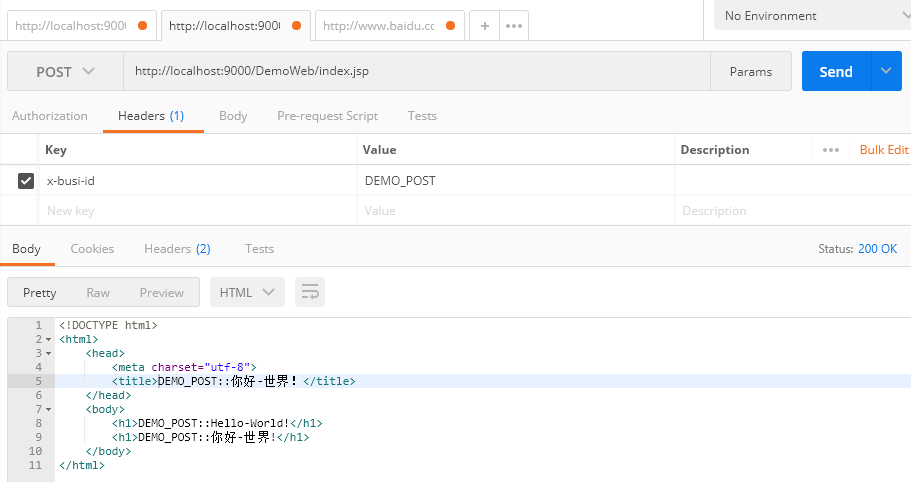
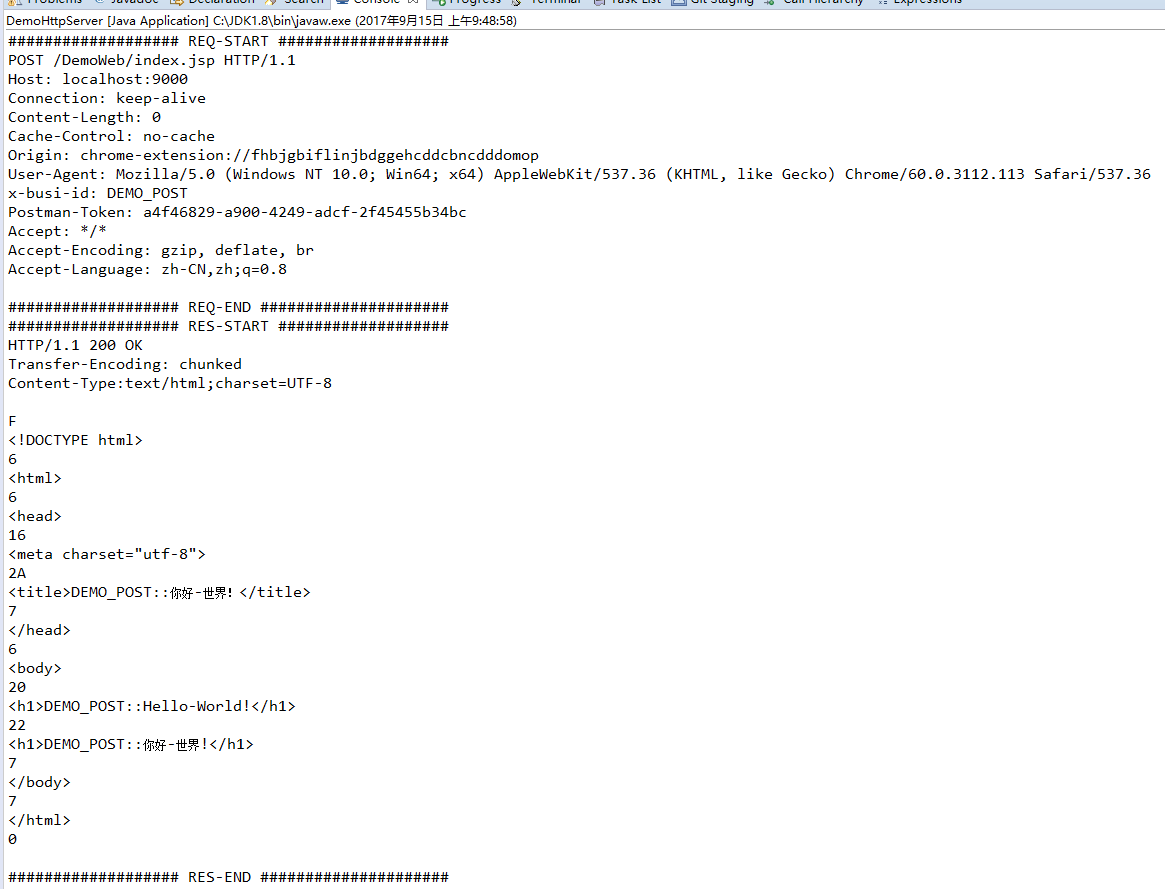
一、什么是chunked编码?
分块传输编码(Chunked transfer encoding)是只在HTTP协议1.1版本(HTTP/1.1)中提供的一种数据传送机制。以往HTTP的应答中数据是整个一起发送的,并在应答头里Content-Length字段标识了数据的长度,以便客户端知道应答消息的结束。
传统的Content-length解决方案:计算实体长度,并通过头部告诉对方。浏览器可以通过 Content-Length 的长度信息,判断出响应实体已结束
Content-length面临的问题:由于 Content-Length 字段必须真实反映实体长度,但是对于动态生成的内容来说,在内容创建完之前,长度是不可知的。
这时候要想准确获取长度,只能开一个足够大的 buffer,等内容全部生成好再计算。这样做一方面需要更大的内存开销,另一方面也会让客户端等更久。
我们需要一个新的机制:不依赖头部的长度信息,也能知道实体的边界——分块编码(Transfer-Encoding: chunked)。
对于动态生成的应答内容来说,内容在未生成完成前总长度是不可知的。因此需要先缓存生成的内容,再计算总长度填充到Content-Length,再发送整个数据内容。这样显得不太灵活,而使用分块编码则能得到改观。
分块传输编码允许服务器在最后发送消息头字段。例如在头中添加散列签名。对于压缩传输传输而言,可以一边压缩一边传输。
二、如何使用chunked编码
如果在http的消息头里Transfer-Encoding为chunked,那么就是使用此种编码方式。
接下来会发送数量未知的块,每一个块的开头都有一个十六进制的数,表明这个块的大小,然后接CRLF(" ")。然后是数据本身,数据结束后,还会有CRLF(" ")两个字符。有一些实现中,块大小的十六进制数和CRLF之间可以有空格。
最后一块的块大小为0,表明数据发送结束。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。
消息最后以CRLF结尾。
在头部加入 Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码。这时,报文中的实体需要改为用一系列分块来传输。
每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(
),也不包括分块数据结尾的 CRLF(
)。
最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
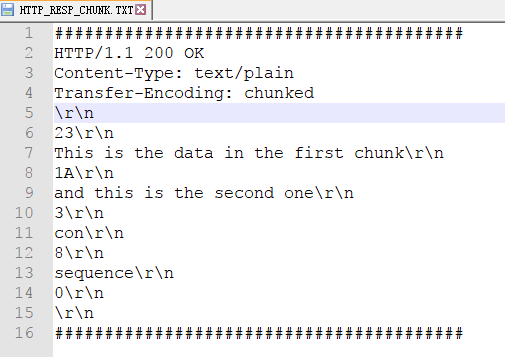
例:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
23
This is the data in the first chunk
1A
and this is the second one
3
con
8
sequence
0
Content-Encoding 和 Transfer-Encoding 二者经常会结合来用,其实就是针对 Transfer-Encoding 的分块再进行 Content-Encoding压缩。
三、响应报文
1、构建响应报文
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append("HTTP/1.1 200 OK
");
sb.append("Content-Type: text/plain
");
sb.append("Transfer-Encoding: chunked
");
sb.append("
");
// chunkData
{
String line = "Hello,";
byte[] lineBs = line.getBytes();
int iOct = lineBs.length;
String sHex = SocketUtil.octToHex(iOct);
sb.append(sHex).append("
");
sb.append(line).append("
");
System.out.println("[" + line + "],iOct=" + iOct + ",sHex=" + sHex);
}
// chunkData
{
String line = "中国";
byte[] lineBs = line.getBytes();
int iOct = lineBs.length;
String sHex = SocketUtil.octToHex(iOct);
sb.append(sHex).append("
");
sb.append(line).append("
");
System.out.println("[" + line + "],iOct=" + iOct + ",sHex=" + sHex);
}
// chunk-end:0
{
sb.append("0").append("
");
sb.append("
");
}
2、解析响应报文
ByteBuffer in = ByteBuffer.allocate(1024);
in.put(sb.toString().getBytes());
in.flip();
int start = in.position();
int end = in.limit();
ByteBuffer content = ByteBuffer.allocate(1024);
while (true) { // 封包循环
for (int i = start; i < end - 1; i++) {
if (in.get(i) == 0x0D && in.get(i + 1) == 0x0A) {
byte[] nums = new byte[i - start];
in.get(nums);
// 丢弃
in.get(new byte[2]);
int num = Integer.parseInt(new String(nums), 16);
byte[] strs = new byte[num];
in.get(strs);
content.put(strs);
// 丢弃
in.get(new byte[2]);
start = i + 4 + num;
break;
}
}
if (in.get(start) == 0x30 && in.get(start + 1) == 0x0D && in.get(start + 2) == 0x0A
&& in.get(start + 3) == 0x0D && in.get(start + 4) == 0x0A) {
content.flip();
in.get(new byte[5]);
break;
}
}
System.out.println(new String(content.array(), 0, content.limit()));
四、例子
1、get
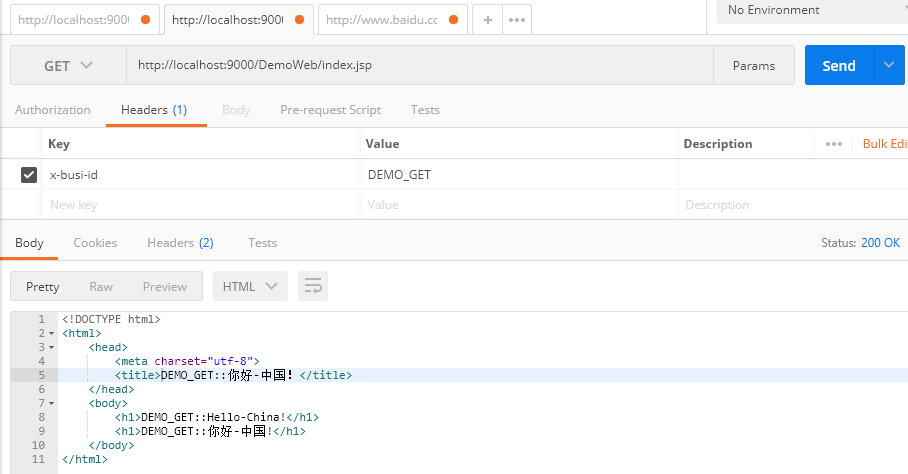

2、post