在整个过程中出现了各种问题,我先将我调试好的真个项目打包,提供下载。
1 /*
2 * Copyright 1993-2010 NVIDIA Corporation. All rights reserved.
3 *
4 * NVIDIA Corporation and its licensors retain all intellectual property and
5 * proprietary rights in and to this software and related documentation.
6 * Any use, reproduction, disclosure, or distribution of this software
7 * and related documentation without an express license agreement from
8 * NVIDIA Corporation is strictly prohibited.
9 *
10 * Please refer to the applicable NVIDIA end user license agreement (EULA)
11 * associated with this source code for terms and conditions that govern
12 * your use of this NVIDIA software.
13 *
14 */
15
16 #include <GLglut.h>
17 #include "cuda.h"
18 #include "cuda_runtime.h"
19 #include "device_launch_parameters.h"
20 #include "../common/book.h"
21 #include "../common/cpu_bitmap.h"
22
23 #define DIM 1000
24
25 struct cuComplex {
26 float r;
27 float i;
28 __device__ cuComplex(float a, float b) : r(a), i(b) {}
29 __device__ float magnitude2(void) {
30 return r * r + i * i;
31 }
32 __device__ cuComplex operator*(const cuComplex& a) {
33 return cuComplex(r*a.r - i*a.i, i*a.r + r*a.i);
34 }
35 __device__ cuComplex operator+(const cuComplex& a) {
36 return cuComplex(r + a.r, i + a.i);
37 }
38 };
39
40 __device__ int julia(int x, int y) {
41 const float scale = 1.5;
42 float jx = scale * (float)(DIM / 2 - x) / (DIM / 2);
43 float jy = scale * (float)(DIM / 2 - y) / (DIM / 2);
44
45 cuComplex c(-0.8, 0.156);
46 cuComplex a(jx, jy);
47
48 int i = 0;
49 for (i = 0; i<200; i++) {
50 a = a * a + c;
51 if (a.magnitude2() > 1000)
52 return 0;
53 }
54
55 return 1;
56 }
57
58 __global__ void kernel(unsigned char *ptr) {
59 // map from blockIdx to pixel position
60 int x = blockIdx.x;
61 int y = blockIdx.y;
62 int offset = x + y * gridDim.x;
63
64 // now calculate the value at that position
65 int juliaValue = julia(x, y);
66 ptr[offset * 4 + 0] = 255 * juliaValue;
67 ptr[offset * 4 + 1] = 0;
68 ptr[offset * 4 + 2] = 0;
69 ptr[offset * 4 + 3] = 255;
70 }
71
72 // globals needed by the update routine
73 struct DataBlock {
74 unsigned char *dev_bitmap;
75 };
76
77 int main(void) {
78 DataBlock data;
79 CPUBitmap bitmap(DIM, DIM, &data);
80 unsigned char *dev_bitmap;
81
82 HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
83 data.dev_bitmap = dev_bitmap;
84
85 dim3 grid(DIM, DIM);
86 kernel << <grid, 1 >> >(dev_bitmap);
87
88 HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap,
89 bitmap.image_size(),
90 cudaMemcpyDeviceToHost));
91
92 HANDLE_ERROR(cudaFree(dev_bitmap));
93
94 bitmap.display_and_exit();
95 }
期间出现的问题:
问题一
calling a host function("cuComplex::cuComplex") from a __device__/__global__ function("julia") is not allowed
calling a host function("cuComplex::cuComplex") from a __device__/__global__ function("julia") is not allowed
calling a host function("cuComplex::cuComplex") from a __device__/__global__ function("cuComplex::operator *") is not allowed
calling a host function("cuComplex::cuComplex") from a __device__/__global__ function("cuComplex::operator +") is not allowed
这个原因是在原著中提供的代码有问题,原著中结构体中的代码为
cuComplex(float a, float b) : r(a), i(b) {}
将其修改如下即可:
__device__ cuComplex(float a, float b) : r(a), i(b) {}
问题二
error LNK2019: 无法解析的外部符号 ___glutInitWithExit@12,该符号在函数 _glutInit_ATEXIT_HACK@8 中被引用 1>GEARS.obj : error LNK2019: 无法解析的外部符号 ___gl
这个原因是我的OpenGL文件没有引对
#include <GLglut.h>
其中glut.h文件要在下面的路径下
C:Program Files (x86)Microsoft Visual Studio 12.0VCincludeGL
如果GL文件夹不在,要手动创建,结构如下图所示:

注意:
为了运行示例代码,需要抽取可运行的部分,同时为了减少手动修改的麻烦,也要注意各各个文件目录的层次关系,我的截图如下:
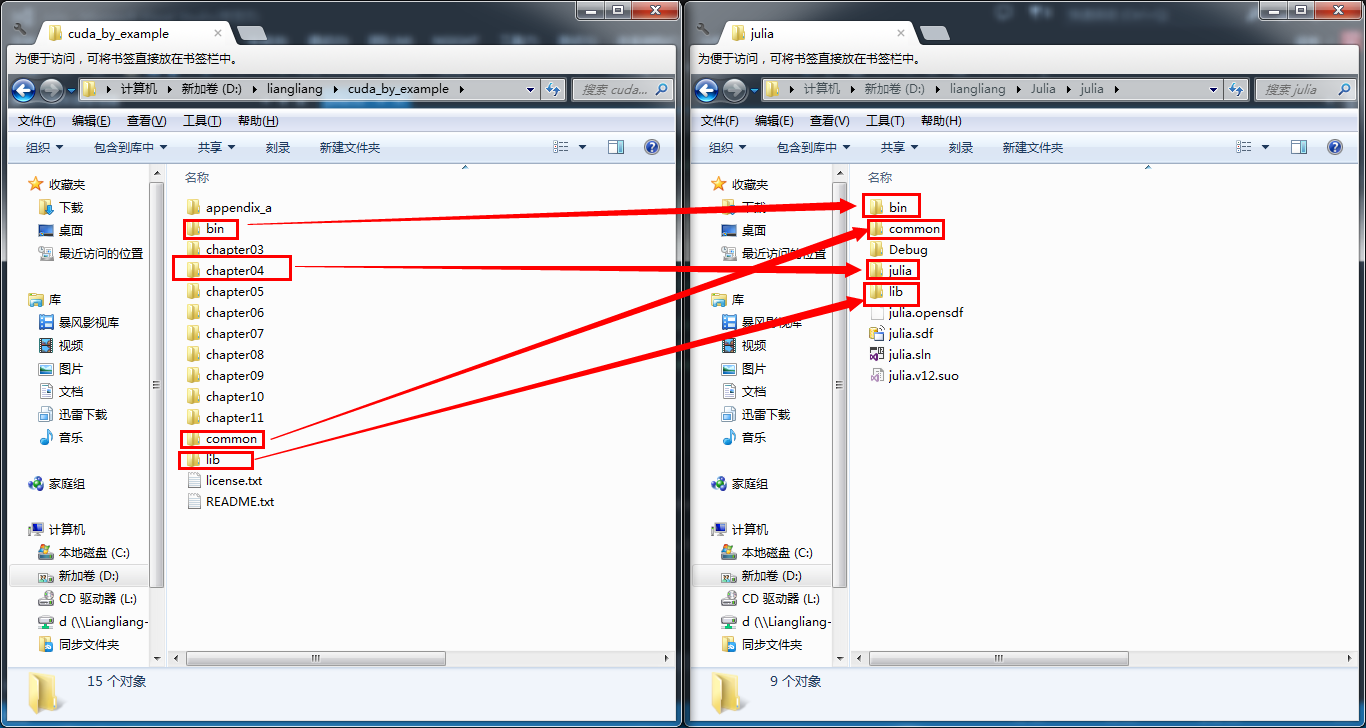
千辛万苦走下来就为了下面这张图:

确实挺好看的。赞一个!