在上一章我们安装了开发的IDE,但是要开发一个好的爬虫工具,我们还要安装一些第三方的库,现在很多第三方的库非常的成熟稳定了。我们可以直接拿来使用不用重复造轮子,开发效率大大的提高。下面我们就开始装库之路吧。
首先在vs2017如何安装第三方库?请看下面4个步骤:
1、在vs2017新建一个Python项目

2、展开项目的Python环境

3、鼠标对着上图中Python3.6右键
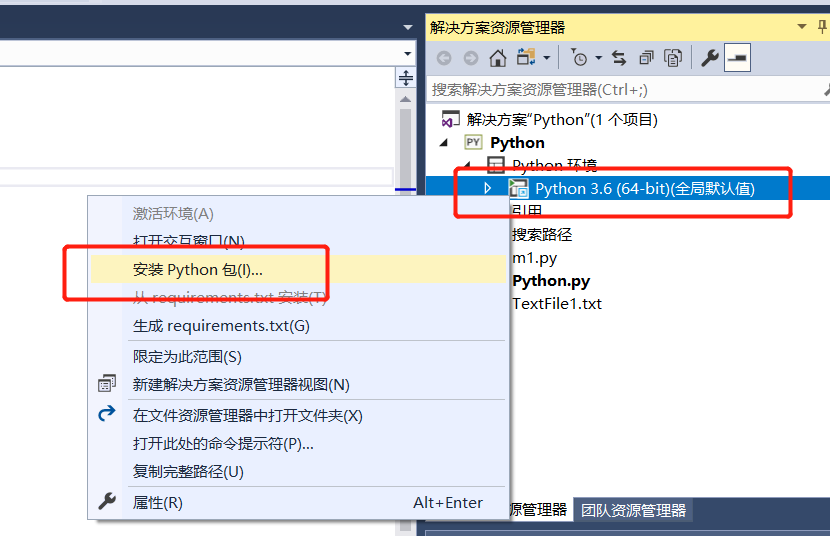
4、输入第三方库名称点击安装
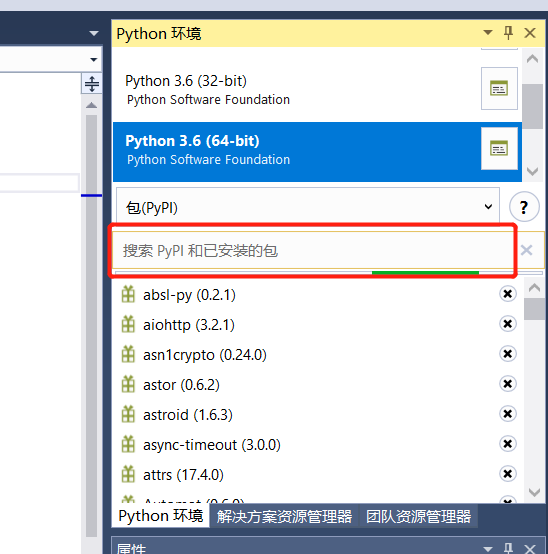
以上就是在vs2017上安装第三方库的步骤,是不是非常滴简单,接下来开始介绍要使用到的第三方库及安装方法。
相关连接
GitHub:https://github.com/requests/requests
PyPI:https://pypi.python.org/pypi/requests
官方文档:http://www.python-requests.org
中文文档:http://docs.python-requests.org/zh_CN/latest
二、Selenium库安装
Selenium是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些JavaScript渲染的页面来说,这种抓取方式非常有效。
相关链接
官方网站:http://www.seleniumhq.org
GitHub:https://github.com/SeleniumHQ/selenium/tree/master/py
PyPI:https://pypi.python.org/pypi/selenium
官方文档:http://selenium-python.readthedocs.io
中文文档:http://selenium-python-zh.readthedocs.io
三、PhantomJS库安装
PhantomJS是一个无界面的、可脚本编程的WebKit浏览器引擎,它原生支持多种Web标准:DOM操作、CSS选择器、JSON、Canvas以及SVG。Selenium支持PhantomJS,这样在运行的时候就不会再弹出一个浏览器了。而且PhantomJS的运行效率也很高,
还支持各种参数配置,使用非常方便。下面我们就来了解一下PhantomJS的安装过程。
相关链接
官方网站:http://phantomjs.org
官方文档:http://phantomjs.org/quick-start.html
下载地址:http://phantomjs.org/download.html
API接口说明:http://phantomjs.org/api/command-line.html
安装步骤:我们需要在官方网站下载对应的安装包,PhantomJS支持多种操作系统,比如Windows、Linux、Mac、FreeBSD等,我们可以选择对应的平台并将安装包下载下来。
下载完成后,将PhantomJS可执行文件所在的路径配置到环境变量里。比如在Windows下,将下载的文件解压之后并打开,会看到一个bin文件夹,里面包括一个可执行文件phantomjs.exe,我们需要将它直接放在配置好环境变量的路径下或者将它所在的路径配置
到环境变量里。比如,我们既可以将它直接复制到Python的Scripts文件夹,也可以将它所在的bin目录加入到环境变量。
四、aiohttp请求库
相关链接
官方文档:http://aiohttp.readthedocs.io/en/stable
GitHub:https://github.com/aio-libs/aiohttp
PyPI:https://pypi.python.org/pypi/aiohttp
之前安装Requests库是一个阻塞式HTTP请求库,当我们发出一个请求后,程序会一直等待服务器响应,直到得到响应后,程序才会进行下一步处理。其实,这个过程比较耗费资源。如果程序可以在这个等待过程中做一些其他的事情,如进行请求的调度、响应的
处理等,那么爬取效率一定会大大提高。
aiohttp就是这样一个提供异步Web服务的库,从Python 3.5版本开始,Python中加入了async/await关键字,使得回调的写法更加直观和人性化。aiohttp的异步操作借助于async/await关键字的写法变得更加简洁,架构更加清晰。使用异步请求库进行数据抓取时,
会大大提高效率。
五、lxml解析库安装
相关链接
官方网站:http://lxml.de
GitHub:https://github.com/lxml/lxml
PyPI:https://pypi.python.org/pypi/lxml
lxml是Python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
六、BeautifulSoup解析库安装
相关链接
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh
PyPI:https://pypi.python.org/pypi/beautifulsoup4
BeautifulSoup是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据。它拥有强大的API和多样的解析方式。
Beautiful Soup的HTML和XML解析器是依赖于lxml库的,所以在此之前请确保已经成功安装好了lxml库