今天学习了hive的一些基本知识,感觉自己还是有点把企业异常信息想的有点太难了,不就是一个增删改查,只不过需要使用到大数据,在我学完hive之后,感觉有点思路了,主要做了一些hive基本知识的了解,总结了一些常用语句


show databases; show tables; create table text(id int,name string) row format delimited fields terminated by ','; 1,zhangsan,篮球:非常喜欢-跳舞:喜欢-游泳:一般般 2,lise,篮球:非常喜欢-跳舞:喜欢-游泳:一般般 分区表的创立 create table t_user(id int,name string) partitioned by(country string) row format delimited fields terminated by ','; 分区表的插入数据 LOAD DATA local INPATH '/usr/text/hive/t_user1.txt' INTO TABLE t_user partition(country='china');
然后找到了一个hive的万能工具类
做了一些测试
完成了老师安排的所有mapreduce任务
给一个截图如下:
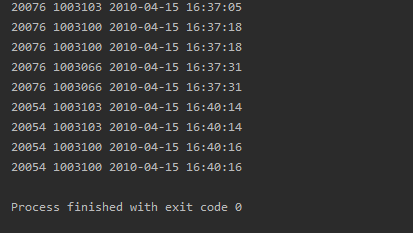
总结一下这些天做的东西吧,这两天才算是真正理解了Hadoop可以做什么,以及hdfs,hbase,hive,mapreduce的运行规律,并完成了一些测试
其实这些东西真的不难,好多东西都是一看就懂,还是吧这些东西想的太难了,其实真的不难
计划再花三天左右的时间,完成这个企业异常统计!
!!!!!!加油!!!!111111111