问题
1. jdbc-input-plugin 只能实现数据库的追加,对于 elasticsearch 增量写入,但经常 jdbc 源一端的数据库可能会做数据库删除或者更新操作。这样一来数据库与搜索引擎的数据库就出现了不对称的情况。当然你如果有开发团队可以写程序在删除或者更新的时候同步对搜索引擎操作。如果你没有这个能力,可以尝试我下面要说的方法。
2. 当然网上后续又出现了 go-mysql-elasticsearch 项目,同步 binlog 的方式实现,这种方式是可以解决 1 中的问题,但是由于 ElasticSearch 版本的升级迭代以及纷繁复杂的映射类型,导致该项目无法及时的满足我们应用场景,故一定程度上还是需要我们自己来开发一套新的流程来完全满足我们的需要。
解决办法
在数据库中增加一个更新时间字段以及是否删除标志位,例如:
我这里有一个数据表 article , mtime 字段定义了 ON UPDATE CURRENT_TIMESTAMP 所以每次更新 mtime 的时间都会变化,status 字段用于表征是否删除,默认为没有删除,具体如下:
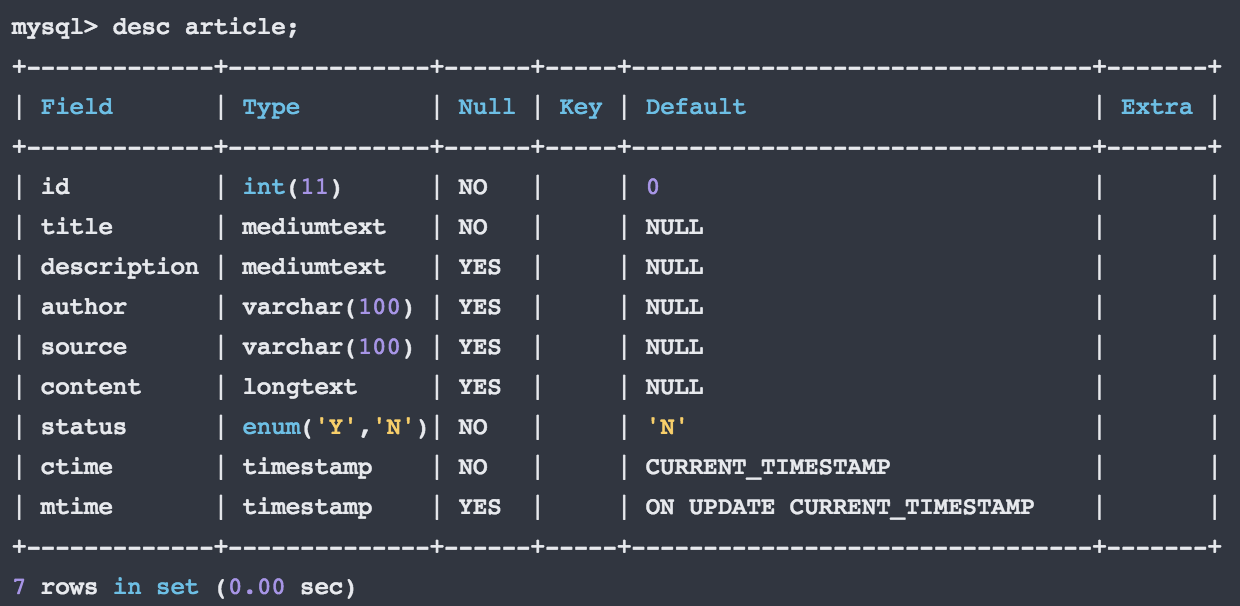
其中对 mtime 对应的 mysql 创建语句为:
`mtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间'
logstash 增加 mtime 的查询规则
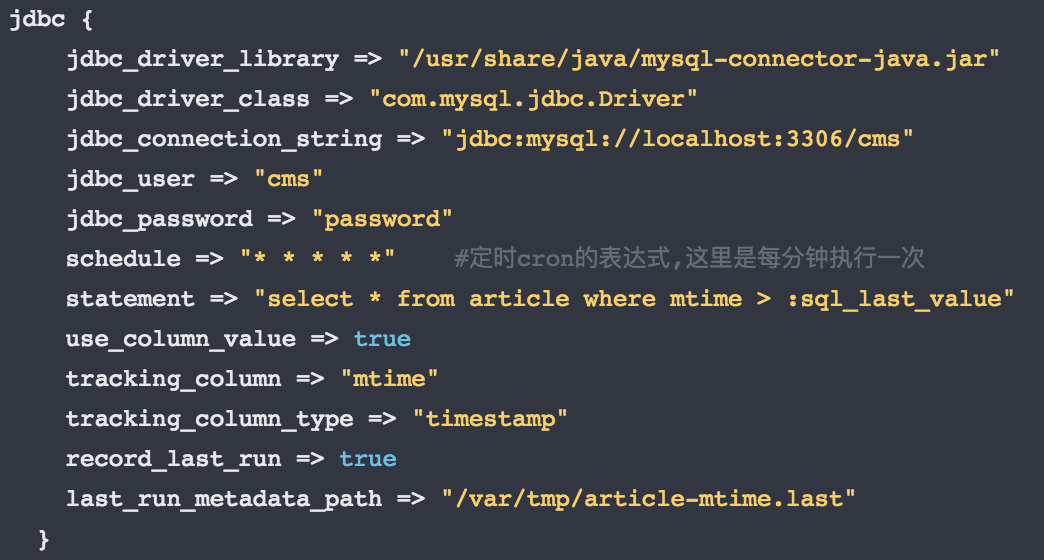
至此,可以分出两种解决方案:
第一种:直接通过应用程序定时的读取 mysql 表,通过 mtime 和 status 字段来确定 ElasticSearch 是 更新(新增) 还是 删除,之后拼接对应的 bulkRequest 请求直接发送给 ElasticSearch 服务端。
第二种:通过 logstash 来代替我们自己编写的应用程序,定时的扫描 mysql 表数据,再将数据同步到 ElasticSearch 服务端。