下面我们看一下图计算的简单示例:
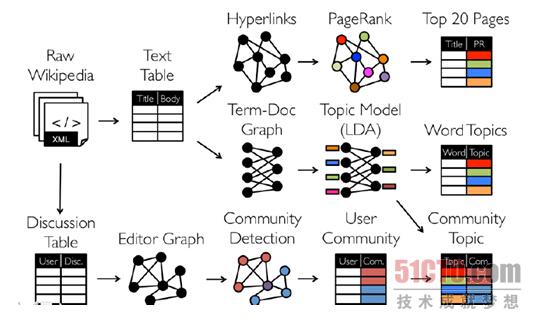
从图我们可以看出, 拿到Wikipedia的文档后,我们可以:
1、Wikipedia的文档 -- > table视图 -- >分析Hyperlinks超链接 -- > PageRank分析,
2、Wikipedia的文档 -- > table视图 -- >分析Term-Doc Graph -- > LDA -- > WordTopics
3、Wikipedia的文档 -- >Editor Graph -- > Community , 这个过程可以称之为Triangle Computation,这是计算三角形的一个算法,基于此,会发现一个社区,
从上面的分析中我们可以发现图计算有很多的做法和算法,同时也发现图和表格可以做互相的转换,不过并非所有的图计算框架都支持图与表格的互相转换。
Spark GraphX的优势在于能够把表格和图进行互相转换,这一点可以带来非常多的优势,
现在很多框架也在渐渐的往这方面发展,例如GraphLib已经实现了可以读取Graph中的Data,也可以读取Table中的Data,也可以读取Text总的data即文本中的内容等,
与此同时Spark GraphX基于Spark也为GraphX增添了额外的很多优势,例如和mllib、Spark SQL协作等。
当今图计算领域对图的计算大多数只考虑邻居节点的计算,也就是说一个节点计算的时候只会考虑其邻居节点,对于非邻居节点是不关心的,如下图所示:
目前基于图的并行计算框架已经有很多,比如来自Google的Pregel、来自Apache开源的图计算框架Giraph,以及我们最为著名的GraphLab,当然也包含HAMA,其中Pregel、HAMA、Giraph都是非常类似的,都是基于BSP模型,
BSP模型实现了SuperStep即超步,BSP首先进行本地计算,然后进行全局的通信,然后进行全局的Barrier;
BSP最大的好处是编程简单,而其问题在于一些情况下BSP运算的性能非常差,
因为我们有一个全局Barrier的存在,所以系统速度取决于最慢的计算,也就把木桶原理体现无遗,
另外一方面,很多现实生活中的网络是符合幂律分布的,也就是定点、边等分布式很不均匀,所以在这种情况下BSP的木桶原理导致了性能问题会得到很大的放大,
对这个问题的解决,以GraphLab为例,使用了一种异步的概念而没有全部的Barrier;
最后,不得不提的一点是在Spark Graphx中可以用极为简洁的代码非常方便的使用Pregel的API。
基于图的计算框架的共同特点是抽象出了一批API来简化基于图的编程,这往往比一般的data-parellel系统的性能高出很多倍。
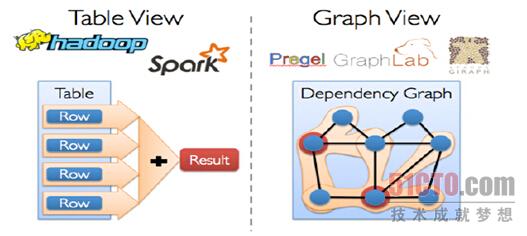
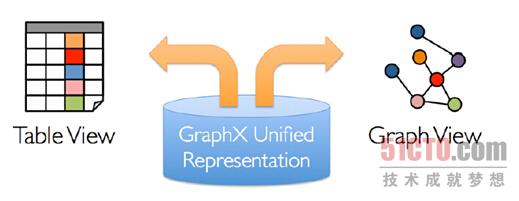
传统的图计算,往往需要不同的系统支持不同的View,
例如在Table View这种视图下可能需要Spark的支持或者Hadoop的支持,
而在Graph View这种视图下可能需要Pregel或者GraphLab的支持,
也就是把图和表分别在不同的系统中进行拉练处理,如下图所示:
上面所描述的图计算处理方式是传统的计算方式,当然现在除了Spark GraphX之外的图计算框架也在考虑这个问题;
不同系统带来的问题是之一是需要学习、部署和管理不同的系统,
例如要同时学习、部署和管理Hadoop、Hive、Spark、Giraph、GraphLab等:

大家都知道“Detail is evil”,如果我们能够用更少的框架解决更多的问题那是更好的。
其实最关键的问题还是效率问题,因为在不同的转换中间每步都要落地的话,数据转换和复制带来的开销也非常大,包括序列化带来的开销,同时中间结果和相应的结构无法重用,特别是一些结构性的东西,
譬如说顶点或者边的结构一直没有变,这种情况下结构内部的Structure是不需要改变的,而如果每次都重新构建的话,就算不变也无法重用,这回导致非常差的性能:
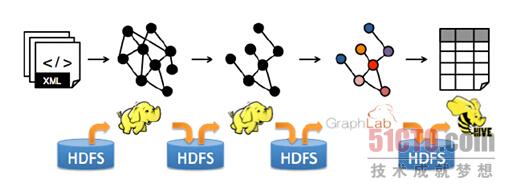
解决方案就是Spark GraphX,GarphX实现了Unified Representation,GraphX统一了Table View和Graph View,基于Spark可以非常轻松的做pipeline的操作:
如果和Spark SQL结合,我们可以用SQL语句来进行ETL,然后放入GraphX来处理,是非常方便的。
在Spark GraphX中的Graph其实是Property Graph,也就是说图的每个顶点和边都是有属性的,如下图所示:
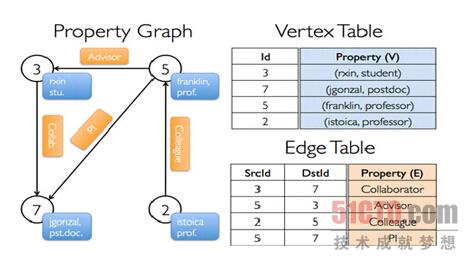
例如为3的顶点的名称为rxin,是学生stu.,5这个顶点是franlin,是一个prof.,5到3表明5是3的Advisor,上图中蓝色的表示的是相应顶点的Property,而黄色橙黄色部分表示的边的Property,边和顶点都是有ID的,对于顶点而言有自身的ID,而对于边来说有SourceID和DestinationID,即对于边而言会有两个ID来表达从哪个顶点出发到哪个顶点结束,来表明边的方向,这就是Property Graph的表示方法;如果把Property反映到表上的话,例如我们在Vertex Table中Id为的3的Property就是(rxin, student),而在Edge Table中3到7表明的边的Property是Collaborator的关系,2到5是Colleague的关系;更为重要的是Property Graph和Table之间是可以相互转换的,在GraphX中所有操作的基础是table operator和graph operator,,其继承自Spark中的RDD,都是针对集合进行操作。