前两天老师给我们讲解了BM25算法,其中包括由来解释,以及算法推导,这里我再将其整理,这里我不讲解之前的BIM模型,大家有兴趣可以自行了解。
Okapi BM25:一个非二值的模型
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。
举个例子:我们查询关键词red apple ,将其分词为red 和apple,我们在我们的1000个文档中分别索引这两个词,但是我们发现red的似乎经常出现,然而apple出现频率不高,那我们将这一千个文档进行得分排序,如果某个文档中red出现的次数很高,而apple出现次数很少,安装普通的得分排序的话(出现一次算一分)那我们red出现越多,它的分数就会越高,但是这却违背了我们所需要,因为我们检索的是red apple,所以,BM25就是来消除这种相关性不高的问题,即为我们所查询的词有一个权值比重,即为idf(这里我们后面会讲解)。
**1.BM25模型**
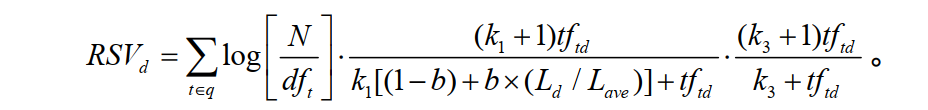
其实,这个公式不难理解,他只有三个部分
1.计算单词权重: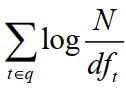
2.单词和文档的相关度: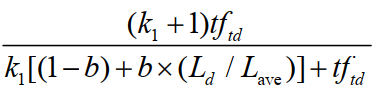
3.单词和query(关键词)的相关性: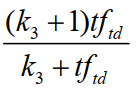
Okapi BM25:一个非二值的模型
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。
举个例子:我们查询关键词red apple ,将其分词为red 和apple,我们在我们的1000个文档中分别索引这两个词,但是我们发现red的似乎经常出现,然而apple出现频率不高,那我们将这一千个文档进行得分排序,如果某个文档中red出现的次数很高,而apple出现次数很少,安装普通的得分排序的话(出现一次算一分)那我们red出现越多,它的分数就会越高,但是这却违背了我们所需要,因为我们检索的是red apple,所以,BM25就是来消除这种相关性不高的问题,即为我们所查询的词有一个权值比重,即为idf(这里我们后面会讲解)。
**1.BM25模型**
其实,这个公式不难理解,他只有三个部分
1.计算单词权重:
2.单词和文档的相关度:
3.单词和query(关键词)的相关性:
**2.idf解释(单词权重计算)**
在上面我们已经看到了公式,但是还不是很理解是什么意思,所以这里我们慢慢理解体会:
N:是所有的文档数目.
dft:是我们的关键词通过倒排算法得出的包含t的文档数目(即为上述例子中,red 在1000个文档中出现的文档次数)
例如,我们在1000个文档中出现red的次数为10,那么**N/dft**=100,即可算出他的权重。
**3.tf解释(单词和文档相关度)**
其实,BM25最主要的方面在于 idf*tf,就是查询词的权重*查询词和文档的相关性。
tftd:tftd 是词项 t 在文档 d 中的权重。
Ld 和 Lave :分别是文档 d 的长度及整个文档集中文档的平均长度。
k1:是一个取正值的调优参数,用于对文档中的词项频率进行缩放控制。如果 k 1 取 0,则相当于不考虑词频,如果 k 1取较大的值,那么对应于使用原始词项频率。
b :是另外一个调节参数 (0≤ b≤ 1),决定文档长度的缩放程度:b = 1 表示基于文档长度对词项权重进行完全的缩放,b = 0 表示归一化时不考虑文档长度因素。
**4.单词和query(关键词)的相关性解释**
tftq:是词项t在查询q中的权重。
k3: 是另一个取正值的调优参数,用于对查询中的词项tq 频率进行缩放控制。
在上面我们已经看到了公式,但是还不是很理解是什么意思,所以这里我们慢慢理解体会:
N:是所有的文档数目.
dft:是我们的关键词通过倒排算法得出的包含t的文档数目(即为上述例子中,red 在1000个文档中出现的文档次数)
例如,我们在1000个文档中出现red的次数为10,那么**N/dft**=100,即可算出他的权重。
**3.tf解释(单词和文档相关度)**
其实,BM25最主要的方面在于 idf*tf,就是查询词的权重*查询词和文档的相关性。
tftd:tftd 是词项 t 在文档 d 中的权重。
Ld 和 Lave :分别是文档 d 的长度及整个文档集中文档的平均长度。
k1:是一个取正值的调优参数,用于对文档中的词项频率进行缩放控制。如果 k 1 取 0,则相当于不考虑词频,如果 k 1取较大的值,那么对应于使用原始词项频率。
b :是另外一个调节参数 (0≤ b≤ 1),决定文档长度的缩放程度:b = 1 表示基于文档长度对词项权重进行完全的缩放,b = 0 表示归一化时不考虑文档长度因素。
**4.单词和query(关键词)的相关性解释**
tftq:是词项t在查询q中的权重。
k3: 是另一个取正值的调优参数,用于对查询中的词项tq 频率进行缩放控制。
下面是调用AP90跑出来的数据结果(BM25):
同学们可以先了解BIM模型,这是一个较为简单的模型,BM25在很多地方都可以用到。