有两种数据结构(散列表和链表)经常会被放在一起使用。前面的章节中有两个地方讲到散列表和链表的组合使用,分别是:
另外,Java中有一个容器LinkedHashMap也使用到散列表和链表。
下面我们来看看这几个问题,散列表和链表是如何组合使用的。
LRU缓存淘汰算法
首先来回顾一下当时是如何通过链表实现LRU缓存淘汰算法的。
当缓存空间不够,需要淘汰一个数据的时候,就直接将链表头部的结点删除。
当缓存某个数据的时候,先在链表中查找这个数据,如果没有找到,则直接将数据放到链表的尾部;如果找到,就把它移动到链表的尾部。
总结一下,一个缓存(cache)系统主要包含下面几个操作:
1. 往缓存中添加一个数据;
2. 从缓存中删除一个数据;
3. 在缓存中查找一个数据;
因为查找数据需要遍历链表,所以使用链表实现的LRU缓存淘汰算法的时候复杂度是O(n)。
如果将散列表和链表两种数据结构组合使用,就可以把这三个操作的时间复杂度都降低到O(1)。
具体的结构如下:
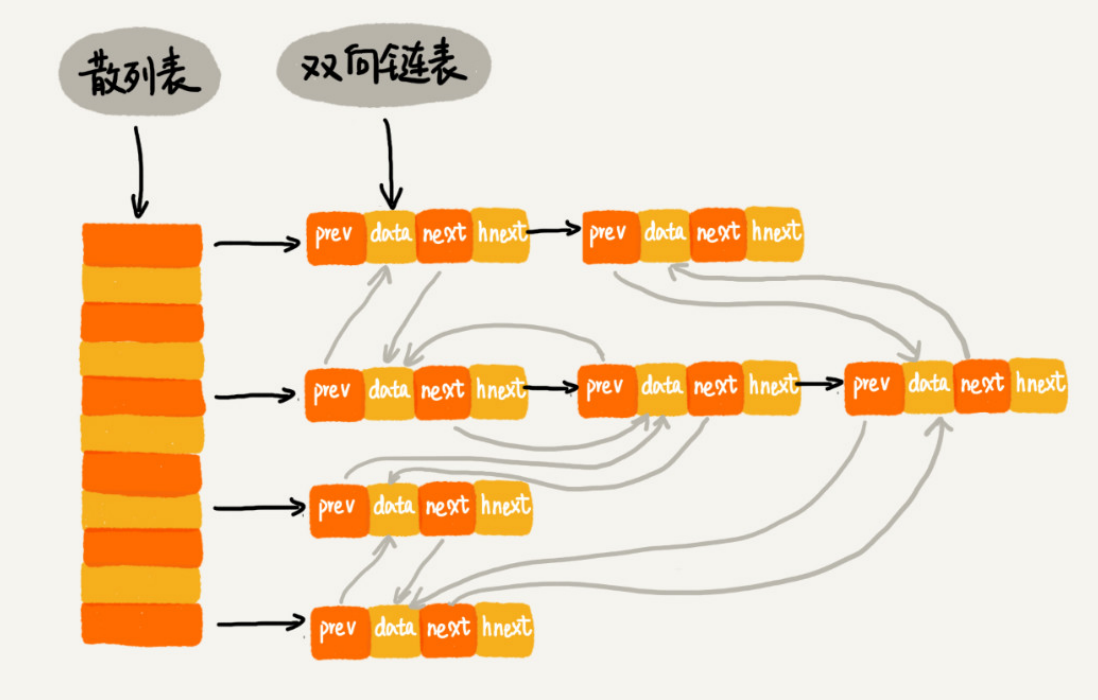
使用双向链表存储数据,链表中的每个结点处理存储数据(data)、前驱指针(prev)、后继指针(next)、还有一个特殊字段hnext,是为了将结点串在散列表的拉链中。
再来看看,缓存的三个操作是如何做到时间复杂度是O(1)的。
如何查找一个数据
通过散列表可以很快找到一个数据,然后移到双向链表的尾部。
如何删除一个数据
通过散列表在O(1)时间内找到结点,再通过双向链表找到前驱结点,删除当前结点。
如何添加一个数据
添加数据到缓存稍微有点麻烦。需要先看这个数据是否在缓存中。
如果在,移到双向链表的尾部;
如果不在,还要看缓存是否满;
如果满了,就将双向链表头部的结点删除,然后再将数据放到链表的尾部;
如果没满,就直接将数据放到链表的尾部。
到此,通过散列表和双向链表的组合使用,实现了一个高效的、支持LRU缓存淘汰算法的缓存系统原型。
Redis有序集合
在有序集合中,每个成员对象有两个重要的属性,key(键值)和score(分值)。不仅会通过score来查找数据,还会通过key来查找数据。
细化一下Redis有序集合的操作:
1. 添加一个成员对象;
2. 按照键值来删除一个成员对象;
3. 按照键值来查找一个成员对象;
4. 按照分值区间查找数据,比如查找积分在[100, 356]之间的成员对象;
5. 按照分值从小到大排序成员变量;
如果仅仅按照分值将成员对象组织成跳表结构,那按照键值来删除、查询成员对象就会很慢。解决办法跟LRU缓存淘汰算法类似,再按照键值构建一个散列表,这样按照key来删除、查找一个成员对象的时间复杂度就变成了O(1)。
Java LinkedHashMap
看一下这段代码:
// 10是初始大小,0.75是装载因子,true是表示按照访问时间排序
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
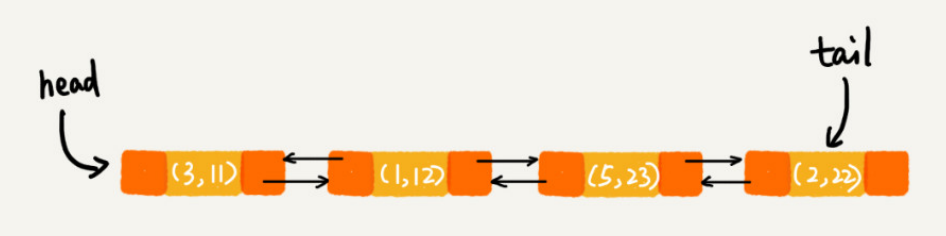
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
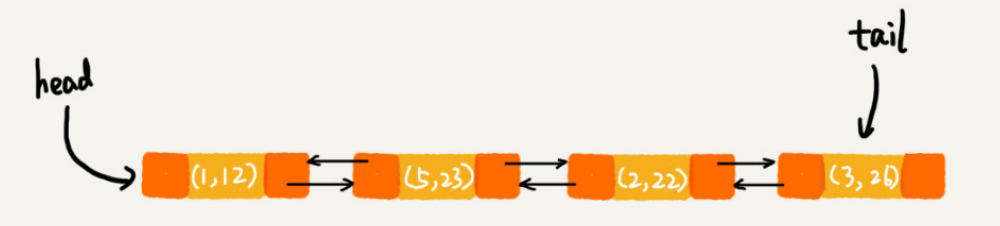
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
这段代码打印的结果是1,2,3,5。
每次调用put()函数,往LinkedHashMap中添加数据的时候,都会将数据添加到链表的尾部。
前6行代码执行后的效果:
第7行代码(m.put(3, 26);)执行后的效果:
第8行代码(m.get(5);)执行后的效果:

LinkedHashMap是通过双向链表和散列表这两种数据结构组合实现的。LinkedHashMap中的“Linked”实际上是指的是双向链表,并非指用链表法解决散列冲突。
总结一下,为什么散列表和链表经常一起使用?
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。
因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率就很低。为了解决这个问题,将散列表和链表(或者跳表)结合在一起使用。