一、问题描述
如何实现一个通用的、高性能的排序函数?
二、如何选择合适的排序算法
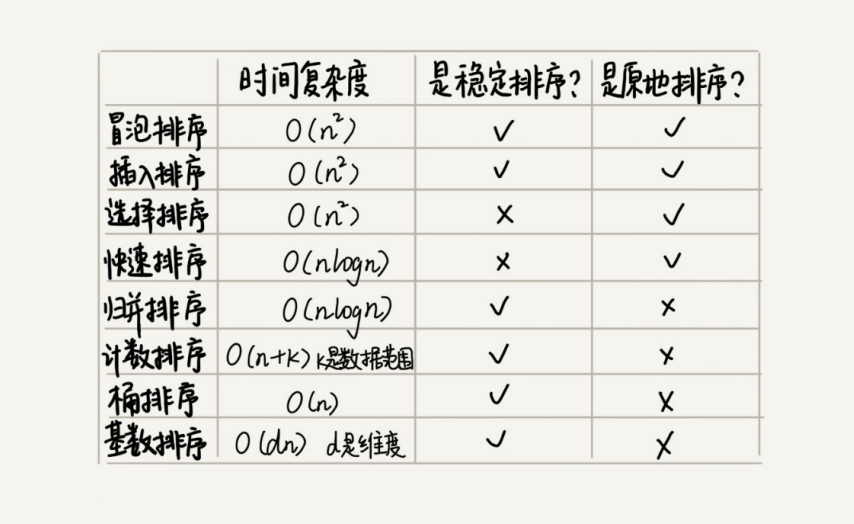
线性排序的时间复杂度比较低,适用场景特殊,不适合。
小规模数据排序,可以选择时间复杂度O(n2)的算法;
大规模数据排序,选择时间复杂度O(nlogn)的算法;比如Java采用堆排序,C语言使用快速排序。
三、如何优化快速排序
当数据原来就是有序或者接近有序,每次分区点选择最后一个数据,那快速排序算法的时间复杂度就会退化为O(n2)。
这种O(n2)时间复杂度出现的主要原因是分区点选的不合理。
两个常用的分区算法:
1. 三数取中法
2. 随机法
四、举例分析排序函数
以Glibc中的qsort()函数举例说明:
1. qsort()会优先使用归并排序来排序输入数据。
2. 当排序的数据量比较大的时候,qsort()会改为用快速排序算法来排序。
3. 在小规模数据面前,O(n2)时间复杂度的算法并不一定比O(nlogn)的算法执行时间长。
注:大O标记法代表的是一个增长趋势,实际上真正的时间复杂度同样受低阶、系数、常数的影响,假如系数和常数是比较大的数,那时间复杂度有可能更大。
4. 对于小数据量的排序,选择比较简单、不需要递归的插入排序算法。
五、课后思考
在今天的内容中,我分析了C语言的中的qsort()的底层排序算法,你能否分析一下你所熟悉的语言中的排序函数都是用什么排序算法实现的呢?都有哪些优化技巧?
介绍C#里的Array.Sort()函数。
Array.Sort()具有以下特点:
- 排序是不稳定的
- 采用内省排序(introspective sort)
内省排序会先以快速排序开始,当递归超过某一个深度d时,则会针对深度d上的每一个划分利用不同方法进行排序。
- 如果划分的大小小于16个元素,对该划分使用插入排序。
- 如果划分的大小超过2logn,n是数组长度,那么使用堆排序。
- 如果划分的大小介于两者宰,则继续使用快速排序。
仍然可以认为在内省排序中的时间复杂度是O(nlogn)。
核心函数源码:
private void IntroSort(int lo, int hi, int depthLimit)
{
int num1;
for (; hi > lo; hi = num1 - 1)
{
int num2 = hi - lo + 1;
if (num2 <= 16)
{
if (num2 == 1)
break;
if (num2 == 2)
{
this.SwapIfGreaterWithItems(lo, hi);
break;
}
if (num2 == 3)
{
this.SwapIfGreaterWithItems(lo, hi - 1);
this.SwapIfGreaterWithItems(lo, hi);
this.SwapIfGreaterWithItems(hi - 1, hi);
break;
}
this.InsertionSort(lo, hi);
break;
}
if (depthLimit == 0)
{
this.Heapsort(lo, hi);
break;
}
--depthLimit;
num1 = this.PickPivotAndPartition(lo, hi);
this.IntroSort(num1 + 1, hi, depthLimit);
}
}
