今天开发遇到一个需求,就是把包含父子关系的数据转化为树形结构,这个需求来自我开发的一个功能,前端需要使用 Element 的级联选择器实现行业级联选择的功能。
- 列表数据类型
每条数据都列出了其父 id,如果没有就是最顶层的数据(树结构的话就是第一层)
{'id': 'A', 'pId': '', 'singlehyname': '农、林、牧、渔业', 'name': '农、林、牧、渔业(A)', 'isParent': True, 'parentcode': ''}
{'id': 'A01', 'pId': 'A', 'singlehyname': '农业', 'name': '农业(A01)', 'isParent': True, 'parentcode': 'A'}
{'id': 'A011', 'pId': 'A01', 'singlehyname': '谷物种植', 'name': '谷物种植(A011)', 'isParent': True, 'parentcode': 'A01'}
{'id': 'A0111', 'pId': 'A011', 'singlehyname': '稻谷种植', 'name': '稻谷种植(A0111)', 'isParent': False, 'parentcode': 'A011'}
'isParent': False, 'parentcode': 'A011'}
{'id': 'A012', 'pId': 'A01', 'singlehyname': '豆类、油料和薯类种植', 'name': '豆类、油料和薯类种植(A012)', 'isParent': True, 'parentcode': 'A01'}
{'id': 'A0121', 'pId': 'A012', 'singlehyname': '豆类种植', 'name': '豆类种植(A0121)', 'isParent': False, 'parentcode': 'A012'}
'isParent': False, 'parentcode': 'A012'}
{'id': 'A013', 'pId': 'A01', 'singlehyname': '棉、麻、糖、烟草种植', 'name': '棉、麻、糖、烟草种植(A013)', 'isParent': True, 'parentcode': 'A01'}
{'id': 'A0131', 'pId': 'A013', 'singlehyname': '棉花种植', 'name': '棉花种植(A0131)', 'isParent': False, 'parentcode': 'A013'}
- 要整合成这种数据类型
层级关系不固定,依赖于上面的数据
[
{
children: [
{
children: [
{
value: "海水养殖",
label: "海水养殖(A0411)"
},
],
value: "水产养殖",
label: "水产养殖(A041)"
},
],
value: "渔业",
label: "渔业(A04)"
}
];
- 如何实现
首先遍历列表数据,使用第一层级的数据(就是没有父亲的数据)初始化初始结果,然后再次遍历列表数据,利用递归将有父亲的数据添加到结果中。(具体实现见下面的代码) - 最终前端实现效果
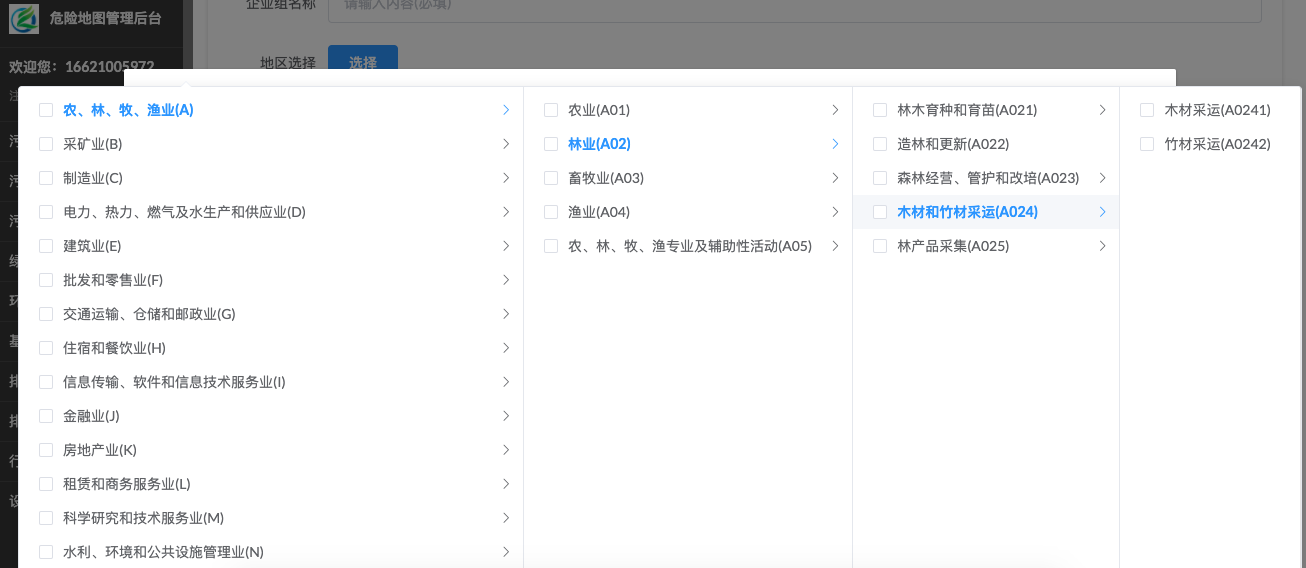
- 代码
import json
import requests
def arrange(result, industry):
p_id = industry['pId']
for temp in result:
if p_id in temp['label']:
if 'children' in temp:
temp['children'].append(dict(value=industry['singlehyname'], label=industry['name']))
else:
temp['children'] = [dict(value=industry['singlehyname'], label=industry['name'])]
continue
if 'children' in temp:
arrange(temp['children'], industry)
def get_permit_industry():
# 获取源数据
headers = {
'Host': 'permit.mee.gov.cn',
'Origin': 'http://permit.mee.gov.cn',
'Referer': 'http://permit.mee.gov.cn/permitExt/common/tree/xzxk-common-trade!selectHylist.action?hyids=&hytype=more',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
url = 'http://permit.mee.gov.cn/permitExt/common/tree/xzxk-common-trade!hynodeslist.action'
res = requests.post(url, headers=headers)
industry_info = json.loads(res.text.replace("/**/
", ''))
result = []
# 初始化结果
for i in industry_info:
if not i['pId']:
result.append(dict(value=i['singlehyname'], label=i['name']))
# 将其他层级的数据添加到结果中(原始数据相对比较规整,如果完全打乱,这样实现会有问题)
for i in industry_info:
if i['pId']:
arrange(result, i)
return result