1. History
有些理论会把图论的起源追溯到16世纪的哥尼斯堡七桥问题。随着人类、社会、科技发展,从某些社群人物关系、到电力网络、到信息爆炸的互联网连接、到庞大的社交网络,图规模越来越巨大和复杂,尤其是社交网络的发展更使得关系连接变成一个非常重要的因素。传统关系理论更注重实体本身,关系只是实体的一个附庸,而在图理论里,关系和实体(边和点)起到一样重要的作用,没有关系的点无法构成有意义的图。
2. 图算法基础
基础算法
- 图论搜索 (DFS, BFS 及相关衍生或优化的算法)
- 最短路算法
- Dijkstra SPFA等单源最短路 (衍生的含次短路或K短路)
- 传递闭包 / Floyd
- 含负权值最短路
- 最小生成树
- 连通分量
- 强连通分量 : 在实际运用在一般用于图的分割,从而使得一些图算法有机会并行计算 (加速作用)
- 网络流(一般用于运筹学,比如物流运输领域等)
- 大图下的启发式算法
- RandomWalk
- 剪枝
应用算法
-
Centrality 中心度,用于评估点在网络中的重要程度,以下不同的衡量方法在不同的应用场景适用。
-
Degree centrality: Number of connections
-
Betweeness centrality: 中介中心性指的是一个结点担任其它两个结点之间最短路的桥梁的次数。一个结点充当“中介”的次数越高,它的中介中心度就越大。可以用一个结点承担最短路桥梁的次数除以所有的路径数量来计算。
-
Closeness centrality: 接近中心性需要考量每个结点到其它结点的最短路的平均长度。也就是说,对于一个结点而言,它距离其它结点越近,那么它的中心度越高。一般来说,那种需要让尽可能多的人使用的设施,它的接近中心度一般是比较高的。
-
PageRank : PageRank值的计算基于以下两个假设:
1:数量假设,如果越多的网页指向A,即A的入链数量越多,则该网页越重要;
2:质量假设,如果指向A的网页质量越高,则A越重要,即权重因素不同。
PR的相关资料很多,不赘述。
-
-
Community detection 社群探测。用于在一个复杂关系网络中探测出不同的群体。社群分为重叠型和非重叠性,重叠型的由于一个节点可能被分到多个社群中,问题更为复杂。
非重叠型社群探测方面学术界已有较成熟的研究。Mark Newman和 GirVan(2002)最早提出了网络中社群的概念,并在同一篇论文中提出了著名的GN算法。Newman(2006)后来又对GN算法中的Q值做了进一步系统化地叙述和定义,提出了网络中的模块度Modularity的概念。但GN算法是最原始的算法,性能较低,以学术界流行的igraph网络研究科研软件为代表的应用,在社群探测算法方面主要推荐了FastUnfolding、FastGreedy等基于贪心思想的算法、基于随机行走的WalkTrap。上述算法在应用中实现相对较为简单,但在非重叠型社群中效果较好。
FastGreedy算法由Aaron Clauset和M. E. J. Newman(2004)提出以解决快速社群探测问题,正如其名,这是一种贪心算法,核心思想是计算每次迭代的分区的模块度差,取模块度差增长最大的合并。该算法最开始把每个节点当作一个社群,然后选取合并后模块度差最大的两个社群进行合并,直到当前分区再也找不到可以使当前模块度增大的社群合并为止。寻找两个社群合并的模块度差是个非常耗时的步骤,朴素的搜索很容易会使算法退化到四阶的复杂度。FastGreedy算法做了些剪枝优化,并且使用了堆来维护模块度差的变化情况以及排序。
FastUnfolding算法由Vincent D. Blondel(2008)提出的一种近乎线性时间复杂度的社群探测算法,与FastGreedy算法一样是自底向上的层次性社群探测算法。该算法最开始把每个节点当作一个社群,然后尝试将社群内的某个节点移到另一个社群内,寻找节点移动后模块度最大的移动作为该次迭代的实际移动,重复如上移动步骤直至再也没有可使模块度增值的移动为止。该算法在稀疏图上近乎线性时间复杂度。
WalkTrap算法由P. Pons(2006)提出。该算法基于类似Google PageRank的随机游走思想,认为网络图中的随机游走会陷入到节点连接密集的部分,这连接密集的部分则可被认为是社群。该算法最开始把每个节点当作一个社群,然后计算社群之间的距离,选择距离最小的两个社群进行合并,得到新社群后重复以上计算距离和选择社群合并的步骤,直至最后只合并成一个社群。最后从所有的n次的分区中选取模块度Q值最大的一次作为最后的社群划分结果。其随机游走的思想与步长体现在节点与节点、节点与社群以及社群与社群之间距离的计算中。
- 社群稳定度衡量:
- Triangle count
- Clustering coefficient
- 社群稳定度衡量:
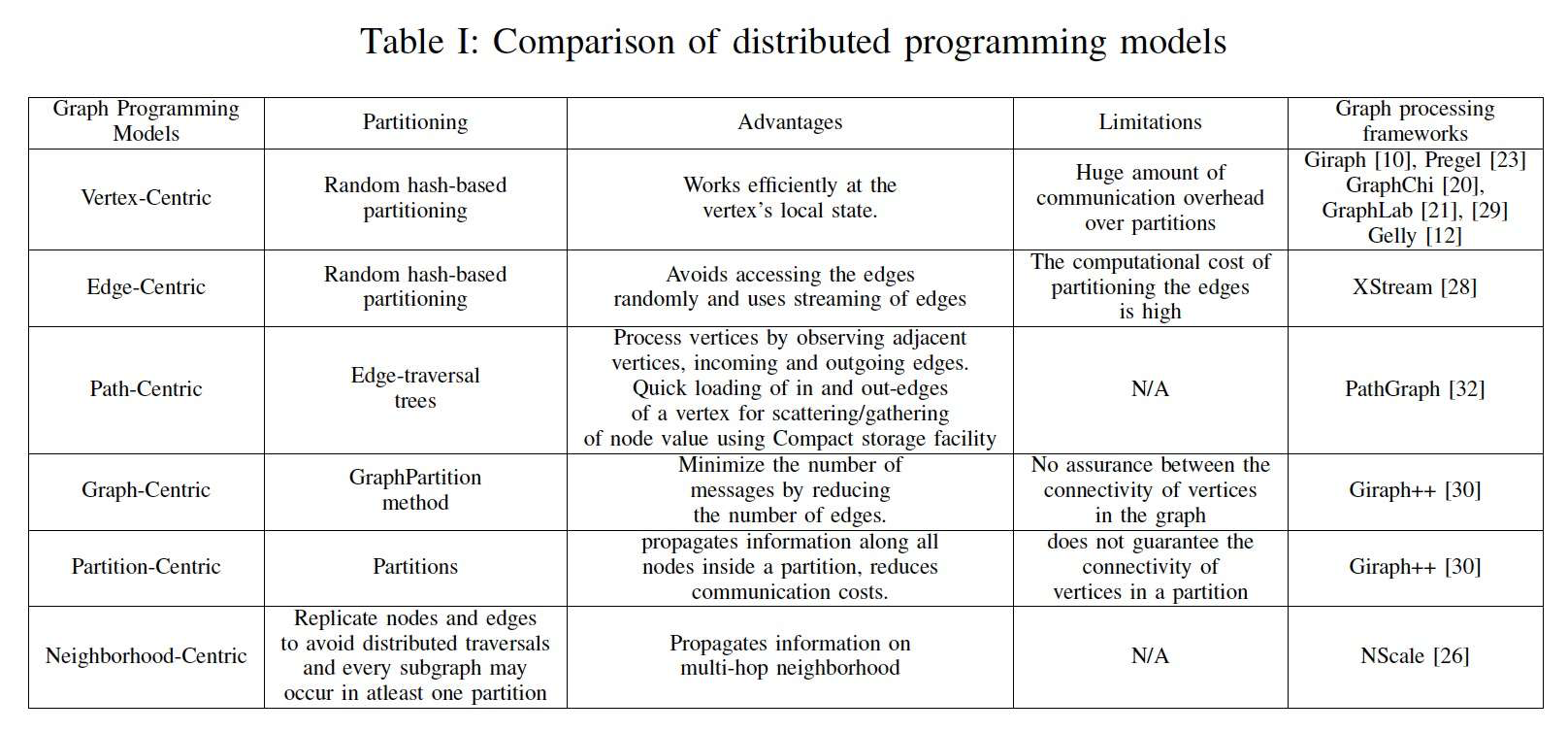
3. 图编程模型
ref: The Taxonomy of Distributed Graph Analytics
- Vertex centric: 以Google Pregel为典型的图数据库都采用这种以点为中心的模型。Think like a vertex, 一个点只看到自己和邻居(one hop)的信息。如果更远的信息传递需通过迭代实现。
- Edge centric:边中心类似点中心,只不过是Think like a edge.
- Path centric
- Partition centric
- Neighborhood centric
- Graph centric