一、查找
重点掌握:二分查找!能够找到排序数组中的数字or统计某个数字出现的次数
哈希表和二叉排序树查找的重点在于数据结构而不是算法。
**1. 二分查找——O(logn)
1)适用于:已排序或者部分排序的数组
2)时间复杂度:O(logn)
3)算法思想:
- 分别设两个指针low、high指向数组的最小和最大数字
- 每次取mid = (low+hig)/2
- 如果list[mid] < target,说明目标数字在mid的右边:low = mid + 1
- 如果list[mid] > target,说明目标数字在mid的左边:high = mid -1
- 如果list[mid] = target:返回mid
4)实现:
def binary_search(list, target): low = 0 high = len(list) - 1 while(low < high): mid = int((low+high)/2) if(list[mid] < target): low = mid + 1 elif(list[mid] > target): high = mid else: result = True return mid return list[low] if list[low] == target else False list = [1, 2, 3, 4, 5] print(binary_search(list, 1))
题目8 旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,称之为数组的选入。输入一个递增排序的数组的一个排序,输出旋转数组的最小元素。例如:[3, 4, 5, 1, 2]为[1, 2, 3, 4, 5]的一个旋转。
def binary_search(list): low = 0 high = len(list) - 1 min = list[low] while(low < high): mid = int((low + high)/2) if(list[mid] > min): low = mid + 1 else: min = list[mid] # 注意边界条件!! if(min > list[high]): min = list[high] return min list = [2, 3, 4, 5, 6, 7, 8, 1] print(binary_search(list))
题目38 统计一个数字在排序数组中出现的次数。——O(logn)
例如输入排序数组[1, 2, 3, 3, 3, 3, 4, 5]和数字3,输出3出现的次数4。
思路:整个程序分为三个部分:
- 用递归的方法找到第一个k
- 用递归的方法找到最后一个k
- 调用前两个方法得到k的个数
def get_first_index(data, start, end, target): if(start > end): # 没有找到的情况 return -1 mid = int((start + end)/2) if(data[mid] < target): start = mid + 1 elif(data[mid] > target): end = mid - 1 else: if(data[mid - 1]!=target or mid == 0): # 注意边界条件:mid = 0 return mid else: end = mid -1 return get_first_index(data, start, end, target) def get_last_index(data, start, end, target): if(start > end): return -1 mid = int((start + end)/2) if(data[mid] < target): start = mid + 1 elif(data[mid] > target): end = mid -1 else: if(data[mid + 1] != target or mid == len(data)): # 注意边界条件:mid = len(data) -1 return mid else: start = mid + 1 return get_last_index(data, start, end, target) def calculate_count(data, target): first = get_first_index(data, 0, len(data), 5) last = get_last_index(data, 0, len(data), 5) print('first:', first) print('last:', last) count = 0 # target重复的个数 if(first == -1 and last == -1): print('The number not found!') else: count = last - first + 1 return count data = [1, 2, 3, 4, 5, 5, 5, 5, 6, 7, 8] print('the count of 5 is :', calculate_count(data, 5))
2. 哈希表查找——时间复杂度O(n)/增加了额外的空间O(1)
优点:能够在O(1)时间查找到某一元素
缺点:增加了额外的空间来实现哈希表
面试题35:在字符串中找出第一个只出现一次的字符
例如:输入字符串'abaccdeff',则输出'b'
def find_first_only(str): list = [0] * 26 # 将字符转换成ASCII值:ord() for char in str: list[ord(char) - 97] += 1 print(list) i = 0 while(list[i] > 1): i += 1 # 将数值转换成字符:chr() return chr(i + 97) str = 'abaccdeff' print(find_first_only(str))
3. 二叉排序树查找
面试题24
面试题27
二、排序
考点:
1. 比较插入排序、冒泡排序、归并排序、快速排序等算法的优劣。(从额外空间消耗、平均时间复杂度、最差时间复杂度等方面)
2. 写快排+归并排序!!
|
排序法 |
平均时间 |
最差情形 |
稳定度 |
额外空间 |
备注 |
|
冒泡 |
O(n2) |
O(n2) |
稳定 |
O(1) |
n小时较好 |
|
交换 |
O(n2) |
O(n2) |
不稳定 |
O(1) |
n小时较好 |
|
选择 |
O(n2) |
O(n2) |
不稳定 |
O(1) |
n小时较好 |
|
插入 |
O(n2) |
O(n2) |
稳定 |
O(1) |
大部分已排序时较好 |
|
基数 |
O(logRB) |
O(logRB) |
稳定 |
O(n) |
B是真数(0-9), R是基数(个十百) |
|
Shell |
O(nlogn) |
O(ns) 1<s<2 |
不稳定 |
O(1) |
s是所选分组 |
|
快速 |
O(nlogn) |
O(n2) |
不稳定 |
O(logn) |
n大时较好 |
|
归并 |
O(nlogn) |
O(nlogn) |
稳定 |
O(n)+O(logn) |
n大时较好 |
|
堆 |
O(nlogn) |
O(nlogn) |
不稳定 |
O(1) |
n大时较好 |
其中,时间复杂度为:
-
O(NlogN):堆排序、归并排序、快排(最好O(NlogN),最坏O(N2))、Shell排序
- O(N2):冒泡、交换、选择、插入排序
- O(logRB):基数排序
稳定的排序:冒泡、插入、基数、归并
不稳定的排序:交换、选择、shell、快排、堆排序
**1. 快速排序
算法思想:
- 选择一个基准值key;
- 通过一次排序,将比这个key小的数字放在它的左边,比这个key大的数字放在它的右边。——称作partition分区
- 通过多次排序,则可以达到整个数列有序 ——递归的qucik_sort
时间复杂度:最优/平均时间:O(nlgn),最差时间复杂度:O(n2)——反向已排序
改进:
- 选择随机数组委枢纽
- 使用左端、右端和中心的中值作为枢纽元
- 每次选取数据集中的中位数做枢纽
代码:
方法一
def quick_sort(list): if(len(list) < 1): return list else: return quick_sort([x for x in list if x < list[0]]) + [x for x in list if x==list[0]] +quick_sort([x for x in list if x > list[0]]) list = quick_sort([2, 3, 4, 2, 1, 6, 0, 19, 3]) print(list)
方法二:
# 找到两个字符串的交集 def qucik_sort(data,start, end): low = start high = end-1 key = data[start] if(low >= high): return data while(low != high): while(low < high and data[high] > key): high -= 1 if(low < high): data[low], data[high] = data[high], data[low] low += 1 while(low < high and data[low] < key): low +=1 if(low < high): data[low], data[high] = data[high], data[low] high -=1 qucik_sort(data, start, low) qucik_sort(data, low+1, end) data = [5, 1, 5, 3, 7, 8, 4, 2, 9] qucik_sort(data, 0, len(data)) print(data)
题目29:找到数组中出现次数超过一半的数字O(n)
思路:首先对数组进行排序,找到数组的中位数——即在数组中出现次数超过一半
- 使用随机快排的思想,随机选择一个数作为key,对他进行一次partition,将比他小的数字放在左边,比它大的数字放在右边。
- 比较key的下标,如果等于(n/2),则它是中位数,即是数组中次数超过一半的数字
- 如果<(n/2),则中位数在它的右边,对右边进行递归partition
- 如果>(n/2),则中位数在它的左边,对左边进行递归partition
2. 归并排序——稳定
原理:就是把两个已经排列好的序列合并为一个序列。
时间复杂度:时间复杂度:O(N*logN)(因为:把数列分成小队列:logN步,每步都是一个合并有序数列的过程,时间复杂度:O(N),所以总的时间复杂度:O(N*logN))。额外空间:O(N+logN)
因为归并排序每次都是在相邻的数据中进行操作,所以归并排序在O(N*logN)的几种排序方法(快速排序,归并排序,希尔排序,堆排序)也是效率比较高的。
具体步骤:(递归)
- 把长度为n的序列分成两个长度为n/2的子序列
- 对这个子序列分别进行归并排序
- 最后把这两个已经排序好的子序列合并
代码:
def merge_sort(list1, list2):
list3 = []
len1 = len(list1)
len2 = len(list2)
#设置一个空列表list3,比较list1和list2,将最小的数插入到list3中
j = 0
for i in range(len1):
while(j < len2 and list2[j] < list1[i]):
list3.append(list2[j])
j += 1
list3.append(list1[i])
# 如果遍历完了list1,list2还有剩余,则依次添加到list3中
if (j < len2):
for k in range(j+1, len2):
list3.append(list2[k])
return list3
list1 = [1, 3 ,5, 10]
list2 = [2, 4, 6, 8, 9, 11, 13, 14]
list = merge_sort(list1, list2)
print(list)
3. 冒泡排序
定义:它遍历整个数列,两两进行比较,如果顺序不同,则进行交换。重复的遍历、交换整个数列,直到没有可交换的元素了,表示已经完成排序。
时间复杂度:最差时间复杂度:O(n2),最优复杂度:O(n),平均复杂度:O(n2),需要辅助空间:O(1)
计算:比较和交换的次数:1+2+....+n-1 = n(n-1)/2
代码:递减顺序
def bubble_sort(list): for i in range(len(list)): for j in range(i): if(list[i] > list[j]): list[i],list[j] = list[j], list[i] j-=1 print(list) print(list) bubble_sort([4, 3, 6, 2, 8, 9, 1, 3])
**4. 堆排序——TopK问题
建堆的过程,堆调整的过程,这些过程的时间复杂度,空间复杂度,以及如何应用在海量数据Top K问题中等等,都是需要重点掌握的。
原理:首先是一个近似完全二叉树,其次满足:对于一个子结点,它的键值或者索引总是小于(或者大于)它的父节点
时间复杂度:最优/最差/平均:O(nlgn),最差时间空间复杂度:O(n)
二叉堆:满足二个特性:
1---父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2---每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
例如:下面一个最小堆(父结点的键值总是<任何一个子结点的键值):
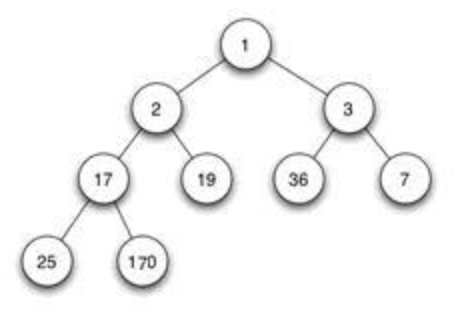
思想(以最大堆为例):
- 对每一个节点 ,首先比较她的两个孩子,找到最大的孩子。然后与它最大的孩子进行比较,如果小于他的孩子,则交换。再以被交换的孩子节点作为起始节点与它的孩子们进行比较。——max_heap
- 对于整个data,从二分点开始,往前调用max_heap最大堆排序进行堆整理。
- 最后从后往前,和list[0]进行交换,再调用max_heap进行堆调整
def max_heap(list, start, end): root = start while(True): child = 2*root+1 # 判断是否有孩子,如果没有孩子,直接break,root就是最大的 if(child > end): break # 如果有左右孩子,那么得到左右孩子中最大的那一个child if(child + 1 <= end and list[child+1] > list[child]): child = child +1 # 如果这个结点,它的孩子们中最大的那个数大于自己,那么进行交换 # 并且交换后,递归的对child的子树们进行堆排序 if (list[child] > list[root]): list[child], list[root] = list[root], list[child] root = child else: break def heap_sort(list): length_list = len(list) # 使用二分查找 first = int(length_list / 2 - 1) # 用最大堆进行堆整理 for start in range(first, -1, -1): max_heap(list, start, length_list-1) # 最后对这个堆进行调整 for end in range(length_list-1, 0, -1): list[end], list[0] = list[0], list[end] max_heap(list, 0, end-1) return list # 测试: list = [10, 23, 1, 5, 4, 14, 16, 6, 35, 15, 46, 31] print(heap_sort(list))
题目:编写算法,从10亿个浮点数当中,选出其中最大的10000个。
建10000个数的小顶堆,然后将10亿个数依次读取,大于堆顶,则替换堆顶,做一次堆调整。结束之后,小顶堆中存放的数即为所求。
题目:设计一个数据结构,其中包含两个函数,1.插入一个数字,2.获得中数。并估计时间复杂度
1. 使用数组存储。
插入数字时,在O(1)时间内将该数字插入到数组最后。
获取中数时,在O(n)时间内找到中数。(选数组的第一个数和其它数比较,并根据比较结果的大小分成两组,那么我们可以确定中数在哪组中。然后对那一组按照同样的方法进一步细分,直到找到中数。)
2. 使用排序数组存储。
插入数字时,在O(logn)时间内找到要插入的位置,在O(n)时间里移动元素并将新数字插入到合适的位置。
获得中数时,在O(1)复杂度内找到中数。
3. 使用大根堆和小根堆存储。
使用大根堆存储较小的一半数字,使用小根堆存储较大的一半数字。
插入数字时,在O(logn)时间内将该数字插入到对应的堆当中,并适当移动根节点以保持两个堆数字相等(或相差1)。
获取中数时,在O(1)时间内找到中数。
5. 插入排序
工作原理:从上到下构造有序的数列,对未排序的数字,通过与前面已排序的数列,从下到上的比较,如果已排序的数字大于该未排序的数列,则已排序的数字向下移,直到找到小于等于未排序的这个数字,则将这个数字插入。
时间复杂度:O(n2),平均时间复杂度:O(n2),额外空间:O(1)
最坏的就是,我们要正序排列,而数组是倒序排列的,所以查找的次数:(n-1)+(n-2)+...+1=n(n-1)/2
这个过程如下图所示:
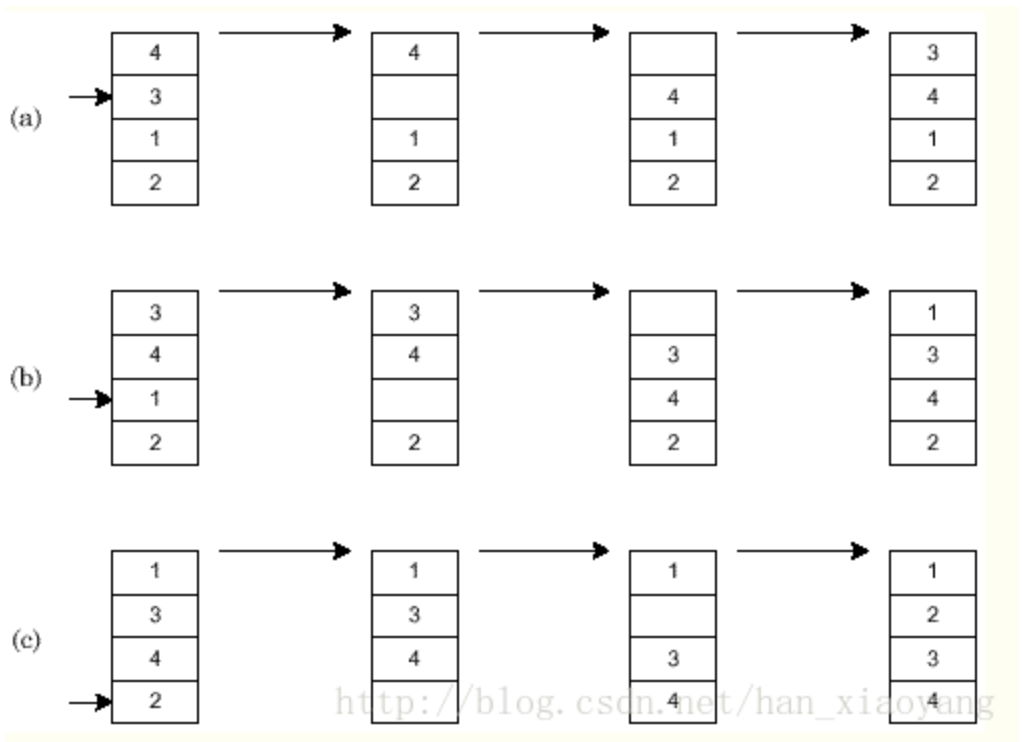
代码实现:
def insert_sort(list): i = 1 while(i<len(list)): j=i-1 insert_value = list[i] while (j>=0 and list[j]>insert_value): list[j+1]=list[j] j=j-1 list[j+1]=insert_value i=i+1 print(list) insert_sort([4, 3, 1, 2])
改进的二分查找插入排序:
未排序的数字在与它之前的已完成排序的数组比较时,按二分查找的思想
题目:链表的插入程序
6.选择排序
时间复杂度:最差/最优/平均 时间复杂度:O(n2)
原理(以递增数列为例):
- 我们可以把数列看作两部分:前面一部分是已排序好的数列,后面一部分是未排序部分;
- 每一次都在后面未排序数列中遍历得到最小的数,与前面已排好序列的末尾数字比较,如果小于这个末尾数字,则交换。
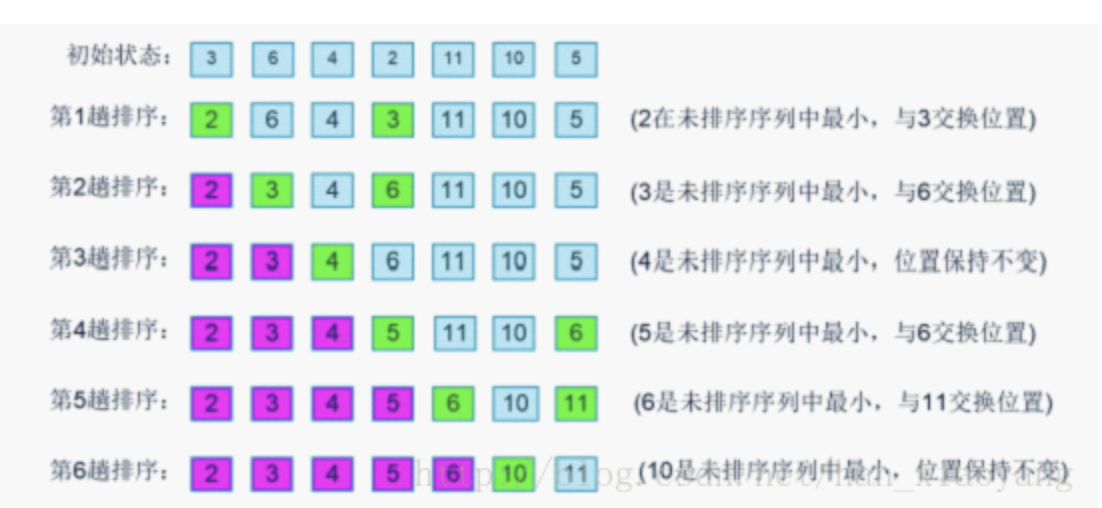
代码:
def selection_sort(list): for i in range(len(list)): min = i # 找到[i+1, ...,len(list)]最小的值 for j in range(i+1, len(list)): if(list[j] < list[min]): min = j if(min != i): list[i], list[min] = list[min], list[i] print(list) selection_sort([3, 6, 4, 2, 11, 10, 5])
7. Shell排序(递减增量排序算法)
1. 时间复杂度:O(n2),Hibbard增量的希尔排序的时间复杂度为O(N^(5/4))
2)算法描述
1、先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。
2、所有距离为d1的倍数的记录放在同一个组中,在各组内进行直接插入排序。
3、取第二个增量d2<d1重复上述的分组和排序,
4、直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。

7. 计数排序——稳定的
原理:使用一个额外的数组C,其中第i个元素对应的是原数列中值为i的数字的个数。然后根据C中的元素将原数列进行排序。(知只能对整数)
时间复杂度:当元素是n个0~k之间的整数时,它的运行时间是 O(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。但是额外空间非常大:O(k)
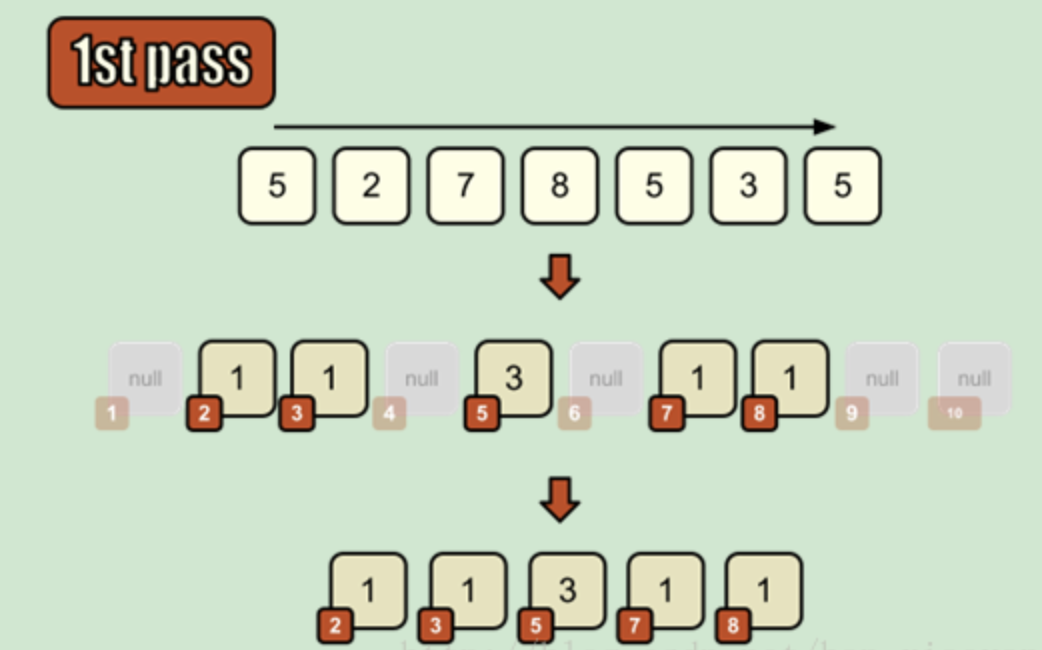
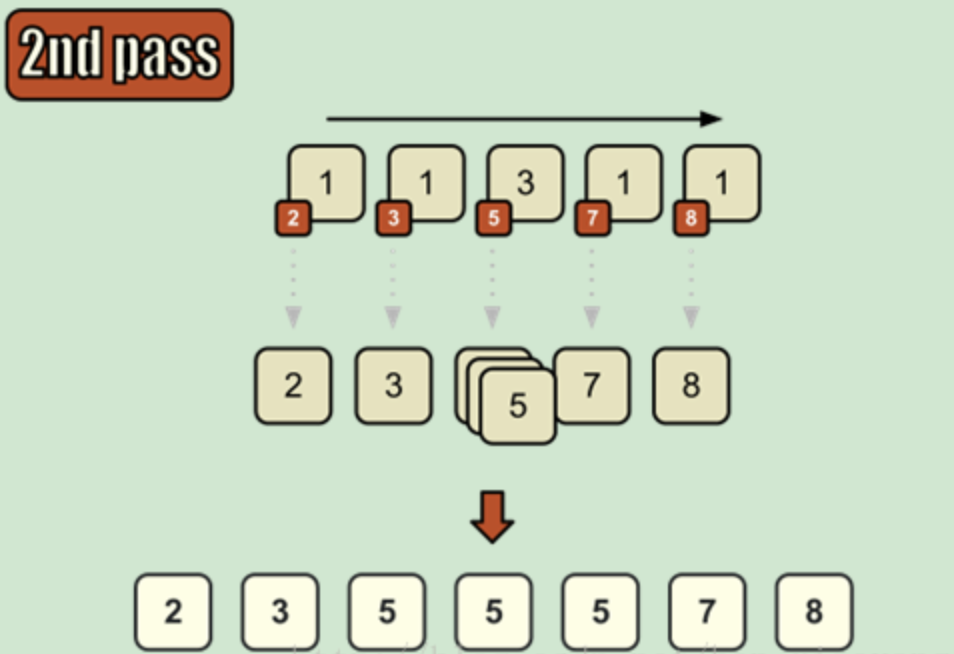
代码实现:
三、字符串
四、树
1. 如何判断是一棵平衡二叉树
某二叉树中,它任意结点的左右子树的深度相差不过1
五、其他
1. 去除列表中重复的元素
1)方法一:list(set(data))
# 方法(一) def delet_same_number(data): return list(set(data))
2)构建字典的方法:
def delet_same_number2(data): # 构建一个字典 dict = {}.fromkeys(data) return dict.keys()
3)列表推导式:
def delet_same_number3(data): list = [] [list.append(i) for i in data if not (i in list)] return list
面试官提到:先排序后删除
面经中题目:
1. 判断一个字符串是否是回文
2. 一个序列先增后减,求峰值
3. 二分查找、堆排序、在字符串中求最长数字子序列的长度、连续子序列的最大和
4. 链表反转
5. 非递归实现二叉树的遍历
6. 字符串相加(大数相加)
7.给一个矩形,由若干小正方形构成,求一共有多少个矩形
8. 最长公共子序列问题
9. 字符串匹配
10. 一个乱序数组排序,想要把正数都放在负数的左边,怎么实现
11. 有一个很大的数据量,想要找出里面最大的100个数,怎么做