转载请注明出处,谢谢
2017-10-22 17:14:09
之前都是用python开发maprduce程序的,今天试了在windows下通过eclipse java开发,在开发前先搭建开发环境。在此,总结这个过程,希望能够帮助有需要的朋友。
用Hadoop eclipse plugin,可以浏览管理HDFS,自动创建MR程序的模板文件,最爽的就是可以直接Run on hadoop。
1、安装插件
下载hadoop-eclipse-plugin-1.2.1.jar,并把它放到 F:eclipseplugins 目录下。
2、插件配置与使用
2.1指定hadoop的源码目录

2.2、打开Map/Reduce视图
”Window”->”Open Perspective”->”Other”->“Map/Reduce”.
“Window”->”Show views”->”Other”->”Map Reduce Tools”->”Map/Reduce locations”.
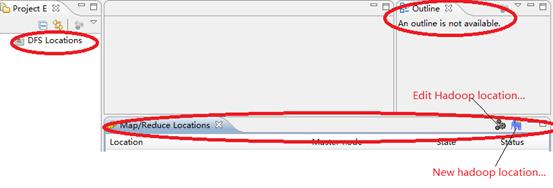
正常情况下回出现左上角的HDFS标志,等eclipse与hadoop集群连接后,会在这显示HDFS目录结构。
2.3、新建Map/Reduce Localtion

点击图中红色框或者鼠标右击选中新建,然后出现下面的界面,配置hadoop集群的信息。

这里需要注意的是hadoop集群信息的填写。因为我是在windows下用eclipse远程连接hadoop集群【完全分布式】开发的,所以这里填写的host是master的IP地址。如果是hadoop伪分布式的可以填写localhost。
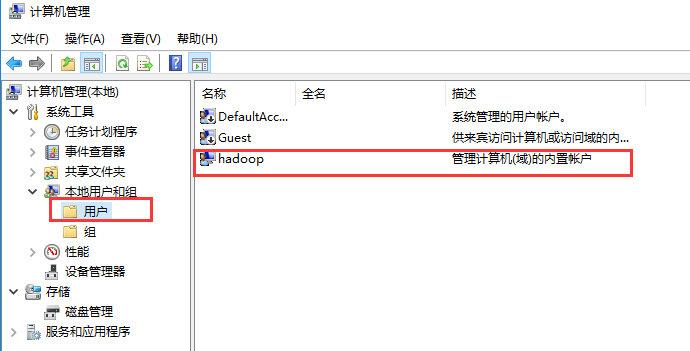
【Jser name】填写的windows电脑的用户名,右击【我的电脑】-->【管理】-->【本地用户和组】-->【修改用户名字】
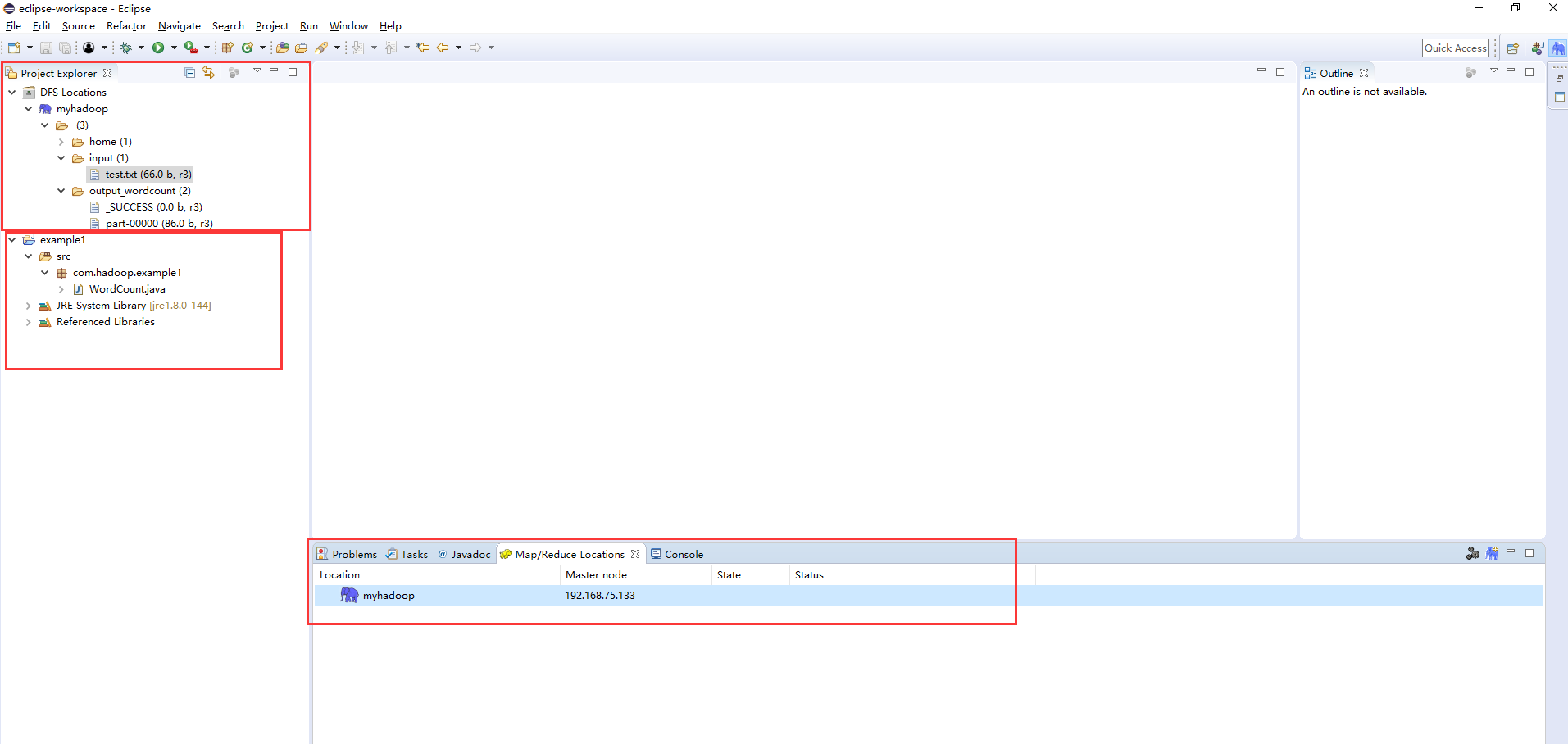
完成前面的步骤后,正常的eclipse界面应该像下图那样的。注意example1工程是我自己新建的,主要是用来验证eclipse能否远程连接hadoop集群来开发mapreduce程序。并且,此时在eclipse的HDFS视图界面对HDFS的操作(增删查)和在命令行上对HDFS操作的结果是一样的。
3、开发mapreduce程序
3.1、新建mapreduce工程

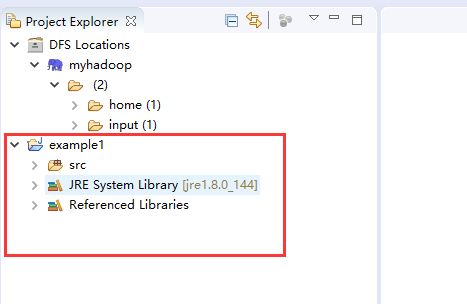
使用插件开发的好处这时显示出来了,完成这一个步骤,在工程视图会出现一个mapreduce工程模板,不用我们自己导入hadoop的jar包。下图红框就是新建mapreduce工程后生成的空模板,我们需要做的是在src文件夹中新建包和开发java程序。
3.3、在远程终端中通过命令行方式上传文件hadoop fs -put test.txt /input/ 或者 通过eclipse 的HDFS视图上传input文件: /input/test.txt,内容如下:
liang ni hao ma
wo hen hao
ha
qwe
asasa
xcxc vbv xxxx aaa eee
3.2、WordCount.java程序
package com.hadoop.example1; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobClient; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.TextOutputFormat; public class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
3.3、运行examplse1工程
注意的这种开发方式运行采用的是:run on haoop
运行方法:【右击工程】-->【Run as】-->【run on hadoop】 。在这里如果跳出一个界面让你选择,证明现在工程选用的Java Applicaltion不对。这时可以这样做:【右击工程】-->【Run as】-->【run on configrations】。并填写传的参数是输入文件路径和输出目录路径。


在Linux eclipse上开发,以上步骤都成功的话程序会正常运行。但是在windows eclipse 下开发会以下错误。因为在hadoop源码中会检查windows文件权限,因此,我们要修改hadoop源码。
14/05/29 13:49:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/05/29 13:49:16 ERROR security.UserGroupInformation: PriviledgedActionException as:ISCAS cause:java.io.IOException: Failed to set permissions of path: mphadoop-ISCASmapredstagingISCAS1655603947.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: mphadoop-ISCASmapredstagingISCAS1655603947.staging to 0700 at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:691) at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:664) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:514) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:349) at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:193) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:126) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:942) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Unknown Source) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936) at org.apache.hadoop.mapreduce.Job.submit(Job.java:550) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:580) at org.apache.hadoop.examples.WordCount.main(WordCount.java:82)
3.4、修改hadoop源码以支持windows下eclipse开发mapreduce程序。
出现问题的代码位于 【hadoop-1.2.1srccoreorgapachehadoopfsFileUtil.java】。
修改方式如下,注释掉对文件权限的判断。
private static void checkReturnValue(boolean rv, File p, FsPermission permission) throws IOException { /** * comment the following, disable this function if (!rv) { throw new IOException("Failed to set permissions of path: " + p + " to " + String.format("%04o", permission.toShort())); } */ }
然后将修改好的文件重新编译,并将.class文件打包到hadoop-core-1.2.1.jar中,并重新刷新工程。这里,为了方便大家,我提供已经修改后的jar文件包,如果需要可以点击下载,并替换掉原有的hadoop-1.2.1中的jar包,位于hadoop-1.2.1根目录。
再次3,3步骤的操作,这时运行成功了。
3.5查看结果
在HDFS视图刷新后,可以看到生成output_wordcount文件夹,进入此目录可以看见生成的part-00000,其结果为:![]()
