首先还原listagg聚合之后出现重复数据的现象,打开plsql,执行如下sql:
1 select t.department_name depname, 2 t.department_key, 3 listagg(t.class_key, ',') within group(order by t.class_key) as class_keys 4 from V_YDXG_TEACHER_KNSRDGL t 5 where 1 = 1 6 group by t.department_key, t.department_name
运行结果:

如图,listagg聚合之后很多重复数据,下面讲解如何解决重复数据问题。
【a】 第一种方法: 使用wm_concat() + distinct去重聚合
1 --第一种方法: 使用wm_concat() + distinct去重聚合 2 select t.department_name depname, 3 t.department_key, 4 wm_concat(distinct t.class_key) as class_keys 5 from V_YDXG_TEACHER_KNSRDGL t 6 where 1 = 1 7 group by t.department_key, t.department_name
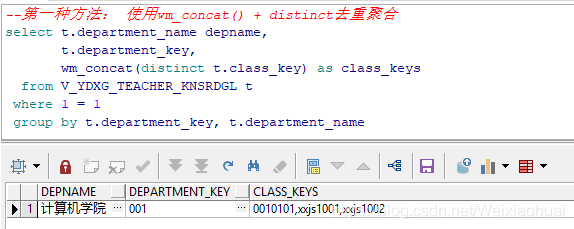
如上图,listagg聚合之后没有出现重复数据了。oracle官方不太推荐使用wm_concat()来进行聚合,能尽量使用listagg就使用listagg。
【b】第二种方法:使用正则替换方式去重(仅适用于oracle字符串大小比较小的情况)
1 --第二种方法:使用正则替换方式去重(仅适用于oracle字符串大小比较小的情况) 2 select t.department_name depname, 3 t.department_key, 4 regexp_replace(listagg(t.class_key, ',') within 5 group(order by t.class_key), 6 '([^,]+)(,1)*(,|$)', 7 '13') as class_keys 8 from V_YDXG_TEACHER_KNSRDGL t 9 group by t.department_key, t.department_name;

这种方式处理listagg去重问题如果拼接的字符串太长会报oracle超过最大长度的错误,只适用于数据量比较小的场景。
【c】第三种方法:先去重,再聚合(推荐使用)
1 --第三种方法:先去重,再聚合 2 select t.department_name depname, 3 t.department_key, 4 listagg(t.class_key, ',') within group(order by t.class_key) as class_keys 5 from (select distinct s.class_key, s.department_key, s.department_name 6 from V_YDXG_TEACHER_KNSRDGL s) t 7 group by t.department_key, t.department_name 8 9 --或者 10 select s.department_key, 11 s.department_name, 12 listagg(s.class_key, ',') within group(order by s.class_key) as class_keys 13 from (select t.department_key, 14 t.department_name, 15 t.class_key, 16 row_number() over(partition by t.department_key, t.department_name, t.class_key order by t.department_key, t.department_name) as rn 17 from V_YDXG_TEACHER_KNSRDGL t 18 order by t.department_key, t.department_name, t.class_key) s 19 where rn = 1 20 group by s.department_key, s.department_name; 21

推荐使用这种方式,先把重复数据去重之后再进行聚合处理。