hadoop1中MapReduce负责计算和任务调度,在hadoop2中将任务调度抽取为Yarn服务
一、Hdfs
1.1 架构
1.1.1 NameNode
存储文件元数据,如:文件名、目录结构、文件属性(生成时间、副本数、权限)以及每个文件的块列表和所在DataNode
NameNode节点内存主流为128G,存储每个Block元数据150Byte
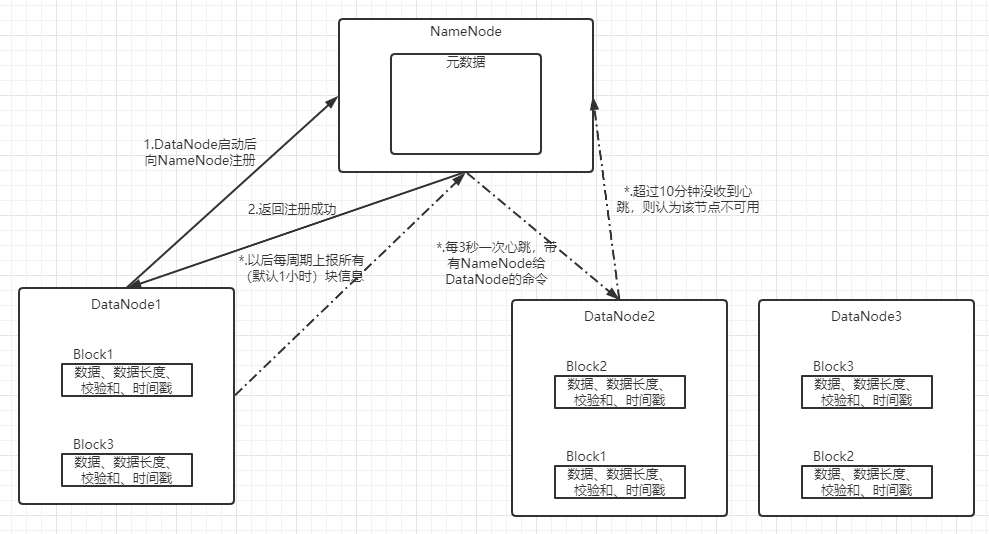
1.1.2 DataNode
在本地文件存储文件块数据(默认128M,公司集群资源多则可以设置为256M),以及块数据的校验和(CRC)
磁盘传输速度影响块大小,块太小增加寻址时间,块太大传输时间大于块开始位置需要时间,处理数据非常慢。
假设寻址时间10ms,磁盘普遍传输速率100MB/s,寻址时间为传输时间的1%时为最佳状态。因此传输时间=10ms/0.01=1s,
而1秒读取的block大小=1s*100MB/s=100MB。所以块默认128M
1.1.3 Secondary NameNode
每隔一段时间生成HDFS元数据快照
1.2 特点
1.2.1优点
多副本(默认3个),副本丢失自动恢复
1.2.3 缺点
数据访问延时高,不适合小文件访问,不支持文件并发修改
Hdfs适合小文件并不是因为小文件会单独占用一个块,相反Hdfs有很多种方式可以将小文件合并为一个大文件,不适合小文件存储的原因是会占用NameNode大量内存空间存储块信息和目录,而且小文件的寻址时间会超过读取时间效率很低
1.3 数据写流程

1.4 数据读流程

1.5 NameNode和SecondaryNameNode工作机制
在NameNode节点上存在FsImage元数据备份文件(元数据启动会都会存储在内存中,落盘为节点宕机恢复),以及Edits操作文件。断电后可以通过FsImage和Edits合并,合成元数据。
但是,长时间追加Edits会导致数据过大,恢复元数据时间过长。因此需要定期合并FsImage和Edits,因为NameNode只有单节点对外访问负载较大,所以定期合并操作交由SecondaryNameNode操作
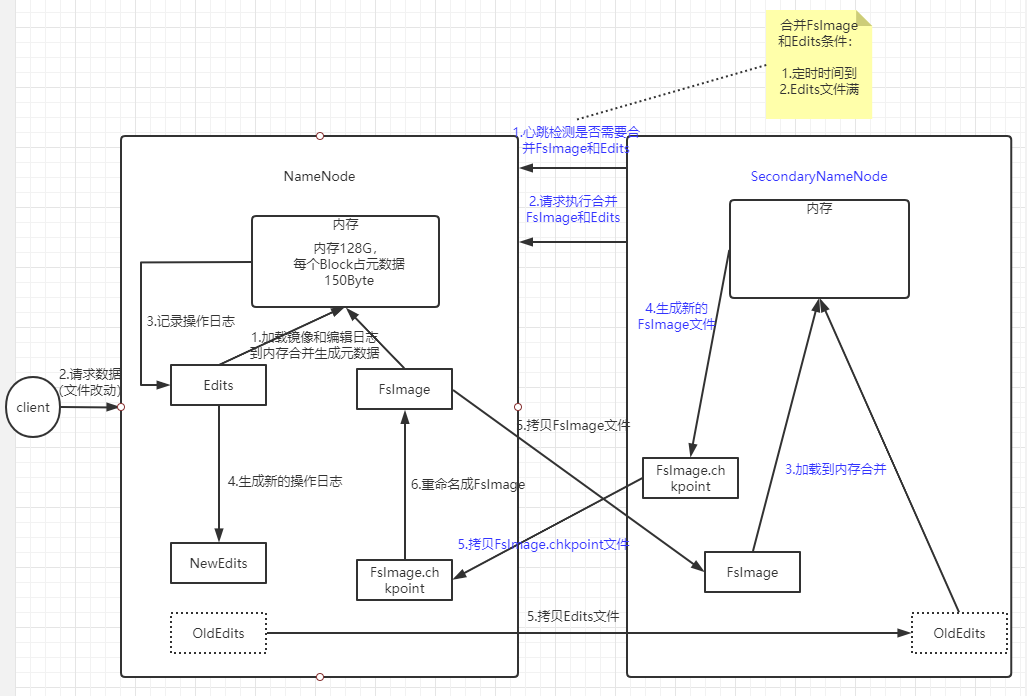
NameNode启动加载FsImage和Edits文件到内存构建集群元数据。
client访问NameNode,先将操作记录到Edits,之后在内存对操作处理。
1.6 集群安全模式
NameNode启动合并FsImage和Edits过程后NameNode开始监听DataNode,这个过程文件NameNode开始和DataNode同步数据,系统处于只读状态就叫做 安全模式 (刚刚格式化的HDFS集群没有任何数据,NameNode不会进入安全模式)。
满足整个文件系统99.9%的块达到最小副本条件(默认值:dfs.replication.min=1),则NameNode启动30秒后退出安全模式。
1.7 DataNode工作机制
二、MapReduce
2.1 特点
2.1.1 优点
1. 增加机器就可以提升计算能力
-
高容错性,机器挂机可以自动将任务转移到了另外一台机器
2.1.2 缺点
1. 输入数据是静态的,不擅长实时计算
-
不能迭代计算
-
中间结果输出到磁盘,大量IO效率低
2.2 常用序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
自定义序列化类实现Writable接口,重写write(DataOutput out)和readFields(DataInput in)接口
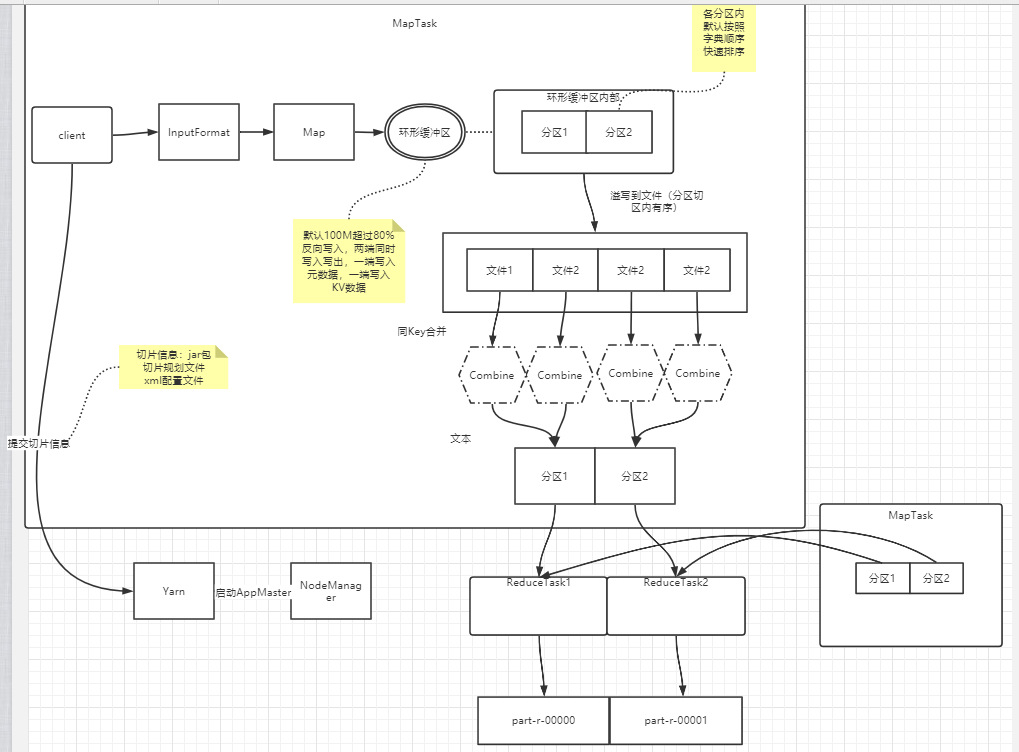
2.3MapReduce运行原理
数据块:物理概念,HDFS把数据分成一块一块(默认128MB一块)
切片:逻辑概念Map函数处理的基本单位,即:切片数决定MapTask数量
分区:一个分区代表输出一个文件的数据
如果切片大小小于块大小,则当前MapTask对块中剩余的数据会分发到其他MapTask造成大量网络传输,故意切片大小一般设置为Block大小。
切片时不考虑整体数据,只是针对每一个文件切片。
MapReduce默认ReduceTask是1,分区规则是哈希分区key.hashCode()%reduceTaskNum(一个分区),设置分区数(job.setNumReduceTasks(4);)的时候要按照分区规则实际的数量设置。
切片数=MapTask数;分区数=ReduceTask数
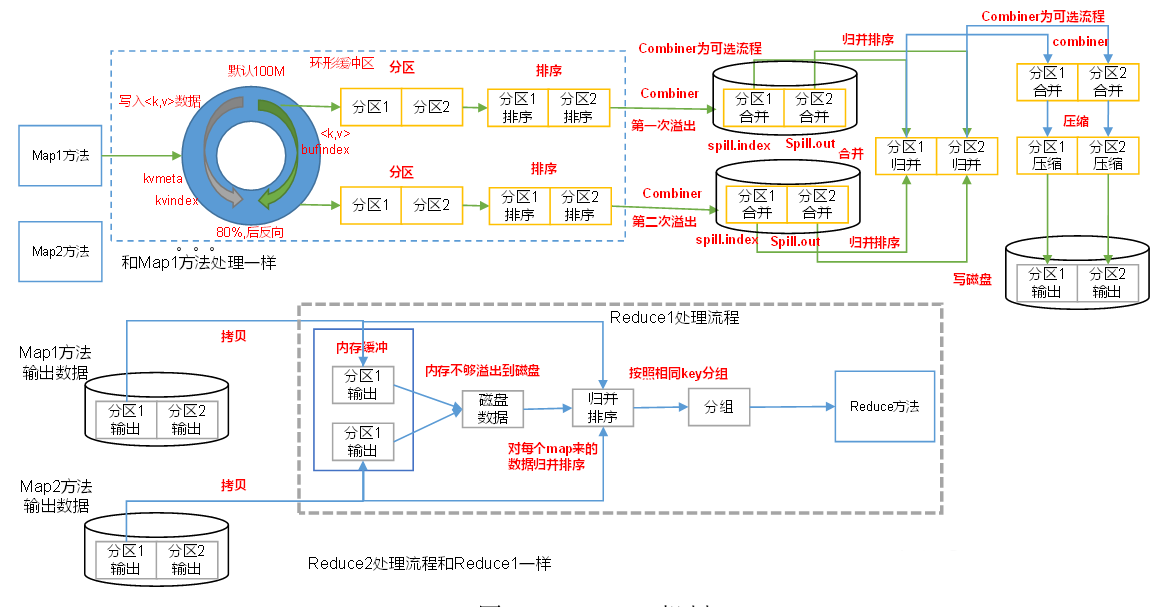
2.4 Combiner机制
Combiner组件继承Reducer,但是运行在MapTask,Combiner意义是对每一个MapTask进行局部汇总,减少到Reducer端的网络传输量
2.5 排序
1. 全排序:最终输出只有一个内部有序的文件,Bean实现WritableComparable接口的compareTo方法。
-
辅助排序(分组排序):对相同Key的数据,运行在ReduceTask,运行在Reduce方法之前。继承WritableComparator类重写compare方法。compare返回为0为同一数据集,进行排序。
2.6 Shuffle机制
2.7 ReduceJoin
ReduceTask阶段进行表连接非常容易出现数据倾斜,因此一般不建议ReduceJoin
1. MapTask阶段为来自不同文件的记录,打标签以区别来自不同文件。然后用连接字段作为key,其余字段和标签作为value。
-
ReduceTask阶段,以连接字段作为key分组完成,只需要在每个分组内区分不同文件的数据进行合并即可。
2.8 MapJoin
不需要ReduceTask阶段(job.setNumReduceTask(0);)。
在驱动类中将一张表设置为缓存数据(job.addCacheFile(new URL(""));),重写Map类的setup方法,将缓存数据的读取到内存中。之后在Map方法中对不断加载的表数据,以及加载到内存中的数据进行合并操作。
2.9 压缩
运算密集的job不建议用压缩,IO密集型job用压缩,主要使用lzo和snappy格式压缩。snappy适合MapTask到ReduceTask的中间数据,或者一个MapReduce到另一个MapReduce的中间数据。
三、Yarn
Yarn是一个资源调度平台,负责为计算框架提供服务器资源。
3.1 架构
2.1.1 ResourceManager(RM)
处理客户端请求,监控NodeManager,启动/监控ApplicationMaster,资源分配调度
2.,1.2 NodeManager
管理单个节点资源,处理ResourceManager命令,处理ApplicationMaster命令
2.1.3 ApplicationMaster
负责数据切分,为程序申请资源,任务监控和容错
2.1.4 Container
资源抽象

3.1 资源调度器
Yarn资源调度有三种:FIFO、Capacity Scheduler、FairScheduler。默认是Capacity Scheduler
-
FIFO:单个队列,按照任务到达时间,先到先服务。
-
Capacity Scheduler:多个队列,每个队列采用FIFO。防止用户独占资源,会对统一用户所占资源量进行限定。
-
FairScheduler:job所需资源与实际获得资源差距叫做 缺额 ,多个队列,同一个队列,缺额越大的job越优先执行。
3.2 任务推测执行
发现低于平均速度的job,为其启用一个备份job。谁先运行完用谁的结果。
推测任务前提条件:
每个Task只能有一个备份任务
当前job已完成的task必须不小于5%