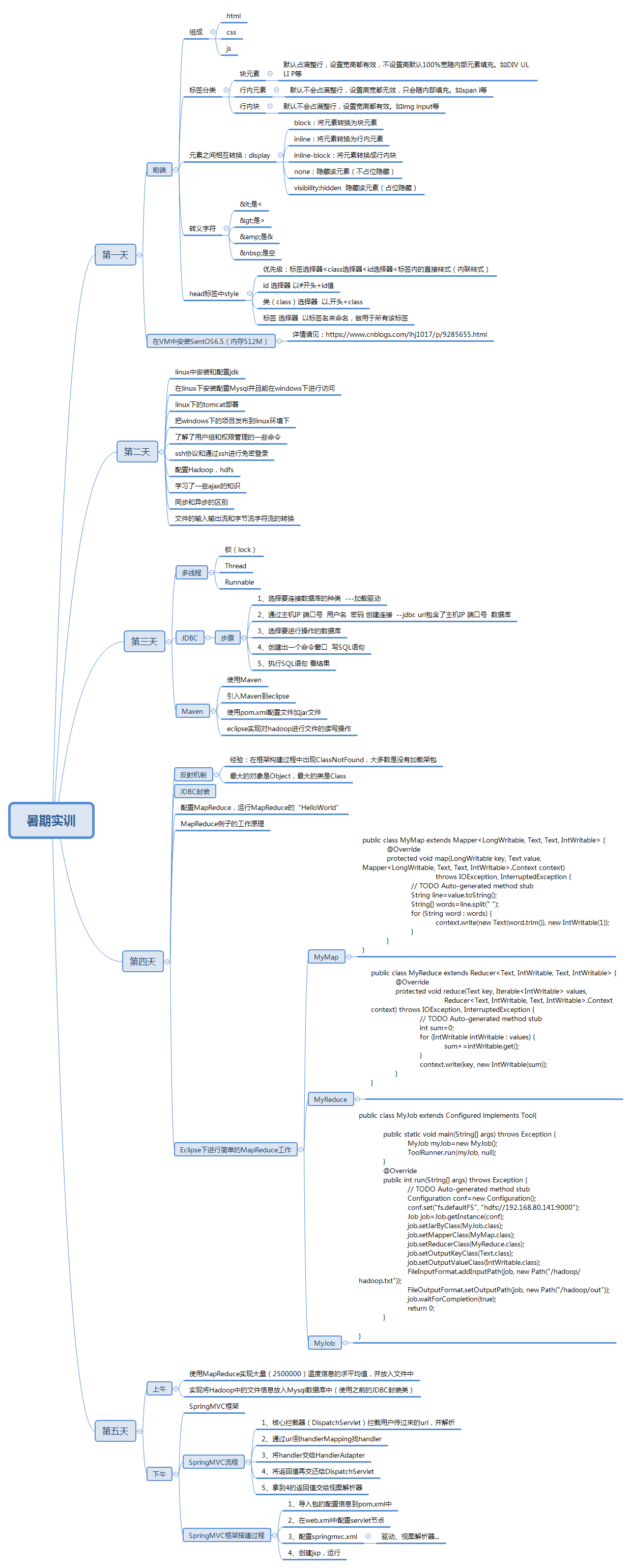
总结:
今天学习了使用MapReduce实现大量(2500000)温度信息的求平均值,并放入文件中
实现将Hadoop中的文件信息放入Mysql数据库中(使用之前的JDBC封装类);
SpringMVC流程:
1、核心拦截器(DispatchServlet)拦截用户传过来的url,并解析
2、通过url到handlerMapping找handler
3、将handler交给HandlerAdapter
4、将返回值再交还给DispatchServlet
5、拿到4的返回值交给视图解析器
SpringMVC框架搭建过程:
1、导入包的配置信息到pom.xml中
2、在web.xml中配置servlet节点
3、配置springmvc.xml 驱动、视图解析器...
4、创建jsp,运行
遇到的问题:
在使用MapReduce运行的时候,ecipse出现了错误,但是可以成功运行出结果,经过查询资料,知道了虽然hadoop已经配置好但是在bin文件中少了个文件,能运行的结果是因为把文件放入了c盘的windows的system32下了,可以使用,但是hadoop的bin目录下没有。
思维导图: