文章目录
概述
基本推导和理论还是以看李航老师的《统计学习方法》为主。
各种算法的原理,推荐理解到可以手撕的程度。
以下为通过网络资源搜集整理的一些问题及答案,准备的有些仓促,没能记录所有资料的来源(侵删)
logistics公式及推导
https://download.csdn.net/download/yolohohohoho/10972162
LR为什么用sigmoid函数, 为什么不用其他函数?
逻辑回归模型基于不同于线性回归的、关于因变量y和自变量x之间关系的假设。特别的,这两种模型的区别可以在以下两个逻辑回归的特性中看出来:
- 逻辑回归的条件分布y|x是伯努利分布,而线性回归的是高斯分布,因为逻辑回归的因变量是二元变量(0或1)。
- 逻辑回归要预测的值是概率,因此要通过逻辑分布函数约束到(0,1)区间,因为逻辑回归预测的是某个输出值(0或1)的概率。
逻辑回归是广义线性回归的一个特例。在广义线性回归中,我们认为数据并不是只能服从正态分布,而可以是其他分布,只要他来自于指数族。如果y是二元变量,则很自然地认为他服从二项分布。我们不能简单地认为E[Y|X]=Xβ,所以我们在他外面加了一个变换——η(E[Y|X])=Xβ。 η(⋅)被称为link function。当y是二元变量时,η(⋅)就是logit,因为p(y|p)=exp{ylog(p/(1−p))+log(1−p)}。η§=log(p/(1−p)。
https://www.zhihu.com/question/35322351
之所以要选择canonical link function 是为了简便计算,使得所有GLM模型对参数的极大似然估计具有相同的形式(正则方程)。
这个函数有什么优点和缺点?
优点
- 输入范围是−∞→+∞−∞→+∞ ,而之于刚好为(0,1),正好满足概率分布为(0,1)的要求。我们用概率去描述分类器,自然比单纯的某个阈值要方便很多;
- 单调上升的函数,具有良好的连续性,不存在不连续点。
- 函数关于(0,0.5) 中心对称
缺点
- 幂运算相对耗时
- sigmoid 函数反向传播时,很容易就会出现梯度消失的情况
逻辑斯蒂回归怎么实现多分类?
- Softmax Regression
- K Binary Classifiers
Softmax vs k binary classifiers
This will depend on whether the four classes are mutually exclusive
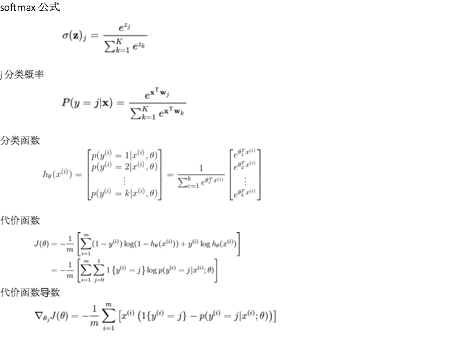
Softmax公式
逻辑回归估计参数时的目标函数,如果加上一个先验的服从高斯分布的假设,会是什么样?
相当于求最大后验概率
MAP与ML最大的不同在于p(参数)项,所以可以说MAP是正好可以解决ML缺乏先验知识的缺点,将先验知识加入后,优化损失函数。
其实p(参数)项正好起到了正则化的作用。如:如果假设p(参数)服从高斯分布,则相当于加了一个L2 norm;如果假设p(参数)服从拉普拉斯分布,则相当于加了一个L1 norm。
LR和SVM有什么区别?
-
相同点:
- 都是监督的分类算法
- 都是线性分类方法(LR也是可以加核函数)
- 都是判别模型
判别模型和生成模型是两个相对应的模型。
判别模型是直接生成一个表示P(Y|X)P(Y|X)或者Y=f(X)Y=f(X)的判别函数(或预测模型)
生成模型是先计算联合概率分布P(Y,X)P(Y,X)然后通过贝叶斯公式转化为条件概率。
SVM和LR,KNN,决策树都是判别模型,而朴素贝叶斯,隐马尔可夫模型是生成模型。
生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
-
不同点:
- LR的损失函数是cross entropy
- SVM的损失函数是最大化间隔距离
不同的loss function代表了不同的假设前提,也就代表了不同的分类原理
LR方法基于概率理论,假设样本为0或者1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值,或者从信息论的角度来看,其是让模型产生的分布P(Y|X)P(Y|X)尽可能接近训练数据的分布,相当于最小化KL距离(因为KL距离展开后,后一项为常数,剩下的一项就是cross entropy)。
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
所以SVM只考虑分类面上的点,而LR考虑所有点,SVM中,在支持向量之外添加减少任何点都对结果没有影响,而LR则是每一个点都会影响决策。
Linear SVM不直接依赖于数据分布,分类平面不受一类点影响
LR则是受所有数据点的影响,所以受数据本身分布影响的,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。
SVM不能产生概率,LR可以产生概率
LR本身就是基于概率的,所以它产生的结果代表了分成某一类的概率,而SVM则因为优化的目标不含有概率因素,所以其不能直接产生概率(虽然现有的工具包,可以让SVM产生概率,但是那不是SVM原本自身产生的,而是在SVM基础上建立了一个别的模型,当其要输出概率的时候,还是转化为LR)
SVM甚至是SVR本质上都不是概率模型,因为其基于的假设就不是关于概率的
SVM依赖于数据的测度,而LR则不受影响
因为SVM是基于距离的,而LR是基于概率的,所以LR是不受数据不同维度测度不同的影响,而SVM因为要最小化12||w||212||w||2所以其依赖于不同维度测度的不同,如果差别较大需要做normalization
当然如果LR要加上正则化时,也是需要normalization一下的
如果不归一化,各维特征的跨度差距很大,目标函数就会是“扁”的,在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路。
SVM会用核函数而LR一般不用核函数的原因
SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
而LR则每个点都需要两两计算核函数,计算量太过庞大。
LR和SVM在实际应用的区别
根据经验来看,对于小规模数据集,SVM的效果要好于LR,但是大数据中,SVM的计算复杂度受到限制,而LR因为训练简单,可以在线训练,所以经常会被大量采用。
libsvm和liblinear有什么区别?
http://blog.sina.com.cn/s/blog_5b29caf7010127vh.html
Logistics vs 随机森林 vs SVM
- 模型
- 损失函数
- 优缺点
- 应用场景
逻辑回归适用于处理接近线性可分的分类问题
如果边界是非线性的,并且能通过不断将特征空间切分为矩形来模拟,那么决策树是比逻辑回归更好的选择。
逻辑回归算法对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,不过如果要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征
逻辑回归的优点:
• 便利的观测样本概率分数;
• 已有工具的高效实现;
• 对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决;
• 逻辑回归广泛的应用于工业问题上(这一点很重要)。
逻辑回归的缺点:
• 当特征空间很大时,逻辑回归的性能不是很好;
• 不能很好地处理大量多类特征或变量;
• 对于非线性特征,需要进行转换;
• 依赖于全部的数据(个人觉得这并不是一个很严重的缺点)。
决策树的优点:
• 直观的决策规则
• 可以处理非线性特征
• 考虑了变量之间的相互作用
决策树的缺点:
• 训练集上的效果高度优于测试集,即过拟合[随机森林克服了此缺点]
• 没有将排名分数作为直接结果
随机森林优点
1、在当前的很多数据集上,相对其他算法有着很大的优势,表现良好
2、它能够处理很高维度(feature很多)的数据,并且不用做特征选择
3、在训练完后,它能够给出哪些feature比较重要
4、 在创建随机森林的时候,对generlization error使用的是无偏估计,模型泛化能力强
5、训练速度快,容易做成并行化方法,训练时树与树之间是相互独立的
6、 在训练过程中,能够检测到feature间的互相影响
7、 实现比较简单
8、 对于不平衡的数据集来说,它可以平衡误差。
1)每棵树都选择部分样本及部分特征,一定程度避免过拟合;
2)每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定;
对缺失值不敏感,如果有很大一部分的特征遗失,仍可以维持准确度
随机森林有out of bag,不需要单独换分交叉验证集
。
随机森林缺点:
1) 参数较复杂;
2) 模型训练和预测都比较慢。
SVM的优点:
• 能够处理大型特征空间
• 能够处理非线性特征之间的相互作用
• 无需依赖整个数据
SVM的缺点:
• 当观测样本很多时,效率并不是很高
• 有时候很难找到一个合适的核函数
为此,我试着编写一个简单的工作流,决定应该何时选择这三种算法,流程如下:
• 首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考;
• 然后试试决策树(随机森林)是否可以大幅度提升模型性能。即使你并没有把它当做最终模型,你也可以使用随机森林来移除噪声变量;
• 如果特征的数量和观测样本特别多,那么当资源和时间充足时,使用SVM不失为一种选择。