0.PTA得分截图
图题目集总得分,请截图,截图中必须有自己名字。题目至少完成2/3,否则本次作业最高分5分。

1.本周学习总结(6分)
本次所有总结内容,请务必自己造一个图(不在教材或PPT出现的图),围绕这个图展开分析。建议:Python画图展示。图的结构尽量复杂,以便后续可以做最短路径、最小生成树的分析。
- 图的定义
顶点ii的出度:第ii行1的个数。顶点ii的入度,第ii列1的个数。
- 图的术语
- 顶点的度、入度、出度
顶点v的度:与v相关联的边的数目;
顶点v的出度:以v为起点有向边数;
顶点v的入度:以v为终点有向边数。
- 路径与回路
简单路径:序列中顶点不重复出现的路径
简单回路:序列中第一个顶点和最后一个顶点相同的路径
- 连通图(强连通图)
在无(有)向图中,若对任何两个顶点v、u都存在从v到u的路径,则称图G为连通图(强联通图)。
极大连通子图:该子图是G连通子图,将G的任何不在该子图的顶点加入,子图将不再连通。
极小连通子图:该子图是G的连通子图,在该子图中删除任何一条边,子图都将不再连通。
无向图G的极大连通子图称为G的连通分量。
有向图D的极大强连通子图称为D的强连通分量。
包含无向图G的所有顶点的极小连通子图称为G生成树。
若T是G的生成树当且仅当T满足:T是G的连通子图、T包含G的所有顶点、T中无回路。
图由顶点集V(G)和边集E(G)组成,记为G=(V,E)。其中E(G)是边的有限集合,边是顶点的无序对(无向图)或有序对(有向图)。
对有向图来说,E(G)是有向边(也称弧(Arc))的有限集合,弧是顶点的有序对,记为,v、w是顶点, v为弧尾(箭头根部),w为弧头(箭头处)。
对无向图来说,E(G)是边的有限集合,边是顶点的无序对,记为(v, w)或者(w, v),并且(v, w)=(w,v)。
1.1 图的存储结构
1.1.1 邻接矩阵(不用PPT上的图)
造一个图,展示其对应邻接矩阵
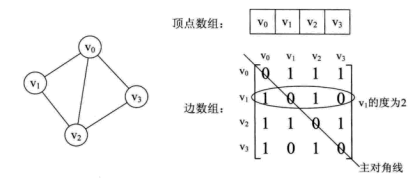
假定图中顶点数为v,邻接矩阵通过长、宽都为v的二维数组实现,若稀疏图(图中边的数目较少)通过邻接矩阵,会浪费很多内存空间。
- 邻接矩阵的结构体定义
typedef struct
{ int edges[MAXV][MAXV]; /*邻接矩阵*/
int n,e; /*顶点数、弧数*/
} MGraph;
- 建图函数
无向图
void CreateMGraph(MGraph& g, int n, int e)//建图
{
int i, j, a, b;
/*初始化*/
for (i = 1;i <= n;i++)
for (j = 1;j <= n;j++)
g.edges[i][j] = 0;
/*有边,赋值为1*/
for (i = 1;i <= e;i++)
{
cin >> a >> b;
//无向图,两顶点相互连边
g.edges[a][b] = 1;
g.edges[b][a] = 1;
}
g.n = n;
g.e = e;
}
有向图
void CreateMGraph(MGraph& g, int n, int e)//建图
{
int i, j, a, b;
/*初始化*/
for (i = 1;i <= n;i++)
for (j = 1;j <= n;j++)
g.edges[i][j] = 0;
/*有边,赋值为1*/
for (i = 1;i <= e;i++)
{
cin >> a >> b;
g.edges[a][b] = 1;
}
g.n = n;
g.e = e;
}
1.1.2 邻接表
造一个图,展示其对应邻接表(不用PPT上的图)
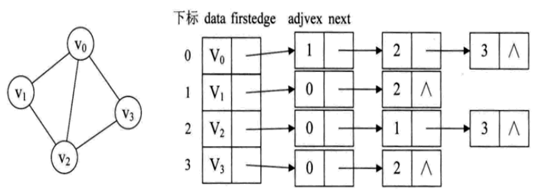
即用数组和链表相结合的方式存储图(类似于链表的数组)
- 邻接表的结构体定义
typedef struct ANode
{ int adjvex; //该边的终点编号
struct ANode *nextarc; //指向下一条边的指针
int info; //该边的相关信息,如权重
} ArcNode; //边表节点类型
typedef struct Vnode
{ Vertex data; //顶点信息
ArcNode *firstarc; //指向第一条边
} VNode; //邻接表头节点类型
typedef struct
{ AdjList adjlist; //邻接表
int n,e; //图中顶点数n和边数e
} AdjGraph; //邻接表类型
- 建图函数
无向图
void CreatAdjGraph(AdjGraph*& g, int n, int e)
{
int i, j, a, b;
ArcNode* p;
g = new AdjGraph;
g->adjlist = new VNode[n];
for (i = 0; i < n; i++)
g->adjlist[i].firstarc = NULL;
for (i = 0; i < e; i++)
{
cin >> a >> b;
p = new ArcNode;
p->adjvex = b;
p->nextarc = g->adjlist[a].firstarc;
g->adjlist[a].firstarc = p;
p = new ArcNode;
p->adjvex = a;
p->nextarc = g->adjlist[b].firstarc;
g->adjlist[b].firstarc = p;
}
g->n = n;
g->e = e;
}
有向图
void CreatAdjGraph(AdjGraph*& g, int n, int e)
{
int i, j, a, b;
ArcNode* p;
g = new AdjGraph;
g->adjlist = new VNode[n];
for (i = 0; i < n; i++)
g->adjlist[i].firstarc = NULL;
for (i = 0; i < e; i++)
{
cin >> a >> b;
p = new ArcNode;
p->adjvex = b;
p->nextarc = g->adjlist[a].firstarc;
g->adjlist[a].firstarc = p;
}
g->n = n;
g->e = e;
}
1.1.3 邻接矩阵和邻接表表示图的区别
各个结构适用什么图?时间复杂度的区别。
1、在邻接矩阵表示中,无向图的邻接矩阵是对称的。矩阵中第 i 行或 第 i 列有效元素个数之和就是顶点的读。
在有向图中 第 i 行有效元素个数之和是顶点的出度,第 i 列有效元素个数之和是顶点的入度。
2、在邻接表的表示中,无向图的同一条边在邻接表中存储的两次。如果想要知道顶点的读,只需要求出所对应链表的结点个数即可。
有向图中每条边在邻接表中只出现一此,求顶点的出度只需要遍历所对应链表即可。求出度则需要遍历其他顶点的链表。
3、邻接矩阵的优点是可以快速判断两个顶点之间是否存在边,可以快速添加边或者删除边。而其缺点是如果顶点之间的边比较少,会比较浪费空间。因为是一个 n∗nn∗n 的矩阵。
而邻接表的优点是节省空间,只存储实际存在的边。其缺点是关注顶点的度时,就可能需要遍历一个链表。还有一个缺点是,对于无向图,如果需要删除一条边,就需要在两个链表上查找并删除。
1.2.1 深度优先遍历
选上述的图,继续介绍深度优先遍历结果
- 深度遍历代码
邻接表
vois DFS(ALGraph *G,int v)
{
ArcNode *p;
visited[v]=1;
cout<<v;
p=G->adjlist[v].firstarc;
while(p!=NULL)
{
if(visited[p->adjvex]==0)
DFS(G,p->adjvex);
p=p->nextarc;
}
}
邻接矩阵
void DFS(MGraph g, int v)//深度遍历
{
int i;
visited[v] = 1;
if (flag==1)
cout << " " << v;
else
{
cout << v;
flag = 1;
}
for (i = 1; i <= g.n; i++)
if (g.edges[v][i] == 1 && visited[i]==0)
DFS(g, i);
}
- 深度遍历适用哪些问题的求解。(可百度搜索)
深度遍历适用于解决访问初始点v后再访问与定点v相邻的顶点w,再以w为初始点去访问w的相邻点。例如迷宫、六度空间等等。
1.2.2 广度优先遍历
选上述的图,继续介绍广度优先遍历结果
- 广度遍历代码
邻接表
void BFS(AdjGraph* G, int v) //v节点开始广度遍历
{
int temp,i;
ArcNode* p;
queue<int>q;
cout << v;
visited[v] = 1;
q.push(v);
while (!q.empty())
{
temp = q.front();
q.pop();
p = G->adjlist[temp].firstarc;
while (p != NULL)
{
if (visited[p->adjvex] == 0)
{
cout << " " << p->adjvex;
visited[p->adjvex] = 1;
q.push(p->adjvex);
}
p = p->nextarc;
}
}
}
邻接矩阵
void BFS(MGraph g, int v)//广度遍历
{
int t;
queue<int>q;
// if (visited[v] == 0)
// {
cout << v;
visited[v] = 1;
q.push(v);
// }
while (!q.empty())
{
t = q.front();
q.pop();
for (int j = 1; j <= g.n; j++)
{
if (g.edges[t][j] && visited[j] == 0)//
{
cout << " " << j;
visited[j] = 1;
q.push(j);
}
}
}
}
- 广度遍历适用哪些问题的求解。(可百度搜索)
通常用于求解无向图的最短路径问题,如迷宫最短路径
1.3 最小生成树
用自己语言描述什么是最小生成树。
有n个顶点的连通网可以建立不同的生成树,每一颗生成树都可以作为一个连通网,当构造这个连通网所花的权值最小时,搭建该连通网的生成树,就称为最小生成树。
1.3.1 Prim算法求最小生成树
- 步骤
1、初始化U={v},以v到其他顶点的所有边为候选边
2、重复以下步骤n-1次,使得其他n-1个顶点被加入到u中:
(1)从侯选边中挑选权值最小的边加入TE,设改边在V-U中的顶点式k,将k加入U中
(2)考察当前U-V中的所有顶点j,修改候选边,若(k,j)的权值小于原来顶点j关联的侯选边,则用(k,j)取代后者作为侯选边
基于上述图结构求Prim算法生成的最小生成树的边序列
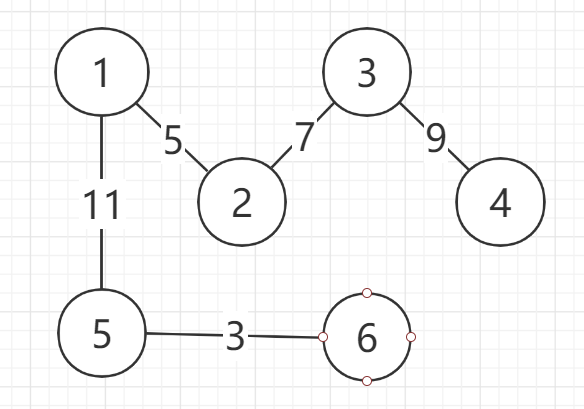
- Prim算法代码
void prim(MGraph g, int v)
{
int lowcost[MAXV], min, i, j, k = 0;
int closest[MAXV];
int sum = 0;
for(i = 1; i <= g.n; i++) //给数组lowcost[]和closest[]置初值
{
lowcost[i] = g.edges[v][i];
closest[i] = v;
}
lowcost[v] = 0; //顶点v已经加入树中
for (i = 1; i < g.n; i++) //找出(n-1)个顶点
{
min = 10000;
k = 0;
for (j = 1; j <= g.n; j++) //找出离树中节点最近的顶点k
{
if (lowcost[j] != 0 && lowcost[j] < min)
{
min = lowcost[j];
k = j; //k记录最近顶点的编号
}
}
if (k == 0) //不是连通图
{
cout << "-1" << endl;
return;
}
sum += min; //变量sum存储最小生成树中边的权值
lowcost[k] = 0; //顶点k已经加入树中
for (j = 1; j <= g.n; j++)
{
if (lowcost[j] != 0 && g.edges[k][j] < lowcost[j])
{
lowcost[j] = g.edges[k][j];
closest[j] = k;
}
}
}
cout << sum << endl;
}
时间复杂的为O(n的平方),其适用于边数较多的稠密图,其是通过比较边来找顶点,每次遍历找到一个顶点,与顶点个数无关。适用于邻接矩阵,需要调用到权值,找到特定顶点间的权值。
1.3.2 Kruskal算法求解最小生成树
基于上述图结构求Kruskal算法生成的最小生成树的边序列
- Kruskal算法代码
typedef struct {
int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
}Edge;
//改进的克鲁斯卡尔算法(使用了堆排序,并查集)
void Kruskal(AdjGraph* g)
{
int i,j,k,u1,v1,sn1,sn2;
UFSTree t[MAXSize]; //并查集,树结构
ArcNode* p;
Edge E[MAXSize];
k=1; // E数组的下标从1开始计
for(i = 0; i < g.n; i++)
{
p=g->adjlist[i].firstarc;
while(p!=NULL)
{
E[k].u=i;
E[k].v=p->adjvex;
E[k].w=p->weight;
k++;
p=p->nextarc;
}
}
HeapSort(E,g.e); //采用堆排序对E数组按权值递增排序
MAKE_SET(t,g.n); //初始化并查集树t
k=1; //k表示当前构造生成树的第几条边,初值为1
j=1; //E中边的下标,初值为1
while(k<g.n) //生成的边数为n-1
{
u1=E[j].u;
v1=E[j].v; //取一条边的头尾顶点编号u1和v1
sn1=FIND_SET(t,u1);
sn2=FIND_SET(t,v1); //分别得到两个顶点所属的集合编号
if(sn1!=sn2) //两顶点属不同集合
{
k++; //生成边数增1
UNION(t, u1, v1); //将u1和v1两个顶点合并
}
j++; //下一条边
}
}
如果给定的带权连通图G有n个顶点,e条边,在上述算法中,对边集E采用直接插入排序的时间复杂度为O(e)。while循环是在e条边中选取(n—1)条边,
而其中的for循环执行n次,因此 while循环的时间复杂度为O(n2+e2)。对于连通无向图,e≥(n—1),那么用Kruskal算法构造最小生成树的时间复杂度为O(e2)。
1.4 最短路径
1.4.1 Dijkstra算法求解最短路径
-
基于上述图结构,求解某个顶点到其他顶点最短路径。(结合dist数组、path数组求解)
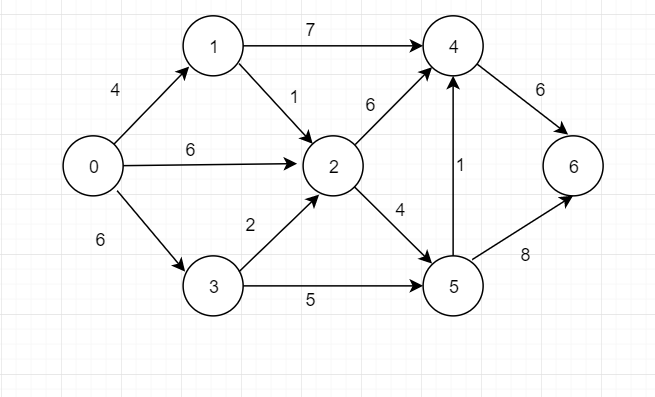

-
Dijkstra算法需要哪些辅助数据结构
<dist[]:记录当前顶点到对象顶点的当前最短路径长度
path[]:记录对应顶点的前驱顶点 -
Dijkstra算法(贪心算法)求解最优解问题:
void Dijkstra(MGraph g, int v)//源点v到其他顶点最短路径
{
int* S = new int[g.n];
int* dist = new int[g.n];
int* path = new int[g.n];
int i,j,k,MINdis;
//初始化各个数组
for (i = 0; i < g.n; i++)
{
S[i] = 0;
dist[i] = g.edges[v][i];//
//不需要进行分类,因为不存在边的权值已经初始化为INF
if (g.edges[v][i] < INF)
{
path[i] = v;
}
else
{
path[i] = -1;
}
}
S[v] = 1, dist[v] = 0, path[v] = 0;
for (i = 0; i < g.n-1; i++)
{
//根据dist中的距离从未选顶点中选择距离最小的纳入
MINdis = INF;
for (j = 0; j < g.n; j++)
{
if (S[j] == 0 && dist[j] < MINdis)
{
MINdis = dist[j];
k = j;
}
}
S[k] = 1;
//纳入新顶点后更新dist信息和path信息
for (j = 0; j < g.n; j++)
{
if (S[j] == 0)//针对还没被选中的顶点
{
if (g.edges[k][j] < INF //新纳的顶点到未被选中的顶点有边
&& dist[k] + g.edges[k][j] < dist[j])//源点到k的距离加上k到j的距离比当前的源点到j的距离短
{
dist[j] = dist[k] + g.edges[k][j];
path[j] = k;
}
}
}
}
}
- Dijkstra算法的时间复杂度,使用什么图结构,为什么。
Dijkstra算法的时间复杂度:单顶点时间复杂度为O(n2),对n个顶点时间复杂度为O(n3)。
使用邻接矩阵存储结构来存储,算法中需要直接获取边的权值,而邻接矩阵获取权值的时间复杂度低于邻接表存储结构。
1.4.2 Floyd算法求解最短路径 - Floyd算法解决什么问题?
适用范围:无负权回路即可,边权可正可负,运行一次算法即可求得任意两点间最短路。 - Floyd算法需要哪些辅助数据结构
二维数组A用于存放当前顶点之间的最短路径长度,即分量A[i][j]表示当前i->j的最短路径长度。 - Floyd算法优势,举例说明。
它能一次求得任何两个节点之间的最短路径,而Dijkstra算法只能求得以特定节点开始的最短路径。 - 最短路径算法还有其他算法,可以自行百度搜索,并和教材算法比较。
SPFA算法(Shortest Path Fast Algorithm的缩写)
int SPFA(int s, int t) {
int dist[maxn], inq[maxn];
for(int i = 0; i < n; i ++ ) {
dist[i] = inf, inq[i] = 0;
}
queue<int>que;
que.push(s), inq[s] = 1, dist[s] = 0;
while(!que.empty()) {
int now = que.front();
que.pop();
inq[now] = 0;
for(int i = first[now]; ~i; i = edge[i].next) { //每次拿出一个点开始松弛。
int to = edge[i].to, w = edge[i].w;
if(dist[to] > dist[now] + w) { //这个if看下面的图
dist[to] = dist[now] + w;
if(!inq[to]) { //松弛过的点dist变换了,可能影响其他的点。需要继续松弛
inq[to] = 1;
que.push(to);
}
}
}
}
return dist[t] == inf ? -1 : dist[t];
}
PFA也叫bellman ford的队列优化。但是bellman ford的复杂度比较高。SPFA的平均复杂度是O(n*log2n),复杂度不稳定,在稠密图(边多的图)跑的比dijkstra慢,稀疏图(边少的图)跑的比Dijkstra快。在完全图达到最坏的平方级复杂度
1.5 拓扑排序
- 找一个有向图,并求其对要的拓扑排序序列
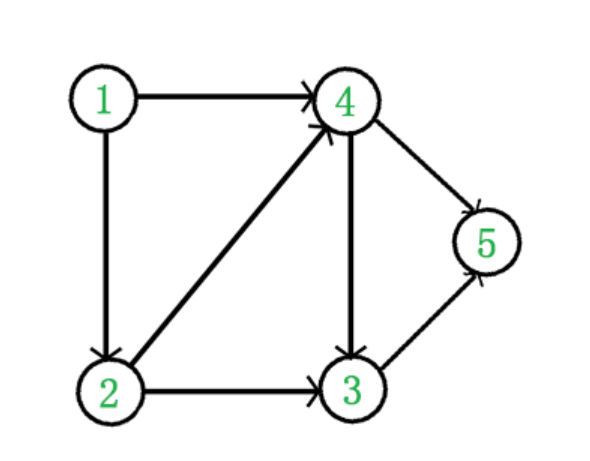
该有向图的拓扑序列为:12435 - 实现拓扑排序代码,结构体如何设计?
typedef struct//表头节点类型
{
vertex data;顶点信息
int count;存放顶点入度
ArcNode *firstarc;指向第一条弧
}VNode;
void TopSort(AdjGraph* G)
{
int i,j;
int St[MAXV],top = -1;
ArcNode* p;
for (i = 0; i < G->n; i++)
G->adjlist[i].count = 0;
for (i = 0; i < G->n; i++)
{
p = G->adjlist[i].firstarc;
while (p != NULL)
{
G->adjlist[p->adjvex].count++;
p = p->nextarc;
}
}
for (i = 0; i < G->n; i++)
if (G->adjlist[i].count == 0)
{
top++;
St[top] = i;
}
while (top > -1)
{
i = St[top]; top--;
printf("%d ", i);
p = G->adjlist[i].firstarc;
while (p != NULL)
{
j = p->adjvex;
G->adjlist[j].count--;
if (G->adjlist[j].count == 0)
{
top++;
St[top] = j;
}
p = p->nextarc;
}
}
}
- 如何用拓扑排序代码检查一个有向图是否有环路?
在排序后判断各点count是否为0
1.6 关键路径
- 什么叫AOE-网?
定义:在带权有向图中,以顶点表示事件,有向边表示活动,边上的权值表示完成该活动的开销,则称这种有向图为用边表示活动的网络,简称为AOE网(Activity On Edge Network) - 什么是关键路径概念?
AOV 网中从源点到汇点的最长路径的长度 - 什么是关键活动?
关键路径上的活动称为关键活动
2.PTA实验作业(4分)
2.1 六度空间(2分)
选一题,介绍伪代码,不要贴代码。请结合图形展开分析思路。
2.1.1 伪代码(贴代码,本题0分)
while (队不为空)
{
出队顶点V
遍历V的所有邻接点
{
找到没有遍历过的顶点,进队列
sum++;
}
如果在遍历的时候发现遍历的节点是这一层的最后一个
{
level++;
更新这层的最后一个
}
如果层数为6 //说明已经到了六层,剩下的就是不符合六度空间理论的顶点
返回我们记录下的sum
}
2.1.2 提交列表

2.1.3 本题知识点
广度优先遍历,图的创建
2.2 村村通或通信网络设计或旅游规划(2分)
2.2.1 伪代码(贴代码,本题0分)
void Dijkstra(MGraph g, int v)
{
初始化dist数组、s数组、pay数组,dist数组
遍历图中所有节点
for(i = 0; i < g.n; i++)
若s[i]! = 0,则数组找最短路径,顶点为u
s[u] = 1进s
for(i = 0; i < g.n; i++)
if(g.edges[u][j].len < INF && dist[u] + g.edges[u][j].len < dist[j])
则修正dist[j] = dist[u] + g.edges[u][j].len;
pay[j] = pay[u] + g.edges[u][j].pay;
else if(路径一样长但是花费更少)
则修正pay[j] = pay[u] + g.edges[u][j].pay;
2.2.2 提交列表
2.2.3 本题知识点
最小生成树的prim算法