一.析构方法 (__del__)
构造方法:__new__ 创建(申请)一个空间
析构方法:__del__ 释放一个空间(某个对象借用了操作系统的资源,还要通过析构方法归还回去)
例如:垃圾回收机制
class A:
def __del__(self): ====>(析构方法:del A的对象的时候,会自动触发这个方法)
print("实现了del方法")
a = A()
del a ====>del 一执行的时候,就要删除对象,删除对象就要执行__del__析构方法,最后在删除对象
print(a)
析构方法什么时候执行?
(1) del对象的时候 (由程序员触发的)
(2) python解释器的垃圾回收机制,回收这个对象所占的内存的时候 (由python自动触发的)
在python中,当从头执行完程序的时候,会把所有的变量从内存中删除了
python解释器内部干的事?
python解释器在内部就能搞定的事
申请一块空间,操作系统会分配给一个空间
在这一块空间之内所有的事,归python解释器来管理
文件操作
例如:
class File:
def __init__(self,file_path):
self.f = open(file_path)
def read(self):
self.f.read(2018)
def __del__(self): 去归还/释放一些在创建对象的时候借用的一些资源
self.f.close()
f = File("文件名")
f.read()
不管是主动还是被动,这个f对象总会被清理掉,被清理掉的时候就会触发__del__方法,触发这个方法就会归还操作系统的文件资源
f = open("文件名") python是没有办法直接打开硬盘里面的文件的,它需要通过操作系统为它打开一个空间,且这个空间内有一个文件操作符,也就是文件句柄,此时python
才能够对该文件进行访问操作 (python ---操作系统---硬盘的文件---文件操作符(操作系统给的))
f.close() (关闭并归还操作系统打开的文件资源)
del f (删除python解释器存储的内存)
二.item系列 (对象[ ] 就需要实现item)
item系列和对象使用[]访问之有联系
例如:(在内置模块中,有一些特殊的方法,要求对象必须实现__getitem__和__setitem__才能使用)
class A:
def __getitem__(self, item):
print("执行了getitem",item)
return getattr(self,item) ====>getattr(self,k)
def __setitem__(self, key, value):
return setattr(self,key,value) ====>self.k = v
a = A()
a["k"] = "v" =====>调用了__setitem__
print(a["k"]) =====>调用了__getitem__
def __delitem__(self,key):
delattr(self,key)
del a["k"] ====>调用了__delitem__
例如:
class B:
def __init__(self,lst):
self.lst = lst
def __getitem__(self, item):
return self.lst[item]
def __setitem__(self, key, value):
self.lst[key] = value
def __delitem__(self, key):
self.lst.pop(key)
b = B(["111","222","333","444"])
print(b.lst[0]) ====>执行__init__ 111
print(b[0]) ====>执行__getitem__ 111
b[3] = "alex" ====>执行__setitem__
print(b.lst)
del b[2] ====>执行__delitem__
print(b.lst)
三.hash方法
底层数据结构基于hash值寻址的优化操作
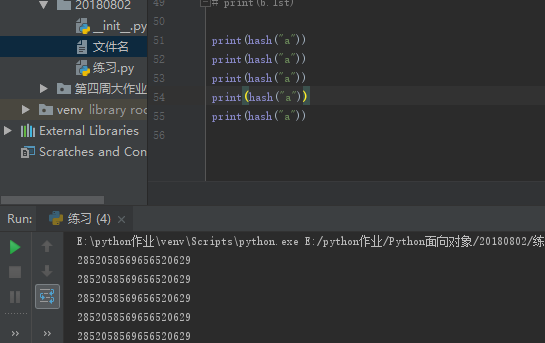
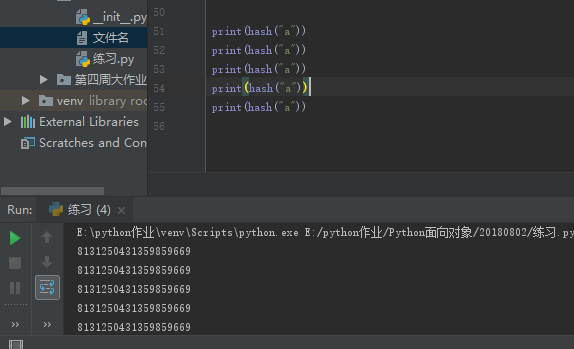
hash是一个算法,能够把某一个要存在内存里的值通过一系列计算,保证不同值的hash结果是不一样的
对于同一个值在多次执行python代码的时候,hash值是不同的,但是对同一个值,在同一次执行python代码的时候hash值永远不变
set集合去重机制
去重:先判断hash值是否一样,hash值一样后,在判断值是否相等(==),如果相等的话,就直接覆盖,如果不相等,就用其他算法另找内存条存储(二次寻址)
值等于是最准确的判断值相等的方式(==) 但是效率低下
字典的寻址 (自动去重)
d = {"key":"vaule"}
hash 内饰函数
hash(obj) obj内部必须实现了__hash__方法
四.eq(判断两个值是否相等)
例如:
class A:
def __init__(self,name,age):
self.name = name
self.age = age
def __eq__(self, other):
if self.name == other.name and self.age == other.age: 判断值是否相等,如果相等的话就返回True
return True
a = A("alex",34)
a1 = A("alex",34)
a2 = A("alex",34)
a3 = A("alex",34)
print(a == a1 == a2 == a3) ===>True (可以多值比较)
== 这个语法完全和__eq__一样,当执行到==的时候,就触发了__eq__这个方法
高级面试题
(1)首先定义一个类
(2)对象的属性有:姓名,性别,年龄,部门
(3)这个编程主要是写员工管理系统
(4)主要是一个人进行了内部转岗,员工资料需要进行更新
(5) 姓名 性别 年龄 部门
alex 男 34 python
alex 男 36 go
(6)假如该公司里面有600个员工,如果几个员工对象的姓名和性别一样就视为同一个人,请对这600个员工资料做去重工作
class Employee:
def __init__(self,name,sex,age,partment):
self.name = name
self.sex = sex
self.age = age
self.partment = partment
def __hash__(self):
return hash("%s%s" % (self.name,self.sex))
def __eq__(self, other):
if self.name == other.name and self.sex == other.sex:
return True
employ_lst = []
for i in range(200):
employ_lst.append(Employee("alex","男",i,"python"))
for i in range(200):
employ_lst.append(Employee("taibai","男",i,"go"))
for i in range(200):
employ_lst.append(Employee("wusir","男",i,"java"))
employ_set = set(employ_lst)
for person in employ_set:
print(person.__dict__)