最近同事问我js能不能读取本地文件;
想起以前看到js读取本地文件的文章,然后自己写了个demo。
ps:这有点像Java的IO流,但是又有差别。
首先我们定义一个input标签type="file"
1 jsReadFile:<input type="file" onchange="jsReadFiles(this.files)"/>
然后我们定义一个jsReadFiles的方法将文件作为参数;当上传文件的时候读取这个文件
1 //js 读取文件 2 function jsReadFiles(files) { 3 if (files.length) { 4 var file = files[0]; 5 var reader = new FileReader();//new一个FileReader实例 6 if (/text+/.test(file.type)) {//判断文件类型,是不是text类型 7 reader.onload = function() { 8 $('body').append('<pre>' + this.result + '</pre>'); 9 } 10 reader.readAsText(file); 11 } else if(/image+/.test(file.type)) {//判断文件是不是imgage类型 12 reader.onload = function() { 13 $('body').append('<img src="' + this.result + '"/>'); 14 } 15 reader.readAsDataURL(file); 16 } 17 } 18 }
这里用到了html5的FileReader这个对象来完成;
FileReader接口的方法:
readAsBinaryString file 将文件读取为二进制编码
readAsText file,[encoding] 将文件读取为文本,其中第二个参数是文本的编码方式,默认值为 UTF-8
readAsDataURL file 将文件读取为DataURL
abort (none) 中断读取操作(无论读取成功或失败,方法并不会返回读取结果,这一结果存储在result属性中)
相关事件:
onabort 中断
onerror 出错
onloadstart 开始
onprogress 正在读取
onload 成功读取
onloadend 读取完成,无论成功失败
文件一旦开始读取,无论成功或失败,实例的 result 属性都会被填充。如果读取失败,则 result 的值为 null ,否则即是读取的结果。
如果读取文件过大的话fileReader允许分段读取文件;
var blob_file; if(file.webkitSlice) { //chrome blob_file= file.webkitSlice(start, end + 1, 'text/plain;charset=UTF-8'); } else if(file.mozSlice) { //Firefox blob_file= file.mozSlice(start, end + 1, 'text/plain;charset=UTF-8'); }
成功读取文件:

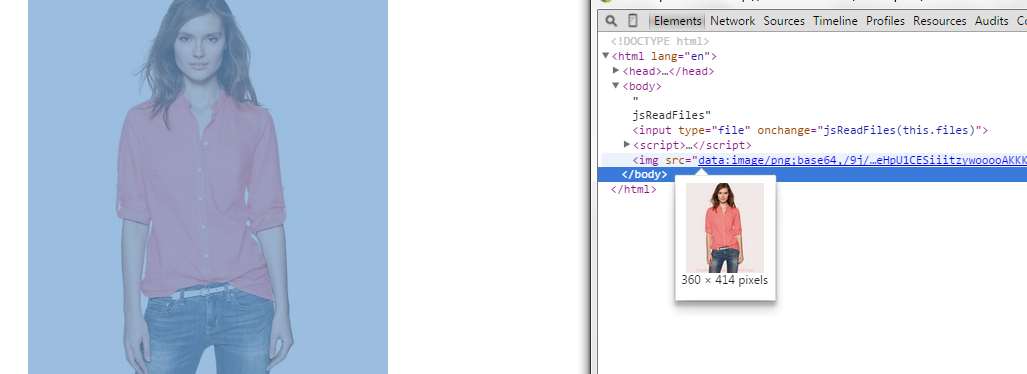
图片上传成功,只是图片路径变成了base64编码的形式。
顺便唠叨一下base64编码的优缺点:
优点:
1.减少了http请求。
2.没有跨域的问题。
3.直接放在路径里不需要清理缓存。
缺点:
1.IE6/7不支持(不过这个问题不大);
2.base64本质上是将图片以二进制的字母展示,字符量过大无形中增加了css/html文件的大小;
以上就是js读取文件的样例,有不对的地方欢迎大家吐槽!