data = line.replace('再见', '你好') write_f.write(data) """ write_f.write(data) # 一次性写入新文件 os.remove('a.txt') os.rename('.a.txt.swap', 'a.txt') # 将新文件改名为旧文件名,从而达到覆盖