Distributed Transaction: Calvin & DOCC & Fauna
- Calvin: 发表于Sigmod12的一篇paper,期望是用deterministic 的方式来解决传统分布式事务。 (Google FAST'15的CalvinFS是基于Calvin的一个文件系统实现,Calvin在CalvinFS里解决FS Metadata的事务一致性问题)
- deterministic 确定性事务,意思是事物的冲突解决和顺序确定都是在事务实际执行之前(before tx boundaries)就确定好的。所谓before tx boundary,就是事务开始获取锁和开始执行事务具体步骤之前。
- DOCC (Deterministic and Optimistic Concurrency Control ): 上海交通大学(SJTU) IPADS实验室发表的一篇论文,期望解决Calvin在一些可并行事务下的串行化的性能问题,去识别出一些可以并行的事务。
- Fauna: so-called as first distributed database inspired by Calvin.
Calvin
Ref:
- 《Calvin: Fast Distributed Transactions for Partitioned Database Systems》
- https://github.com/yaledb/calvin
Summary
在Calvin刚发表的那会,由于大数据的浪潮,很多分布式数据库如那个时代的Cassandra、MongoDB等蓬勃发展。但和传统RDMS相比,这些大数据数据库往往牺牲了强事务支持来换取更高的可用性(A)和分区容忍性(P),同时对一致性约束的减弱也使得负载打散、线性拓展、基础运维等变得更容易(假设业务对一致性也不是那么敏感)。Calvin paper里提出了当时的两个趋势: 1. NoSQL的发展,大家对ACID特性弱的NoSQL的热情比对传统RDMS高;2. 复制技术(Paxos等)的发展也使得数据库系统对自身的一致性保证问题不再那么重视,如上文所说,CAP中为了AP舍弃C。但是论文发表的那两年,由于全球信息基础建设的加强(作者的猜测),网络问题得到了很大改善,P的问题已经没那么显著,趋势2出现了逆转。在这一前提下,单纯采用paxos等复制技术,分区间的网络延迟会很高。因此,Calvin想要解决这一问题。
传统的一些悲观事务方法如2PC等,会带来较大的事务协议本身的运行开销,甚至会大于实际事务内容本身的运行时间。Calvin这里定义了一个contention footprint的概念—— total duration a transaction holds its locks 。这一概念同样可以拓展到乐观事务,乐观事务的主要contention不是在lock,而是在提交前检查阶段的频繁冲突导致的事务abort,在一些大量事务冲突的情况下,乐观控制的争抢开销可能会更大。但是Calvin paper并未过多探讨与乐观事务对比的问题。Calvin的主要目标是减少contention footprint;主要的思想是将冲突检测提前到事务持锁之前,检测完后生成一个确定性的事务序列(deteministic order),然后按照序列执行。因此,Calvin本身是可串行化的事务隔离级别的协议。
Architecture
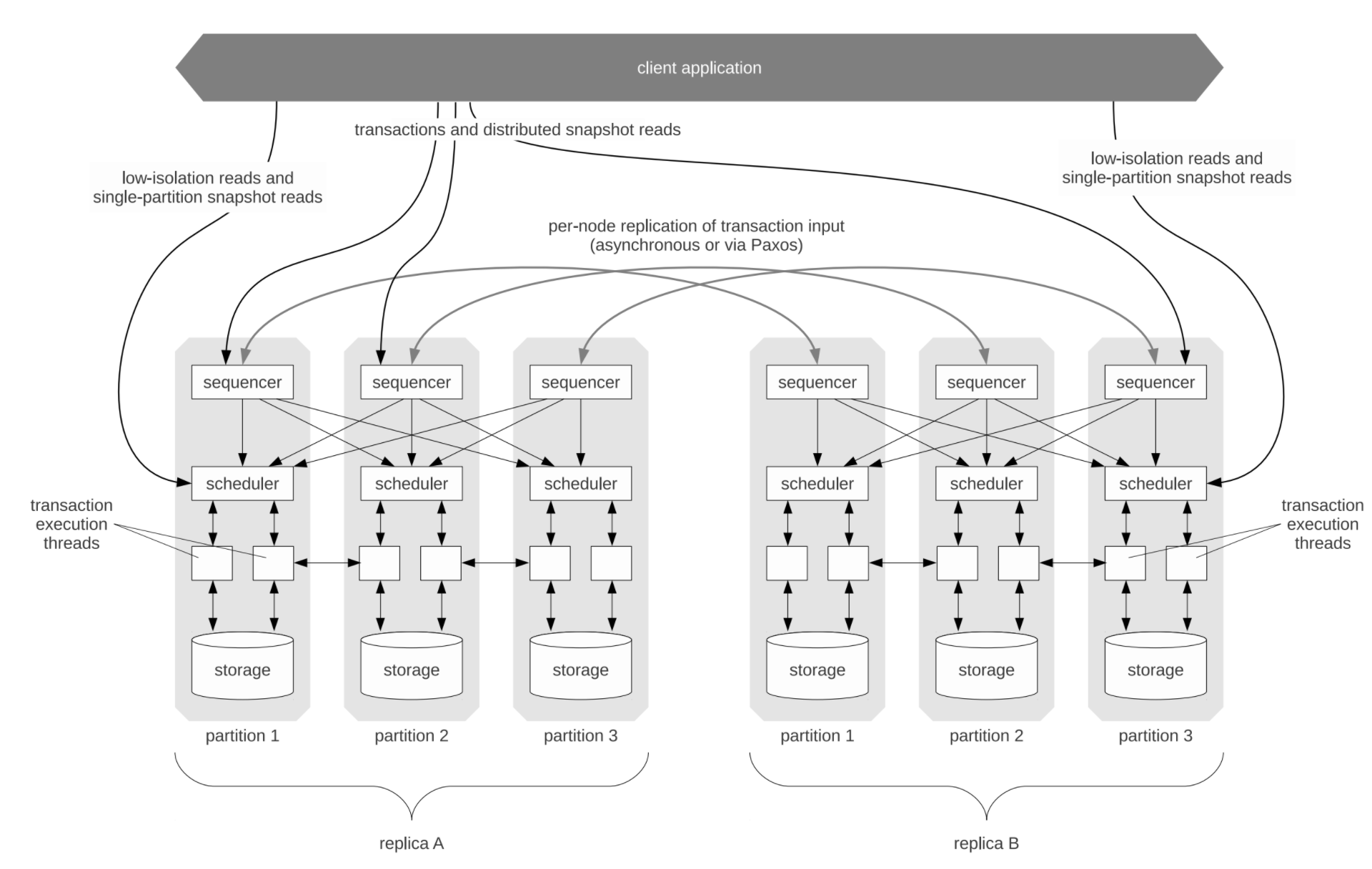
Calvin主要分为三个模块:
-
Sequencer。
- 拦截所有输入事务,按照10ms batch形式 分配事务batch_id。Sequencer集群采用RoundRobin分配事务请求的形式,在给事务定序这点上避免了对单点分配器或分布式时钟的依赖。
- 同时会将收到的事务和分配的epoch等信息进行logging和replicating。(这一点简单理解为sequence自身也是一个小型分布式存储,因此需要WAL和副本间同步数据)
-
Scheduler。包含一个logical LockManager,用于冲突检测。从而在保证 Sequencer 指定的顺序下,尽可能的允许多个事务并发的执行。
-
Storage。数据存储,可插拔,只要有办法支持通用存储读写接口的存储引擎都可以功能支持。
三个模块角色均可以scale out。
Sequencer
10ms的batch听上去似乎也涉及sequencer机器之间的时间同步问题,但是这里的batch_id在calvin的demo代码实现中是逻辑的,和物理时间不能直接对应。举个例子,先不考虑replica的存在,假设Sequencer集群是M个结点,结点id从0开始标号 (0,1,2 ...)。每个结点都会运行一个循环代码,当前batch的batch_id 计算为当前结点node_id+ N * M,N随着循环增加,故每个节点的batch_id是永远错开的。每次获取事务的时候获取一个本地开始时间,然后连续尝试获取client发送过来的事务 10ms后结束(或达到MAX_BATCH_SIZE结束)。如果有输入事务的话,就去进行副本同步。代码本身有点POC的感觉,但更多是表达这个10ms epoch机制是一个不需要依赖分布式时钟的定序机制。Sequencer的batch_id和事务在batch里的先后顺序基本就是这个事务串行调度顺序。
上述RoundRobin机制理论上需要Client去支持,但是Calvin demo代码未做实现。这里出现了一个很重要的问题,举个例子:
Sequencer1在t1时刻收到事务T1,Sequencer3在t3 (let t3 = t1 + 20ms)也收到事务T3。
由上文的batch_id生成机制可得,T3的batch_id和T1的batch_id是有空洞的。
怎么确定Sequencer2在t2时刻(t2 = t1 + 10ms)有没事务T2呢?
Sequencer2有可能有个事务T2,但是由于Sequencer2的CPU卡顿、网络分区等各种可能的原因,执行变慢,超过了10ms,导致下层scheduler先看到了T3。Scheduler虽然有办法可以串行化排序,但是无法解决空洞问题。这是Calvin协议的一个比较大的bug。这里个人考虑的一种解决办法是加个barrier机制,Sequencer_N只有收到barrier后才能serve请求,10ms后收集请求完毕,将当前实际有数据的latest_batch_id作为下一个barrier转发给Sequencer_N+1,Sequencer_N+1开始可以serve输入的请求。latest_batch_id可以帮助判断定序的空洞。
Sequencer自身还有副本机制做容灾。以上图架构总图为例,假设Sequencer分了3个分区(可以理解成上文的M),3副本备份。各个副本中的partition_N会构成一个复制组,复制组leader可能是组中任一结点,取决于复制协议。如图中示例,replicaA的part1, part2, replicaB的part3都是各自partition replica group的leader。复制协议显然很容易联想到最流行的paxos、raft等,论文代码实际实现采用了更简单的Zookeeper协议,虽然论文里强调了是paxos协议,但是既然ZAB都支持,其实这里理论上不强绑定具体的一致性协议。
同时为了提升复制性能,calvin还提供了一种异步复制机制。异步复制协议中,replica和partition leader关系是强绑定的,即会指定其中一整个replica为master replica,client的事务请求只发到master replica。在batch生成后,master replica会将batch转发给其他slave replicas,然后一起往下执行。recover的话就是找最后一个大家达成一致的完成的事务结点,后面的论文没有具体说,只是说是较复杂的容错处理,也没说master会不会重选之类的,大概是redo一遍剩下的(这个不完整的协议代码懒得看了)。总而言之,所谓异步复制的更像是一个为了先不引入paxos复杂度而搞的POC方案,唯一参考价值就是它的复制性能由于没有paxos的协议开销,论文性能数据看起来很好。这一块完全可以单独去做一个类似raft的变种去解决,可以参考阿里云数据库的PolarFS论文的ParallelRaft的思路。
Checkpoint机制的作用是防止宕机恢复时要做很久redo(指的是sequencer层记录的事务输入的日志,而不是数据修改的日志)。这里的挑战和所有分布式存储一样,如何在做checkpoint时对吞吐的影响最小。Calvin用的是基于Zigzag算法的一个改版,这里暂不介绍。
Scheduler
Scheduler层有一个角色LockManager,它也是分区持久化的,但是逻辑上对于分布式的scheduler是一个LockManager(尽管它自己是分布式的实现)。每个结点的scheduler只负责锁自己本地的数据,并严格遵循2PL (two-phase locking,注意不是2PC),但额外增加了一些确定性限制:
- 所有的事务一定要拿到 lock 之后才能开始执行
- 所有在事务里面的 lock 顺序也是跟全局事务顺序一致的,也就是说,如果两个事务 A 和 B 需要独占一个 lock,A 事务在 B 事务的前面,那么 A 一定比 B 先拿到 lock。这是通过使用一个单独的线程来串行顺序处理 lock 请求实现的。换句话说,LockManager 必须按照全局事务顺序来授权 lock。
Calvin采用Optimistic Lock Location Prediction (OLLP)来检测冲突,利用所谓“探测读”去生成当前事务的完整的读写集。探测读和实际读的区别在于探测读不一定需要读数据,尤其像有二级索引的数据,不需要做回表操作。探测读实际需要的是key和data version,用于在事务执行前的探测读和事务执行后的检查读去做版本比对。需注意,探测读发生在contention之外,即事务获取锁之前;并且探测读可以帮助生成read/write set。检查读是在锁内的。
举个例子,如果事务T有一个只读操作R(a),整个事务不会修改a。探测读的版本是10,T执行完后重新检查读a,发现版本变成了11,这说明a被其他事务改了,事务T不能提交,需要重启。而T之后的事务如果是有依赖的(或理解成对某些数据有冲突的),则因为事务T没用完锁,故还不能申请锁。OLLP会导致要读两遍,好处是如果没有冲突的,那先后两个事务可以并行执行;如果有冲突的,比如事务T0把a改成了11,之后的事务T需要读a,则T能够有办法察觉到并重启。事务已经apply了写操作,如何重启,Calvin没有说明。
集群内每个Scheduler结点都会看到事务T,且都会进行执行,但执行是分布式的。执行分为如下步骤:
- Read/write set analysis. 构建事务的key的读写集合。由于事务涉及数据可能在本地 ,也可能在远端,Calvin区分了两种结点角色:
- 主动参与者 active participants:包括事务数据在当前结点的读和写涉及的数据、以及远端的事务写涉及的数据。
- 被动参与者 passive participants:事务在该结点仅有只读数据存储。
- Perform local reads. 每个读本地节点上的事务数据(探测读)。
- Serve remote reads. 每个结点都将自己本地读的结果转发给所有的主动参与者。每个主动参与者都会可能做这个广播操作,这里可能会带来网络风暴。被动参与者在转发自己本地读的结果之后就不再往下执行。
- Collect remote read results. 主动参与者会在这个阶段收集别的结点发过来的数据,开始执行事务。
- Transaction logic execution and applying writes. 主动参与者的worker thread会过一遍事务操作流程,看哪些操作是本地写的将其apply。
Calvin的LockManager只支持行级锁,没办法锁ranges of keys,不能解决幻读问题。论文表示《D.Lomet and M. F. Mokbel. Locking key ranges with unbundled transaction services. VLDB, 2009.》中有解法,是future work。
Storage
Sequencer收到事务请求到实际storag发生IO之间会有一个storage idle的空闲时间。Calvin引入了一个人为延迟,在把事务交给scheduler之前,会先把IO请求发给所有相关的storage结点做预先加载数据到内存。这么做的好处是进一步降低事务持锁时间,因为没有预读的话,IO是会发生在contention之内的,而且IO经常是主要的开销时间。但是这个人为延迟的估计和这个内存态预取的机制引入,给系统增加了许多复杂性;同时内存限制、大事务适配、high contention下的数据换入换出等都是要考虑的问题。故,该机制的实际价值需要应用人员自行trade-off。
Calvin小结
看了整篇论文和Calvin的demo代码的一部分,确实感觉是个preliminary research,很多细节都很糙,包括但不限于没有任何Client的细节、上文提到的Sequencer的定序机制瑕疵、LockManager实现、OLLP和事务执行的具体关系(apply了local write怎么abort?)、read/write set的具体维护和大事务支持、不同size和不同规模的事务的contention性能更详细对比等。
但本文的价值在于提供了一个有一定框架的确定性事务的实现,指出了最大的目标是要减少contention foorprint,并且引入了OLLP探测读机制的思路。与传统悲观事务相比,就是看contention的减少。与乐观事务相比,在低竞争的情况下肯定是乐观性能要好;但是在高竞争的情况下,确定性定序的存在使得重试成本是确定的,所以Calvin反而更有优势。
DOCC (Deterministic and Optimistic Concurrency Control )
Ref: 《Optimistic Transaction Processing in Deterministic Database》
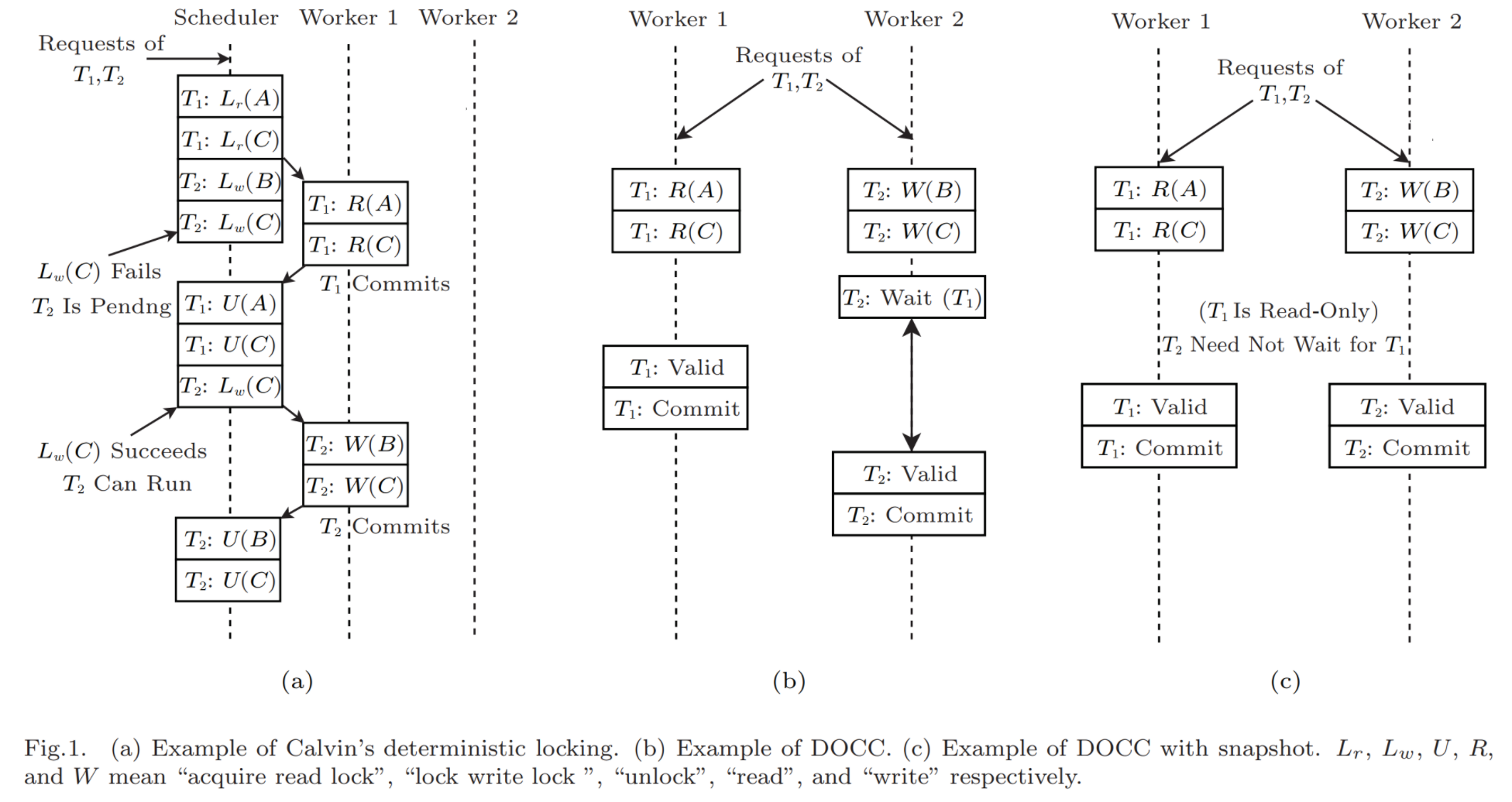
DOCC对Calvin做了进一步的性能优化以及Snapshot Isolation隔离级别的降级支持。论文做了个测试,多核环境单节点上CPU到4core以上,Calvin的事务吞吐性能便不再增加,这是由于Calvin的串行化调度机制决定的。Calvin OLLP机制中,事务持锁区间包括了事务执行和检查读(DOCC称之为Valid阶段)。DOCC通过把原来的执行拆成Execution和Commit两个阶段,从而让大头的Execution能够并行执行,有机会利用起多核优势。这里就引出了DOCC的最主要的方法概括:Enforcing the Deterministic Order Lazily 。
DOCC执行分为了4个阶段:
- Execution phase executes transactions optimisticly and tracks necessary record metadata.
- Waiting phase stalls transaction validation until its dependent transaction has committed.
- Validation phase validates the execution result and aborts the transaction upon the failure of validation.
- Commit phase commits the execution result and sets the transaction state to Committed.

整个算法伪代码也很好理解,为了Execution能达到并行,必然是写数据要存放到另一个位置,DOCC是采用了buf存储。这个buf在大事务下也可以做成持久化缓存的实现(有钱的如果能上个Optane盘之类的更好)。由于Execution阶段并行了,所以依赖事务保序的操作就交给了Wait阶段,等待前继有依赖的事务完成。Valid阶段只看read_set即可,因为反正write_set都会覆盖前面的事务的同一个record的数据,所以没必要看。最后Commit阶段是严格按照依赖拓扑提交的。Wait阶段这里又引入了一个优化,如果running的Tdep都是只读事务的话,那接下来T肯定不会有数据变化,可以直接跳过Wait进入Valid。这就是论文Approach一节的第二点:Avoiding Read-Only Transactions Blocking the Execution。
实际上到这里DOCC已经对Calvin做完了优化,但是论文并没有对其做测试。论文更主要是想提出 DOCC with snapshot(即上图的c流程)。Calvin论文本身在没有提出解决lock ranges of keys的方案下,本质是个Repeatable Read隔离级别,还没达到可串行化。DOCC因此也干脆提出了个Snapshot Isolation隔离级别的方案,虽然导致了write skew,但实现性能比原版更好。SI实现需要底层存储有多版本读写的能力。

事务在重试的时候也会阻塞执行pipeline,毕竟可能后面的事务是依赖当前事务的。为了进一步减少重试带来的阻塞开销,DOCC提出了一个retry的prefetch机制。由于乐观控制的第一次执行是完整执行的,所以数据在第一次执行已经全部读了一遍;retry的时候就尽可能复用第一次读的数据,防止二次的磁盘读取开销,算法如下图Algorithm 3。PlaceHolder存储着第一次访问的数据的指针,DOCC采用了一个内存态的索引(i.e. B-Tree)去维护key到placeholder的映射。当前key数据有更新的话,则会在placeholder上拉链表存下不同版本,记录的操作以append only的形式追加到对应key的链表后。因此删除也不是物理删除,是append了一个特殊placeholder去标记,以防数据物理删除引起的访问不一致问题。引入了append only的机制,必然就会有伴随的GC机制。GC有两种:全局定时扫描 and 读时清理。读时清理就是处理某个key的placeholder的时候,顺便判断下有没过期的数据并进行清理,这对一些hot keys的快速清理有较大帮助。


DOCC的paper的价值在于:
- 给出了Calvin OLLP Validation的更多细节,进一步优化了Calvin的性能
- 基于Calvin提出了一种快照隔离级别的降级实现方式,并且性能相比Calvin做到了进一步提高。
Fauna Distributed Transaction Protocol
Ref: https://fauna.com/blog/consistency-without-clocks-faunadb-transaction-protocol
Fauna号称是一个不依赖分布式时钟的deterministic分布式事务协议,inspired by Calvin。
事务并发输入时,Fauna和Calvin的Sequencer一样,有个全局的分布式日志服务(Raft impl)来定序。Fauna提出了一个 Fauna Time,实际上就是一个LogicalTime,和物理时间只是没有任何保证的大致模糊对应。由于是多版本存储的,Fauna Time起到了版本的作用,同时也作为事务id。因此,在定序日志里的任意一点的Fauna Time时刻,都能获取一致的快照。
在FaunaDB中,数据在机器之间进行分区和复制。每个分区包含多个记录(行),每个记录可能有许多与之关联的版本。每个版本都单独存储,并使用编写该版本的事务标识符进行标记。当FaunaDB事务需要读取数据时,它会选择快照并根据选择的快照读取正确的版本。(但是原文并没有提到如何清理过期数据)
事务流程如下:
- 接收到副本的结点会成为 coordinator,事务会在coordinator上执行。
- coordinator采用最近的一个可读的Fauna Time作为 snapshot read point,向同一副本 (同一副本地理距离近,时延低)的其他分区机器以快照读形式请求事务必要的数据。其实可以理解为此时就是一个最新读latest read。
- coordinator执行事务,但是写的数据会写到本地缓冲(类似DOCC的buf),不会实际修改数据。
- 开始提交到分布式日志中定序,同时冲突检测也发生在这一步。冲突检测和之前的检查读或DOCC的Valid是一样思路,重新读一遍最新数据,与前面步骤2的数据对比,如果发现版本被更新了则事务abort并重做。
- 提交阶段:每个副本会读取分布式事务日志,将成功提交的事务的缓冲数据应用到物理存储中。
Fauna的一个重要特点是对跨地理复制的支持,各个副本都可以个对外提供服务。跨地理分布式一致性的保证在于分布式日志,那个是全局唯一的。也就是说事务一旦提交进日志,所有副本要么看到最新FaunaTime,要么在后续事务处理中会识别出来并abort。这个分布式的Raft实现显然对于事务提交来说是个两阶段的过程,第一阶段会记录准备提交日志,这时候raft log顺序相当于给事务定序了,这也是原文所提的一轮共识的过程;第二阶段决定在冲突检测后决定commit log是COMMIT还是ABORT。
Fauna没有完整开源,也还没发论文,所以很多细节还未知。至少看下来就有几个问题:
- Fauna的定序是发生在提交阶段,也就是说此时冲突的那个事务还没进到序列里,假如不断地有冲突事务请求进来,当前abort的事务可能会反复重试失败,出现饿死。
- 非coordinator的副本独立提交的缓冲数据哪来的?