1. 慢查询基础:优化数据访问
-
是否向数据库请求了不需要的数据
- 有些查询会请求超过实际需要的数据,这会给MySQL服务器带来额外的负担,并增加网络开销,也会消耗应用服务器的CPU和内存资源。有一些典型的案例:
- 查询不需要的记录:一个常见的错误是误以为MySQL只返回了需要的数据,实际上是返回了全部的数据后再进行计算的一些查询。最简单有效的方法是加上
LIMIT。 - 多表关联时返回全部列
- 总是取出全部列:取出全部列,会让优化器无法完成索引覆盖扫描这类优化,还会带来额外的I/O、内存和CPU消耗。但是获取并缓存所有的列的查询,相比多个独立的只获取部分列的查询可能就更有好处。
- 重复查询相同的数据:不断执行相同的查询,但是每次都返回相同的数据。
- 查询不需要的记录:一个常见的错误是误以为MySQL只返回了需要的数据,实际上是返回了全部的数据后再进行计算的一些查询。最简单有效的方法是加上
- 有些查询会请求超过实际需要的数据,这会给MySQL服务器带来额外的负担,并增加网络开销,也会消耗应用服务器的CPU和内存资源。有一些典型的案例:
-
MySQL是否在扫描额外的记录
- 对于MySQL,最简单的衡量查询开销的三个指标是:响应时间、扫描的行数、返回的行数。
- 在
EXPLAIN语句中的type列反应了访问类型。访问类型有很多种,详见下表的解释。type类型从下到上逐渐变好,使用的索引至少要达到range级别。type类型 解释 null -- system const的特例,仅返回一条数据的时候。 const 查找主键索引,返回的数据至多一条(0或者1条)。 属于精确查找 eq_ref 查找唯一性索引,返回的数据至多一条。属于精确查找 ref 查找非唯一性索引,返回匹配某一条件的多条数据。属于精确查找、数据返回可能是多条 range 查找某个索引的部分索引,一般在where子句中使用 < 、>、in、between等关键词。只检索给定范围的行,属于范围查找 index 查找所有的索引树,比ALL要快的多,因为索引文件要比数据文件小的多。 ALL 不使用任何索引,进行全表扫描,性能最差。 - 一般MySQL使用如下三种方式应用
WHERE条件,从好到坏依次为:- 在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的。
- 使用索引覆盖扫描(在Extra列中出现了Using index),直接从索引中过滤不需要的记录并返回命中的结果。这是MySQL服务器层完成的,但是不需要回表查询记录。
- 从数据表中返回数据,然后过滤不满足条件的记录(在Extra列中出现了Using where)。这在MySQL服务器层中完成。
- 如果发现查询需要扫描大量的数据但是只返回少数的行,可以通过尝试下面的技巧去优化:
- 使用索引覆盖扫描,把所有需要用到的列都放到索引中。
- 改写库表结构,例如使用单独的汇总表。
- 重写复杂的查询。
2. 重构查询的方式
- 一个复杂查询还是多个简单查询
- 一般而言,如果一个查询能够胜任时还写成多个独立查询是不明智的。
- 切分查询
- 切分查询是将大量的数据以行为单位切分成小查询。比如删除数据的情况,如果用一个大的语句一次性删除的话,可能会锁住很多数据,阻塞很多查询。这时我们可以采用分批删除,将一个大的DELETE语句切分成多个较小的查询。
- 分解关联查询
- 很多应用会将关联查询分解为多个单次单表的查询语句,然后将结果在应用程序中关联。这样虽然需要多次访问,但是有以下的一些优势:
- 让缓存的效率更高。
- 执行单个查询可以减小锁的竞争。
- 在应用层做数据的关联,可以更容易对数据库进行拆分,做到高性能和可拓展。
- 可以减小冗余记录的查询。
- 很多应用会将关联查询分解为多个单次单表的查询语句,然后将结果在应用程序中关联。这样虽然需要多次访问,但是有以下的一些优势:
3. 查询执行的基础
-
MySQL服务端/客户端通信协议
- MySQL服务器和客户端之间的通信是半双工的,也就是同一时刻,要么是服务器正在向客户端发送数据,要么是客户端正在向服务器发送数据。
- 大多数MySQL的库函数在获取数据时,都是将全部结果获取后缓存到内存中,再供应用服务获取。
- 查询状态:可以使用
SHOW FULL PROCESSLIST命令查询所有线程当前的状态。如果是root帐号,能看到所有用户的当前连接,如果是其他普通帐号,则只能看到自己占用的连接。SHOW PROCESSLIST可以列出当前100条。该命令返回结果中的Command列表示了线程当前的状态,关于该列值的函数可详见MySQL官方文档。书中简单列了如下几个:- Sleep。线程正在等待客户端发送新的请求。
- Query。线程正在执行查询或将结果发送给客户端。
- Locked。在MySQL服务器层,该线程正在等待表锁。在存储引擎级别实现的锁,例如InnoDB的行锁,并不会体现在线程状态中。
- Analyzing and statistics。 正在收集存储引擎统计信息,生成查询计划。
- Sorting Data。正在对结果集排序。
- Copying to tmp table [on disk]。正在执行查询,并将结果集复制到一个临时表中。[on disk]表示正在将一个内存临时表放到磁盘上。

-
查询缓存
- 如果打开了查询缓存,则MySQL在每次查询前会优先检查这个查询是否名字查询缓存中的数据。这个检查是通过一个对大小写敏感的哈希查找实现的。查询和缓存中的查询即使只有一个字节不同,那也不会匹配查询缓存结果。
-
查询优化处理
-
语法解析器和预处理
- 语法解析器通过关键字将SQL语句进行解析,生成一颗对应的“解析树”,并校验语法规则。
- 预处理器进一步验证数据表和数据列等是否存在,并验证权限等。
-
查询优化器
-
一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
-
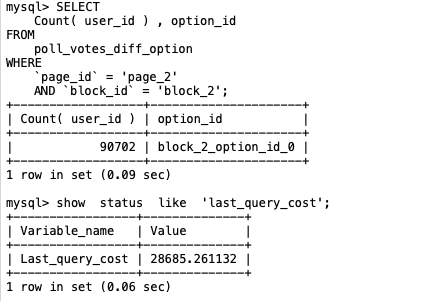
MySQL优化器是基于成本的优化器,可以通过查询当前会话的
Last_query_cost的值来得知MySQL计算的当前查询的成本。
-
有一些原因会导致MySQL优化器选择错误的执行计划,比如:统计信息不准确,不考虑其他并发的查询,估算的成本不等同于实际执行的成本等。
-
MySQL的优化策略可分为两种,一种是静态优化,一种是动态优化。动态优化与查询的上下文有关,比如WHERE条件中的取值,索引条目等。动态优化每次执行时都会重新评估。
-
如下为MySQL优化器的一些优化类型:
- 重新定义关联表的顺序。
- 将外连接转换为内连接。
- 使用等价变换规则。如将
WHERE条件中的(5 = 5 AND a > 5)改写为a > 5。 - 优化
COUNT()、MIN()、MAX()。对于MIN/MAX可以根据索引直接找到最左端/右端的记录。对于全表的COUNT(*)则可以利用存储引擎中的一些统计信息。 - 预估并转化为常数表达式。
- 覆盖索引扫描。
- 子查询优化。减小子查询访问的数量。
- 提取终止查询。如使用
LIMIT子句。 - 列表IN()的比较。IN()并不完全等同与多个OR条件的子句。MySQL会将IN()列表中的数据先进行排序,然后通过二分查找的方式确定是否满足条件,这是一个更低复杂度的操作。
-
-
数据和索引的统计信息
- MySQL查询优化器位于服务器层。但是优化器依赖的统计信息是由存储引擎提供的。
-
排序优化
- 排序是一个成本很高的操作,应尽可能避免排序。当不能使用索引生成排序结果时,MySQL服务器需要自行排序,如果数据量小则在内存中进行,数据量大则需要使用磁盘。但是MySQL将这个过程统一称为文件排序(filesort),即使是完全内存排序,没有用到磁盘文件。
- MySQL有两种排序算法:两次传输排序和单次传输排序。
- 两次传输排序是在旧版本使用的,其首先读取行指针和排序字段,对其进行排序后,再根据行指针读取所需数据。这样做的优点是内存可以容纳更多的行数进行排序。缺点则是,根据排序后的结果读取数据行,可能产生大量的随机IO。
- 单次传输排序是再新版本使用的,其先查询所有需要的列,再根据指定列排序后,直接返回排序结果。这样做的优点是数据读取是顺序IO,且只需要读取一次。缺点是读取出来的数据可能非常大,将在排序时占用更多的空间。
-
-
查询执行引擎
- 在解析和优化阶段,MySQL将生成查询对应的执行计划,交由执行引擎执行。这里的执行计划是一个数据结构,而不是字节码。
4. MySQL查询优化器的局限性
-
关联子查询
- MySQL对于WHERE条件中包含IN的子查询语句表现往往比较糟糕。
-
UNION的限制- MySQL无法将限制条件从外层下推到内层。比如
UNION查询,如果希望各个子句能够根据LIMIT只取部分结果集,或者能够先排好序的话,只能在UNION的各个子句中分别使用这些条件。比如如下这个查询,想将两个子查询的结果合并后取10条。MySQL 的做法是两个子查询的所有结果放到一个临时表,再取前10条记录。

这条查询会将snapshots 表的2000条记录和 changes 表的1000条记录都放到一个临时表中,再取前10条。这样的性能将会比较差。一种优化的方式是将每一个子查询都加上LIMIT 10的条件,这样临时表中就只会有20条记录。如下所示:

- MySQL无法将限制条件从外层下推到内层。比如
-
并行执行
- MySQL无法利用多核特性来并行执行查询。
-
松散索引扫描
- MySQL不支持松散索引扫描。
- 关于松散索引扫描,可以这样理解。假设我们有一个联合索引
(a, b),有如下的查询:SELECT * FROM tbl WHERE b = 3;。由于查询中只指定了字段b,根据联合索引的最左匹配原则,MySQL无法使用这个索引,最终通过全表扫描的方式得到结果。但是按照索引的物理结构,其实一个更快的查询方式是,先扫描a列第一个值中对应b列的数据,以此类推扫描a列剩余值中对应b列的数据。这样避免了全表扫描,可以利用索引加快寻找b列的速度。这种优化的方式就称为松散索引扫描。(但是MySQL默认不支持) - 有一些特殊的方式可以在 MySQL 中使用松散索引扫描。比如在查询语句中添加左侧索引列的
ORDER BY或者GROUP BY条件。这使得MySQL优化器会因此选择索引。比如上述语句可重写为:SELECT * FROM tbl WHERE b = 3 ORDER BY a;或:SELECT * FROM tbl WHERE b = 3 GROUP BY a;。
5. 查询优化器的提示
如果对优化器选择的执行计划不满意,可以使用优化器提供的提示来控制最终的执行计划。
-
HIGH PRIORITY和LOW PRIORITY- 这个提示告诉 MySQL,当多个语句同时访问某一个表的时候,哪些语句优先级高,哪些语句优先级低。这两个提示只对使用表锁的存储引擎有效。
HIGH PRIORITY将语句调度到所有正在等待表锁的语句之前,LOW PRIORITY则相反。
- 这个提示告诉 MySQL,当多个语句同时访问某一个表的时候,哪些语句优先级高,哪些语句优先级低。这两个提示只对使用表锁的存储引擎有效。
-
DELAYED- 这个提示对于
INSERT和REPLACE有效。MySQL 会将使用该提示的语句立即返回给客户端,并将写入的数据放入缓冲区,待表空闲时批量将数据写入。日志系统,或是其他需要写入大量数据但是客户端不需要等待单条语句完成 IO 的应用很适合使用这样的提示。
- 这个提示对于
-
STRAIGHT_JOIN- 这个提示可以放在
SELECT语句的SELECT关键字之后或任何两个关联表的名字之间。第一个用法是让查询中所有的表按照语句中出现的顺序进行关联。第二种则是固定其前后两个表的关联顺序。当明确某个关联顺序始终是最佳时,可以采取这个提示。
- 这个提示可以放在
-
SQL_SMALL_RESULT和SQL_BIG_RESULT- 这两个提示只对
SELECT语句有效。其告诉优化器对GROUP BY或者DISTINCT查询如何使用临时表排序。SQL_SMALL_RESULT表示结果集很小,可以使用内存排序。SQL_BIG_RESULT表示结果集很大,建议使用磁盘做排序。
- 这两个提示只对
-
SQL_BUFFER_RESULT- 这个提示是告诉优化器将查询结果放入一个临时表,然后尽快释放表锁。
-
FOR UPDATE和LOCK IN SHARE MODE- 这两个不是真正的优化器提示。这两个主要控制
SELECT语句的锁机制,但只对实现了行级锁的存储引擎有效。这两个提示会对符合查询条件的数据行加锁。唯一内置的支持这两个提示的引擎是 InnoDB。
- 这两个不是真正的优化器提示。这两个主要控制
-
USE INDEX、IGNORE INDEX和FORCE INDEX- 这几个提示会告诉优化器使用或不使用哪些索引来查询记录。
USE INDEX和FORCE INDEX基本相同,但是`FORCE INDEX``会告诉优化器全表扫描的成本远远高于索引扫描。
- 这几个提示会告诉优化器使用或不使用哪些索引来查询记录。
6. 优化特定类型的查询
-
COUNT()查询COUNT()可以统计某个列值的数量,也可以统计行数。- *MYISAM 只对没有任何条件的
COUNT(*)才有优化,其他情况和其他存储引擎没有不同。 - 通常来说,
COUNT()都需要扫描大量的行才能获得精确的结果,因此是非常难优化的。除了前面的方法,在 MySQL 层面还能做的就只有覆盖索引扫描了。如果还不够,就需要从应用架构上考虑,比如增加汇总表。
-
LIMIT分页LIMIT查询一个非常大的问题是,当偏移量很大的时候,比如LIMIT 10000, 100这样的查询,MySQL 需要查询10100条记录,然后只返回最后100条,而前面的10000条数据都将被抛弃,这样的代价非常高。- 一种优化的方式是将
LIMIT转换为已知位置的查询,比如:SELECT * FROM tbl WHERE pos > 10000 ORDER BY pos ASC LIMIT 100。一般情况下也可以使用自增主键列替代这里的 pos 列,但是要注意有索引可以使用。
-
UNION查询- MySQL总是通过创建并填充临时表的方式来执行
UNION查询。因此很多优化策略在UNION查询中无法很好的使用,常常需要手工将WHERE、LIMIT、ORDER BY等子句"下推到"UNION``各个子查询中,以便优化器可以充分利用这些条件优化。 - 除非确实需要服务器消除重复的行,否则一定要使用
UNION ALL。如果没有ALL关键字,MySQL 会给临时表加上DISTINCT选项,进而导致对整个临时表做唯一性检查,这样的代价非常高。
- MySQL总是通过创建并填充临时表的方式来执行
-
使用用户自定义变量
- 用户自定义变量的一些限制
- 使用自定义变量的查询,无法使用查询缓存。
- 不能在使用常量或者标识符的地方使用自定义变量,比如:表名、列名和 LIMIT 子句中。
- 用户自定义的变量的生命周期是在一个链接中有效。如果使用连接池或者持久化链接,自定义变量有可能导致 BUG。
- MySQL 优化器在某些场景下可能会将这些变量优化掉。
- 统计更新和插入的数量
- 当使用了
INSERT ON DUPLICATE KEY UPDATE时,如果想知道插入了多少行数据,有多少数据是因为冲突而改写成更新操作的。可以利用自定义变量实现:INSERT INTO t1(c1, c2) VALUES(4, 4), (2, 1), (3, 1) ON DUPLICATE KEY UPDATE c1 = VALUES(c1) + (0 * ( @x := @x + 1) );。由于每次冲突会导致更新时对变量@x 自增一次。然后通过对这个表达式乘以0来让其不影响要更新的内容,由此可以得知因为冲突而改写成更新操作的记录数量。
- 当使用了
- 用户自定义变量的一些限制
本章有较大篇幅介绍了关联查询和子查询一类的优化。但是在我个人的工作实践中,关联查询是在数据库查询中绝对不可能采用的大忌,故而记录时对该部分没有过多重视